<< Rotation en trois dimensions
Sujets mathématiques\ issus de la 3D graphique >>
Chapitre 9
Primitives géométriques
Triangle man, triangle man.
Triangle man hates particle man.
They have a fight, triangle wins.
Triangle man.
— Particle Man (1990) by They Might Be Giants
Ce chapitre traite des primitives géométriques en général et en particulier.
Section 9.1 présente quelques principes généraux relatifs à la représentation des primitives géométriques.
Les sections 9.2–9.7 couvrent un certain nombre de primitives géométriques importantes spécifiques, y compris des méthodes pour représenter ces primitives ainsi que quelques propriétés et opérations classiques. Chemin faisant, nous présenterons quelques extraits de code C++.
9.1Techniques de représentation
Commençons par un bref aperçu des principales stratégies pour décrire des formes géométriques. Pour toute primitive donnée, une ou plusieurs de ces techniques peuvent être applicables, et différentes techniques sont utiles dans différentes situations.
Nous pouvons décrire un objet sous forme implicite en définissant une fonction booléenne qui est vraie pour tous les points de la primitive et fausse pour tous les autres points. Par exemple, l’équation
Sphère unitaire sous forme implicite
est vraie pour tous les points sur la surface d’une sphère unitaire centrée à l’origine. Les sections coniques sont des exemples classiques de représentations implicites de formes géométriques que vous connaissez peut-être déjà. Une section conique est une forme 2D formée par l’intersection d’un cône avec un plan. Les sections coniques sont le cercle, l’ellipse, la parabole et l’hyperbole, toutes pouvant être décrites sous la forme implicite standard .
Les metaballs [1] sont une méthode implicite pour représenter des formes fluides et organiques. Le volume est défini par une collection de « boules » floues. Chaque boule définit une fonction de densité scalaire tridimensionnelle basée sur la distance depuis le centre de la boule, la distance zéro correspondant à la valeur maximale et les distances plus grandes ayant des valeurs plus faibles. Nous pouvons définir une fonction de densité agrégée pour tout point arbitraire de l’espace en prenant la somme des densités de toutes les boules en ce point. La particularité des metaballs est que le volume de l’objet fluide ou organique est défini comme étant la région où la densité dépasse un certain seuil non nul. En d’autres termes, les boules ont une région « floue » autour d’elles qui s’étend en dehors du volume lorsque la boule est isolée. Lorsque deux ou plusieurs boules se rapprochent, les régions floues interfèrent de manière constructive, causant la matérialisation gracieuse d’un « lien » de volume solide dans la région entre les boules, où aucun solide n’existerait si l’une ou l’autre boule était isolée. L’algorithme des marching cubes [5] est une technique classique pour convertir une forme implicite arbitraire en une description de surface (telle qu’un maillage polygonal).
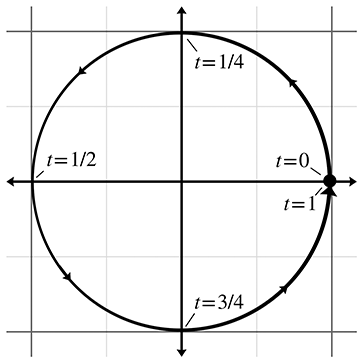
Figure 9.1Cercle paramétrique
Une autre stratégie générale pour décrire des formes est la forme paramétrique. Là encore, la primitive est définie par une fonction, mais au lieu que les coordonnées spatiales soient l’entrée de la fonction, elles en sont la sortie. Commençons par un exemple 2D simple. Nous définissons les deux fonctions suivantes de :
Cercle unitaire sous forme paramétrique
L’argument est connu sous le nom de paramètre et est indépendant du système de coordonnées utilisé. Lorsque varie de 0 à 1, le point trace le contour de la forme que nous sommes en train de décrire — dans cet exemple, un cercle unitaire centré à l’origine (voir la Figure 9.1).
Il est souvent commode de normaliser le paramètre pour qu’il soit dans la plage , bien que nous puissions laisser prendre n’importe quelle plage de valeurs que nous souhaitons. Un autre choix courant est , où est une mesure de la longueur de la primitive.
Lorsque nos fonctions sont exprimées en termes d’un seul paramètre, nous disons que les fonctions sont univariées. Les fonctions univariées tracent une forme 1D : une courbe. (Le Chapitre 13 présente davantage sur les courbes paramétriques.) Il est également possible d’utiliser plus d’un paramètre. Une fonction bivariée accepte deux paramètres, généralement assignés aux variables et . Les fonctions bivariées tracent une surface plutôt qu’une ligne.
Nous avons appelé la dernière méthode de représentation des primitives, faute d’un meilleur terme, les formes directes. Par là, nous entendons toutes les méthodes ad hoc qui capturent les informations les plus importantes et les plus évidentes directement. Par exemple, pour décrire un segment de droite, nous pourrions nommer les deux points d’extrémité. Une sphère est décrite le plus simplement en donnant son centre et son rayon. Les formes directes sont les plus faciles à utiliser directement pour les humains.
Quelle que soit la méthode de représentation, chaque primitive géométrique a un nombre de degrés de liberté inhérent. C’est le nombre minimum de « pièces d’information » nécessaires pour décrire l’entité sans ambiguïté. Il est intéressant de noter que pour la même primitive géométrique, certaines formes de représentation utilisent plus de nombres que d’autres. Cependant, nous constatons que tous les nombres « supplémentaires » sont toujours dus à une redondance dans la paramétrisation de la primitive, qui pourrait être éliminée en supposant la contrainte appropriée, comme un vecteur de longueur unitaire. Par exemple, un cercle dans le plan a trois degrés de liberté : deux pour la position du centre et un pour le rayon . Sous forme paramétrique, ces variables apparaissent directement :
Cercle paramétrique avec centre et rayon arbitraires
Cependant, l’équation générale des sections coniques (la forme implicite) est , qui a quatre coefficients. Une section conique générale peut être reconnue comme un cercle si elle peut être manipulée dans la forme
Cercle implicite avec centre et rayon arbitraires
9.2Droites et rayons
Passons maintenant à certains types spécifiques de primitives. Nous commençons par ce qui est peut-être la plus basique et importante de toutes : le segment linéaire. Faisons connaissance avec les trois types de base de segments linéaires, et clarifions également quelques termes. En géométrie classique, les définitions suivantes sont utilisées :
Une droite s’étend infiniment dans deux directions.
Un segment de droite est une portion finie d’une droite qui a deux extrémités.
Un rayon est la « moitié » d’une droite qui a une origine et s’étend infiniment dans une direction.
En informatique et en géométrie computationnelle, il existe des variations sur ces définitions. Ce livre utilise les définitions classiques pour la droite et le segment de droite. Cependant, la définition du « rayon » est légèrement modifiée :
Un rayon est un segment de droite orienté.
Ainsi, pour nous, un rayon aura une origine et un point d’extrémité. Un rayon définit donc une position, une longueur finie, et (à moins que le rayon n’ait une longueur nulle) une direction. Comme un rayon est simplement un segment de droite où nous avons différencié les deux extrémités, et qu’un rayon peut également être utilisé pour définir une droite infinie, les rayons sont d’une importance fondamentale en géométrie computationnelle et graphique et seront le focus de cette section. Un rayon peut être imaginé comme le résultat du déplacement d’un point dans l’espace au fil du temps ; les rayons sont omniprésents dans les jeux vidéo. Un exemple évident est la stratégie de rendu connue sous le nom de lancer de rayons, qui utilise des rayons éponymes représentant les trajectoires des photons. Pour l’IA, nous traçons des rayons de « ligne de visée » dans l’environnement pour détecter si un ennemi peut voir le joueur. De nombreux outils d’interface utilisateur utilisent le lancer de rayons pour déterminer quel objet se trouve sous le curseur de la souris. Les balles et les lasers sillonnent constamment l’air dans les jeux vidéo, et nous avons besoin de rayons pour déterminer ce qu’ils touchent. La Figure 9.2 compare la droite, le segment de droite et le rayon.

Figure 9.2Droite, segment de droite et rayon
Le reste de cette section examine différentes méthodes pour représenter les droites et les rayons en 2D et 3D. La Section 9.2.1 présente quelques façons simples de représenter un rayon, y compris la forme paramétrique essentielle. La Section 9.2.2 présente quelques façons particulières de définir une droite infinie en 2D. La Section 9.2.3 donne quelques exemples de conversion d’une représentation à une autre.
9.2.1Rayons
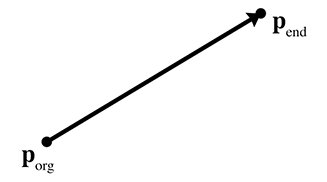
Figure 9.3 Définition d’un rayon à l’aide des points de départ et d’arrivée
La façon la plus évidente de définir un rayon (la « forme directe ») est par deux points, l’origine du rayon et le point d’extrémité du rayon, que nous noterons et (voir la Figure 9.3).
La forme paramétrique du rayon est légèrement différente, et est très importante :
Définition paramétrique d’un rayon en notation vectorielle
Le rayon commence au point . Ainsi, contient des informations sur la position du rayon, tandis que le « vecteur delta » contient sa longueur et sa direction. Nous restreignons le paramètre à la plage normalisée , de sorte que le rayon se termine au point , comme le montre la Figure 9.4.
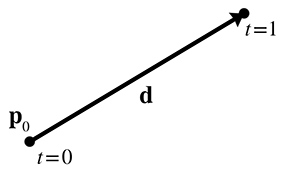
Figure 9.4Définition paramétrique d’un rayon
Nous pouvons également écrire une fonction scalaire séparée pour chaque coordonnée, bien que le format vectoriel soit plus compact et ait également la belle propriété de rendre les équations identiques dans n’importe quelle dimension. Par exemple, un rayon 2D est défini paramétriquement par deux fonctions scalaires,
Définition paramétrique d’un rayon 2D
Une légère variante de l’Équation (9.1) que nous utilisons dans certains des tests d’intersection est d’utiliser un vecteur unitaire et de changer le domaine du paramètre en , où est la longueur du rayon.
9.2.2Représentations 2D spéciales des droites
Examinons maintenant de plus près certaines façons particulières de décrire les droites (infinies). Ces méthodes ne sont applicables qu’en 2D ; en 3D, des techniques similaires à celles-ci sont utilisées pour définir un plan, comme nous le montrons à la Section 9.5. Un rayon 2D a intrinsèquement quatre degrés de liberté ( , , et ), mais une droite infinie n’a que deux degrés de liberté.
La plupart des lecteurs connaissent probablement la forme pente-ordonnée à l’origine, qui est une méthode implicite pour représenter une droite infinie en 2D :
Forme pente-ordonnée à l’origine
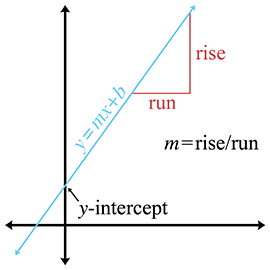
Figure 9.5La pente et l’ordonnée à l’origine d’une droite
Le symbole est celui traditionnellement utilisé pour désigner la pente de la droite, exprimée comme un rapport de montée sur avancement : pour chaque montée unités vers le haut, nous nous déplaçons de avancement unités vers la droite (voir la Figure 9.5). L’ordonnée à l’origine est l’endroit où la droite coupe l’axe , et est la valeur que nous avons notée dans l’Équation (9.2). (Nous rompons avec la tradition en n’utilisant pas la variable traditionnelle, , afin d’éviter une certaine confusion par la suite.) En substituant , il est clair que la droite coupe l’axe en .
La forme pente-ordonnée à l’origine permet de vérifier facilement qu’une droite infinie a bien deux degrés de liberté : un degré pour la rotation et un autre pour la translation. Malheureusement, une droite verticale a une pente infinie et ne peut pas être représentée sous forme pente-ordonnée à l’origine, car la forme implicite d’une droite verticale est . (Les droites horizontales ne posent pas de problème, leur pente est zéro.)
Nous pouvons contourner cette singularité en utilisant la forme implicite légèrement différente
Définition implicite d’une droite infinie en 2D
La plupart des sources utilisent la forme . Cela inverse le signe de par rapport à nos équations. Nous utiliserons la forme de l’Équation (9.3) car elle a moins de termes, et nous estimons également que a une signification plus intuitive géométriquement dans cette forme.
Si nous attribuons le vecteur , nous pouvons écrire l’Équation (9.3) en notation vectorielle comme
Définition implicite de la droite infinie 2D en notation vectorielle
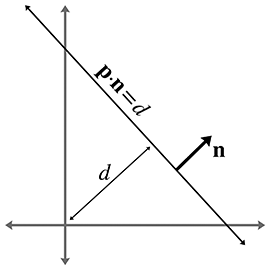
Figure 9.6 Définition d’une droite à l’aide d’un vecteur perpendiculaire et de la distance à l’origine
Comme cette forme a trois degrés de liberté, et que nous avons dit qu’une droite infinie en 2D n’en a que deux, nous savons qu’il y a une redondance. Notez que nous pouvons multiplier les deux membres de l’équation par n’importe quelle constante ; ce faisant, nous sommes libres de choisir la longueur de sans perte de généralité. Il est souvent commode que soit un vecteur unitaire. Cela donne à et des interprétations géométriques intéressantes, comme le montre la Figure 9.6.
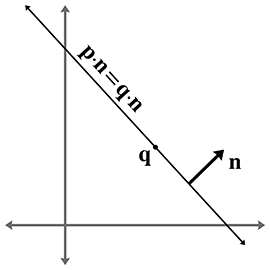
Figure 9.7 Définition d’une droite à l’aide d’un vecteur perpendiculaire et d’un point sur la droite
Le vecteur est le vecteur unitaire orthogonal à la droite, et donne la distance signée de l’origine à la droite. Cette distance est mesurée perpendiculairement à la droite (parallèlement à ). Par distance signée, nous entendons que est positif si la droite est du même côté de l’origine que celui vers lequel pointe la normale. Lorsque augmente, la droite se déplace dans la direction de . C’est du moins le cas lorsque nous mettons du côté droit du signe égal, comme dans l’Équation (9.4). Si nous déplaçons du côté gauche du signe égal et mettons zéro du côté droit, comme dans la forme traditionnelle, alors le signe de est inversé et ces affirmations sont renversées.
Notez que décrit l’« orientation » de la droite, tandis que décrit sa position. Une autre façon de décrire la position de la droite est de donner un point situé sur la droite. Bien sûr, il y a une infinité de points sur la droite, donc n’importe lequel conviendra (voir la Figure 9.7).
Une dernière façon de définir une droite est comme la médiatrice de deux points, auxquels nous attribuons les variables et (voir la Figure 9.8). C’est en réalité l’une des premières définitions d’une droite : l’ensemble de tous les points équidistants de deux points donnés.
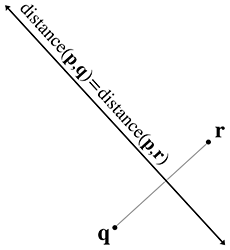
Figure 9.8 Définition d’une droite comme médiatrice d’un segment de droite
9.2.3Conversion entre les représentations
Donnons maintenant quelques exemples de conversion d’un rayon ou d’une droite entre les différentes techniques de représentation. Nous ne couvrirons pas toutes les combinaisons. N’oubliez pas que les techniques que nous avons apprises pour les droites infinies ne sont applicables qu’en 2D.
Pour convertir un rayon défini par deux points en forme paramétrique :
La conversion inverse, de la forme paramétrique à la forme à deux points, est
Étant donné un rayon paramétrique, nous pouvons calculer la droite implicite qui contient ce rayon :
Pour convertir une droite exprimée implicitement en forme pente-ordonnée à l’origine :
Conversion d’une droite exprimée implicitement en forme « normale et distance » :
Conversion d’une normale et d’un point sur la droite en forme normale et distance :
(Cela suppose que est un vecteur unitaire.)
Enfin, pour convertir la forme médiatrice en forme implicite, nous utilisons
9.3Sphères et cercles
Une sphère est un objet 3D défini comme l’ensemble de tous les points situés à une distance fixe d’un point donné. La distance entre le centre de la sphère et un point est connue sous le nom de rayon de la sphère. La représentation directe d’une sphère consiste à décrire son centre et son rayon .
Les sphères apparaissent souvent en géométrie computationnelle et graphique en raison de leur simplicité. Une sphère englobante est souvent utilisée pour un rejet trivial car les équations d’intersection avec une sphère sont simples. Il est également important de noter que la rotation d’une sphère ne modifie pas son étendue. Ainsi, lorsqu’une sphère englobante est utilisée pour un rejet trivial, si le centre de la sphère est l’origine de l’objet, alors l’orientation de l’objet peut être ignorée. Une boîte englobante (voir la Section 9.4) n’a pas cette propriété.
La forme implicite d’une sphère découle directement de sa définition : l’ensemble de tous les points situés à une distance donnée du centre. La forme implicite d’une sphère de centre et de rayon est
Définition implicite d’une sphère en notation vectorielle
où est n’importe quel point sur la surface de la sphère. Pour qu’un point à l’intérieur de la sphère satisfasse l’équation, nous devons changer le « » en « ». Comme l’Équation (9.7) utilise la notation vectorielle, elle fonctionne également en 2D, comme définition implicite d’un cercle. Une autre forme plus courante consiste à développer la notation vectorielle et à mettre les deux membres au carré :
Définitions implicites d’un cercle et d’une sphère
Nous pourrions nous intéresser au diamètre (distance d’un point à un point sur le côté exactement opposé), et à la circonférence (la distance tout autour du cercle) d’un cercle ou d’une sphère. La géométrie élémentaire fournit des formules pour ces quantités, ainsi que pour l’aire d’un cercle, la surface d’une sphère et le volume d’une sphère :
Pour les amateurs de calcul différentiel, il est intéressant de remarquer que la dérivée de l’aire d’un cercle par rapport à est la circonférence, et que la dérivée du volume d’une sphère est la surface.
9.4Boîtes englobantes
Une autre primitive géométrique simple couramment utilisée comme volume englobant est la boîte englobante. Les boîtes englobantes peuvent être alignées sur les axes, ou orientées de manière arbitraire. Les boîtes englobantes alignées sur les axes ont la contrainte que leurs côtés soient perpendiculaires aux axes principaux. L’acronyme AABB est souvent utilisé pour boîte englobante alignée sur les axes (Axially Aligned Bounding Box).
Une AABB 3D est une simple boîte à 6 faces avec chaque face parallèle à l’un des plans cardinaux. La boîte n’est pas nécessairement un cube — la longueur, la largeur et la hauteur de la boîte peuvent chacune être différentes. La Figure 9.9 montre quelques objets 3D simples et leurs boîtes englobantes alignées sur les axes.

Figure 9.9Objets 3D et leurs AABB
Un autre acronyme fréquemment utilisé est OBB, qui signifie boîte englobante orientée (Oriented Bounding Box). Nous ne discutons pas beaucoup des OBB dans cette section, pour deux raisons. Premièrement, les boîtes englobantes alignées sur les axes sont plus simples à créer et à utiliser. Mais plus important encore, vous pouvez penser à une OBB simplement comme une AABB avec une orientation ; chaque boîte englobante est une AABB dans un certain espace de coordonnées ; en fait, n’importe quel espace dont les axes sont perpendiculaires aux côtés de la boîte conviendra. En d’autres termes, la différence entre une AABB et une OBB ne réside pas dans la boîte elle-même, mais dans si vous effectuez des calculs dans un espace de coordonnées aligné avec la boîte englobante.
Par exemple, disons que pour les objets dans notre monde, nous stockons l’AABB de l’objet dans l’espace objet. Lors de l’exécution d’opérations dans l’espace objet, cette boîte englobante est une AABB. Mais lors de l’exécution de calculs dans l’espace monde (ou droit), cette même boîte englobante est une OBB, car elle peut être « en biais » par rapport aux axes du monde.
Bien que cette section se concentre sur les AABB 3D, la plupart des informations peuvent être appliquées de manière directe en 2D en supprimant simplement la troisième dimension.
Les quatre sections suivantes couvrent les propriétés de base des AABB. La Section 9.4.1 introduit la notation que nous utilisons et décrit les options que nous avons pour représenter une AABB. La Section 9.4.2 montre comment calculer l’AABB pour un ensemble de points. La Section 9.4.3 compare les AABB aux sphères englobantes. La Section 9.4.4 montre comment construire une AABB pour une AABB transformée.
9.4.1Représentation des AABB
Introduisons plusieurs propriétés importantes d’une AABB, et la notation que nous utilisons lorsque nous faisons référence à ces valeurs. Les points à l’intérieur d’une AABB satisfont les inégalités
Deux points de coin d’une importance particulière sont
Le point central est donné par
Le « vecteur de taille » est le vecteur de à et contient la largeur, la hauteur et la profondeur de la boîte :
Nous pouvons également faire référence au « vecteur rayon » de la boîte, qui est la moitié du vecteur de taille , et peut être interprété comme le vecteur de à :
Pour définir sans ambiguïté une AABB, il suffit de deux des cinq vecteurs , , , et . Mis à part la paire et , n’importe quelle paire peut être utilisée. Certaines formes de représentation sont plus utiles dans des situations particulières que d’autres. Nous recommandons de représenter une boîte englobante en utilisant et , car en pratique ces valeurs sont nécessaires beaucoup plus fréquemment que , et . Et, bien sûr, calculer l’un de ces trois vecteurs à partir de et est très rapide. En C, une AABB pourrait être représentée en utilisant une struct comme dans le Listing 9.1.
struct AABB3 {
Vector3 min;
Vector3 max;
};9.4.2Calcul des AABB
void AABB3::empty() {
min.x = min.y = min.z = FLT_MAX;
max.x = max.y = max.z = -FLT_MAX;
}
void AABB3::add(const Vector3 &p) {
if (p.x < min.x) min.x = p.x;
if (p.x > max.x) max.x = p.x;
if (p.y < min.x) min.y = p.y;
if (p.y > max.x) max.y = p.y;
if (p.z < min.x) min.z = p.z;
if (p.z > max.x) max.z = p.z;
}Calculer une AABB pour un ensemble de points est un processus simple. Nous réinitialisons d’abord les valeurs minimales et maximales à « l’infini », ou ce qui est effectivement plus grand que tout nombre que nous rencontrerons en pratique. Ensuite, nous parcourons la liste des points en élargissant notre boîte si nécessaire pour contenir chaque point.
Une classe AABB définit souvent deux fonctions pour aider à cela. La première fonction « vide » l’AABB. L’autre fonction ajoute un seul point dans l’AABB en l’élargissant si nécessaire pour contenir le point. Le Listing 9.2 montre un tel code.
Maintenant, pour créer une boîte englobante à partir d’un ensemble de points, nous pourrions utiliser le code suivant :
// Notre liste de points
const int N;
Vector3 list[N];
// D'abord, vider la boîte
AABB3 box;
box.empty();
// Ajouter chaque point dans la boîte
for (int i = 0 ; i < N ; ++i) {
box.add(list[i]);
}9.4.3AABB versus sphères englobantes
Dans de nombreux cas, nous avons le choix entre utiliser une AABB ou une sphère englobante. Les AABB offrent deux avantages principaux par rapport aux sphères englobantes.
Le premier avantage des AABB par rapport aux sphères englobantes est que le calcul de l’AABB optimale pour un ensemble de points est facile à programmer et peut être exécuté en temps linéaire. Le calcul de la sphère englobante optimale est un problème beaucoup plus difficile. (O’Rourke [6] et Lengyel [4] décrivent des algorithmes pour calculer les sphères englobantes.)
Deuxièmement, pour de nombreux objets qui se présentent en pratique, une AABB fournit un volume englobant plus serré, et donc un meilleur rejet trivial. Bien sûr, pour certains objets, la sphère englobante est meilleure. (Imaginez un objet qui est lui-même une sphère !) Dans le pire des cas, une AABB aura un volume juste inférieur à deux fois le volume de la sphère, mais lorsqu’une sphère est mauvaise, elle peut être vraiment mauvaise. Considérez la sphère englobante et l’AABB d’un poteau téléphonique, par exemple.
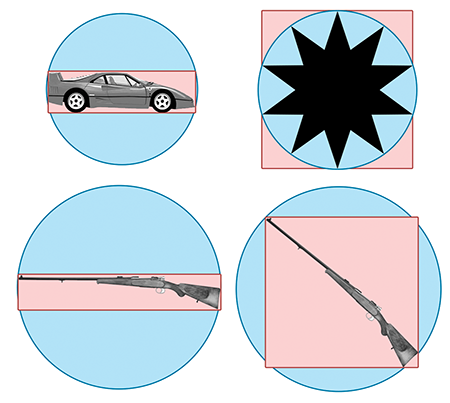
Figure 9.10 L’AABB et la sphère englobante pour divers objets
Le problème fondamental avec une sphère est qu’il n’y a qu’un seul degré de liberté dans sa forme — le rayon de la sphère. Une AABB a trois degrés de liberté — la longueur, la largeur et la hauteur. Ainsi, elle peut généralement s’adapter mieux aux objets de formes différentes. Pour la plupart des objets de la Figure 9.10, l’AABB est plus petite que la sphère englobante. L’exception est l’étoile dans le coin supérieur droit, où la sphère englobante est légèrement plus petite que l’AABB. Notez que l’AABB est très sensible à l’orientation de l’objet, comme le montrent les AABB pour les deux fusils en bas. Dans chaque cas, la taille du fusil est la même, et seule l’orientation est différente. Notez également que les sphères englobantes sont de la même taille car les sphères englobantes ne sont pas sensibles à l’orientation de l’objet. Lorsque les objets sont libres de tourner, une partie de l’avantage des AABB peut être érodée. Il y a un compromis inhérent entre un volume plus serré (OBB) et une représentation compacte et rapide (sphères englobantes). La primitive englobante la plus adaptée dépendra fortement de l’application.
9.4.4Transformation des AABB
Parfois, nous devons transformer une AABB d’un espace de coordonnées à un autre. Par exemple, supposons que nous ayons l’AABB dans l’espace objet (ce qui, du point de vue de l’espace monde, est essentiellement la même chose qu’une OBB ; voir Section 9.4) et que nous voulions obtenir une AABB dans l’espace monde. Bien sûr, en théorie, nous pourrions calculer une AABB dans l’espace monde de l’objet lui-même. Cependant, nous supposons que la description de la forme de l’objet (peut-être un maillage de triangles avec un millier de sommets) est plus complexe que l’AABB que nous avons déjà calculée dans l’espace objet. Donc pour obtenir une AABB dans l’espace monde, nous transformerons l’AABB de l’espace objet.
Ce que nous obtenons comme résultat n’est pas nécessairement aligné sur les axes (si l’objet est tourné), et n’est pas nécessairement une boîte (si l’objet est cisaillé). Cependant, calculer une AABB pour l’« AABB transformée » (nous devrions peut-être l’appeler une NNAABNNB — une « boîte pas nécessairement alignée sur les axes et pas nécessairement une boîte ») est plus rapide que de calculer une nouvelle AABB pour tous sauf les objets transformés les plus simples, car les AABB n’ont que huit sommets.
Pour calculer une AABB pour une AABB transformée, il ne suffit pas de simplement transformer le et le originaux. Cela pourrait résulter en une boîte englobante erronée, par exemple, si . Pour calculer une nouvelle AABB, nous devons transformer les huit points de coin, puis former une AABB à partir de ces huit points transformés.
Selon la transformation, cela résulte généralement en une boîte englobante plus grande que la boîte englobante originale. Par exemple, en 2D, une rotation de 45 degrés augmentera considérablement la taille de la boîte englobante (voir la Figure 9.11).
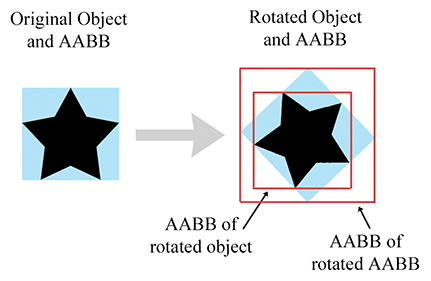
Figure 9.11L’AABB d’une boîte transformée
Comparez la taille de l’AABB originale dans la Figure 9.11 (la boîte bleue), avec la nouvelle AABB (la plus grande boîte rouge à droite) qui a été calculée uniquement à partir de l’AABB pivotée. La nouvelle AABB est presque deux fois plus grande. Notez que si nous étions capables de calculer une AABB à partir de l’objet pivoté plutôt que de l’AABB pivotée, elle serait de la même taille que l’AABB originale environ.
Il s’avère que la structure d’une AABB peut être exploitée pour accélérer la génération de la nouvelle AABB, il n’est donc pas nécessaire de transformer réellement les huit points de coin et de construire une nouvelle AABB à partir de ces points.
Examinons rapidement ce qui se passe lorsque nous transformons un point 3D par une matrice (voir la Section 4.1.7 si vous avez oublié comment multiplier un vecteur par une matrice) :
Supposons que la boîte englobante originale soit dans , , , etc., et que la nouvelle boîte englobante sera calculée dans , , , etc. Examinons comment nous pourrions calculer plus rapidement comme exemple. En d’autres termes, nous souhaitons trouver la valeur minimale de
où est l’un des huit points de coin originaux. Notre tâche est de déterminer lequel de ces points de coin aurait la plus petite valeur de après la transformation. L’astuce pour minimiser toute la somme est de minimiser chacun des trois produits individuellement. Regardons le premier produit, . Nous devons décider lequel de ou substituer pour afin de minimiser le produit. Évidemment, si , alors le plus petit des deux, , donnera le plus petit produit. À l’inverse, si , alors donne le plus petit produit. Commodément, quel que soit ou que nous utilisons pour calculer , nous utilisons l’autre valeur pour calculer . Nous appliquons ensuite ce processus pour chacun des neuf éléments de la matrice.
Cette technique est illustrée dans le Listing 9.4. La classe Matrix4x3 est une matrice de transformation , qui peut représenter toute transformation affine. (C’est une matrice qui agit sur des vecteurs-ligne, où la colonne la plus à droite est supposée être .)
void AABB3::setToTransformedBox(const AABB3 &box, const Matrix4x3 &m) {
// Commencer avec la dernière ligne de la matrice, qui est la partie de
// translation, c.-à-d. la position de l'origine après la transformation.
min = max = getTranslation(m);
//
// Examiner chacun des 9 éléments de la matrice
// et calculer la nouvelle AABB
//
if (m.m11 > 0.0f) {
min.x += m.m11 * box.min.x; max.x += m.m11 * box.max.x;
} else {
min.x += m.m11 * box.max.x; max.x += m.m11 * box.min.x;
}
if (m.m12 > 0.0f) {
min.y += m.m12 * box.min.x; max.y += m.m12 * box.max.x;
} else {
min.y += m.m12 * box.max.x; max.y += m.m12 * box.min.x;
}
if (m.m13 > 0.0f) {
min.z += m.m13 * box.min.x; max.z += m.m13 * box.max.x;
} else {
min.z += m.m13 * box.max.x; max.z += m.m13 * box.min.x;
}
if (m.m21 > 0.0f) {
min.x += m.m21 * box.min.y; max.x += m.m21 * box.max.y;
} else {
min.x += m.m21 * box.max.y; max.x += m.m21 * box.min.y;
}
if (m.m22 > 0.0f) {
min.y += m.m22 * box.min.y; max.y += m.m22 * box.max.y;
} else {
min.y += m.m22 * box.max.y; max.y += m.m22 * box.min.y;
}
if (m.m23 > 0.0f) {
min.z += m.m23 * box.min.y; max.z += m.m23 * box.max.y;
} else {
min.z += m.m23 * box.max.y; max.z += m.m23 * box.min.y;
}
if (m.m31 > 0.0f) {
min.x += m.m31 * box.min.z; max.x += m.m31 * box.max.z;
} else {
min.x += m.m31 * box.max.z; max.x += m.m31 * box.min.z;
}
if (m.m32 > 0.0f) {
min.y += m.m32 * box.min.z; max.y += m.m32 * box.max.z;
} else {
min.y += m.m32 * box.max.z; max.y += m.m32 * box.min.z;
}
if (m.m33 > 0.0f) {
min.z += m.m33 * box.min.z; max.z += m.m33 * box.max.z;
} else {
min.z += m.m33 * box.max.z; max.z += m.m33 * box.min.z;
}
}9.5Plans
Un plan est un sous-espace 2D plat de la 3D. Les plans sont des outils extrêmement courants dans les jeux vidéo, et les concepts de cette section sont particulièrement utiles. La définition d’un plan qu’Euclide reconnaîtrait probablement est similaire à la définition par médiatrice d’une droite infinie en 2D : l’ensemble de tous les points équidistants de deux points donnés. Cette similitude de définitions fait allusion au fait que les plans en 3D partagent de nombreuses propriétés avec les droites infinies en 2D. Par exemple, tous deux subdivisent l’espace en deux « demi-espaces ».
Cette section couvre les propriétés fondamentales des plans. La Section 9.5.1 montre comment définir un plan implicitement avec l’équation du plan. La Section 9.5.2 montre comment trois points peuvent être utilisés pour définir un plan. La Section 9.5.3 décrit comment trouver le plan « de meilleur ajustement » pour un ensemble de points qui peuvent ne pas être exactement coplanaires. La Section 9.5.4 décrit comment calculer la distance d’un point à un plan.
9.5.1L’équation du plan : une définition implicite d’un plan
Nous pouvons représenter des plans en utilisant des techniques similaires à celles que nous avons utilisées pour décrire les droites infinies 2D à la Section 9.2.2. La forme implicite d’un plan est donnée par tous les points qui satisfont l’équation du plan :
L’équation du plan
Notez que dans la forme vectorielle, . Une fois que nous connaissons , nous pouvons calculer à partir de n’importe quel point connu pour être dans le plan.
La plupart des sources donnent l’équation du plan sous la forme . Cela a pour effet d’inverser le signe de . Nos commentaires à la Section 9.2.2 expliquant notre préférence de mettre du côté gauche du signe égal s’appliquent également ici : notre expérience est que cette forme résulte en moins de termes et de signes moins et en une interprétation géométrique plus intuitive pour .
Le vecteur est appelé la normale du plan car il est perpendiculaire (normal) au plan. Bien que soit souvent normalisé à une longueur unitaire, ce n’est pas strictement nécessaire. Nous utilisons un chapeau ( ) lorsque nous supposons une longueur unitaire. La normale détermine l’orientation du plan ; définit sa position. Plus précisément, elle détermine la distance signée au plan depuis l’origine, mesurée dans la direction de la normale. Augmenter fait glisser le plan vers l’avant, dans la direction de la normale. Si , l’origine est du côté arrière du plan, et si , l’origine est du côté avant. (Cela suppose que nous mettons du côté droit du signe égal, comme dans l’Équation (9.10). La forme homogène standard avec à gauche a les conventions de signe opposées.)
Vérifions que est perpendiculaire au plan. Supposons que et sont des points arbitraires dans le plan, et satisfont donc l’équation du plan. En substituant et dans l’Équation (9.10), nous obtenons
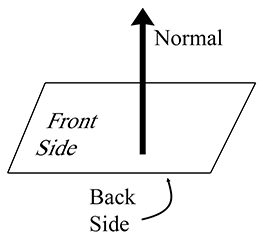
Figure 9.12 Les côtés avant et arrière d’un plan
L’implication géométrique de l’Équation (9.11) est que est perpendiculaire au vecteur de à (voir la Section 2.11). Cela est vrai pour tous points et dans le plan, et donc est perpendiculaire à tout vecteur dans le plan.
Nous considérons souvent un plan comme ayant un côté « avant » et un côté « arrière ». En général, le côté avant du plan est la direction dans laquelle pointe ; c.-à-d. lorsque nous regardons depuis la tête de vers sa queue, nous regardons le côté avant du plan (voir la Figure 9.12).
Comme mentionné précédemment, il est souvent utile de restreindre à avoir une longueur unitaire. Nous pouvons le faire sans perte de généralité, car nous pouvons multiplier toute l’équation du plan par n’importe quelle constante.
9.5.2Définition d’un plan à l’aide de trois points
Une autre façon de définir un plan est de donner trois points non colinéaires qui se trouvent dans le plan. Les points colinéaires (points sur une ligne droite) ne fonctionneront pas car il y aurait une infinité de plans contenant cette droite, et il n’y aurait aucun moyen de dire quel plan nous voulions.
Calculons et à partir de trois points , et connus pour être dans le plan. Tout d’abord, nous devons calculer . Dans quelle direction pointera-t-il ? La façon standard de faire cela dans un système de coordonnées main gauche est de supposer que , et sont listés dans le sens des aiguilles d’une montre, lorsqu’on les voit depuis le côté avant du plan, comme illustré à la Figure 9.13. (Dans un système de coordonnées main droite, nous supposons généralement que les points sont listés dans le sens inverse des aiguilles d’une montre. Avec ces conventions, les équations sont les mêmes quel que soit le système de coordonnées utilisé.)
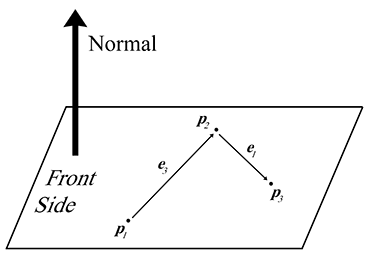
Figure 9.13 Calcul d’une normale de plan à partir de trois points dans le plan
Nous allons construire deux vecteurs selon l’ordre dans le sens des aiguilles d’une montre. La notation signifie vecteur « arête », car ces équations apparaissent couramment lors du calcul de l’équation du plan pour un triangle. (L’indexation peut sembler bizarre, mais soyez patient — c’est l’indexation que nous utiliserons à la Section 9.6.1 où les triangles sont discutés plus en détail.) Le produit vectoriel de ces deux vecteurs donne le vecteur perpendiculaire , mais ce vecteur n’est pas nécessairement de longueur unitaire. Comme mentionné précédemment, nous normalisons généralement . Tout cela est résumé succinctement par
La normale d’un plan contenant trois points
Notez que si les points sont colinéaires, alors et seront parallèles, et donc le produit vectoriel sera , qui ne peut pas être normalisé. Cette singularité mathématique coïncide avec la singularité physique que les points colinéaires ne définissent pas de manière non ambiguë un plan.
Maintenant que nous connaissons , il ne reste plus qu’à calculer . Cela se fait facilement en prenant le produit scalaire de l’un des points et de .
9.5.3Plan de « meilleur ajustement » pour plus de trois points
Parfois, nous pouvons souhaiter calculer l’équation du plan pour un ensemble de plus de trois points. L’exemple le plus courant d’un tel ensemble de points est les sommets d’un polygone. Dans ce cas, les sommets sont supposés être énumérés dans le sens des aiguilles d’une montre autour du polygone. (L’ordre est important car c’est ainsi que nous décidons quel côté est l’avant et quel est l’arrière, ce qui détermine à son tour dans quelle direction pointera notre normale.)
Une solution naïve est de sélectionner arbitrairement trois points consécutifs et de calculer l’équation du plan à partir de ces trois points. Cependant, les trois points que nous choisissons pourraient être colinéaires, ou presque colinéaires, ce qui est presque aussi mauvais car c’est numériquement inexact. Ou peut-être que le polygone est concave et que les trois points que nous avons choisis sont un point de concavité et forment donc un virage dans le sens inverse des aiguilles d’une montre (ce qui donnerait une normale pointant dans la mauvaise direction). Ou les sommets du polygone peuvent ne pas être coplanaires, ce qui peut arriver en raison d’imprécisions numériques ou de la méthode utilisée pour générer le polygone. Ce que nous voulons vraiment, c’est un moyen de calculer le plan de « meilleur ajustement » pour un ensemble de points qui prend en compte tous les points. Étant donné points,
le vecteur perpendiculaire de meilleur ajustement est donné par
Calcul de la normale du plan de meilleur ajustement à partir de points
Ce vecteur doit ensuite être normalisé si nous souhaitons imposer la restriction que soit de longueur unitaire.
Nous pouvons exprimer l’Équation (9.13) de manière concise en utilisant la notation de sommation. En adoptant un schéma d’indexation circulaire tel que , nous pouvons écrire
Le Listing 9.5 illustre comment nous pourrions calculer la normale du plan de meilleur ajustement pour un ensemble de points.
Vector3 computeBestFitNormal(const Vector3 v[], int n) {
// Mettre à zéro la somme
Vector3 result = kZeroVector;
// Commencer avec le sommet « précédent » comme dernier.
// Cela évite une instruction if dans la boucle
const Vector3 *p = &v[n-1];
// Itérer à travers les sommets
for (int i = 0 ; i < n ; ++i) {
// Obtenir un raccourci vers le sommet « actuel »
const Vector3 *c = &v[i];
// Ajouter les produits des vecteurs d'arêtes de manière appropriée
result.x += (p->z + c->z) * (p->y - c->y);
result.y += (p->x + c->x) * (p->z - c->z);
result.z += (p->y + c->y) * (p->x - c->x);
// Sommet suivant, s.v.p.
p = c;
}
// Normaliser le résultat et le retourner
result.normalize();
return result;
}La valeur de meilleur ajustement peut être calculée comme la moyenne des valeurs pour chaque point :
Calcul de la valeur du plan de meilleur ajustement
9.5.4Distance d’un point à un plan
Il arrive souvent que nous ayons un plan et un point qui n’est pas dans le plan, et que nous voulions calculer la distance du plan à , ou au moins classifier comme étant du côté avant ou arrière du plan. Pour ce faire, nous imaginons le point qui se trouve dans le plan et est le point le plus proche du plan par rapport à . Clairement, le vecteur de à est perpendiculaire au plan, et est donc de la forme , comme le montre la Figure 9.14.
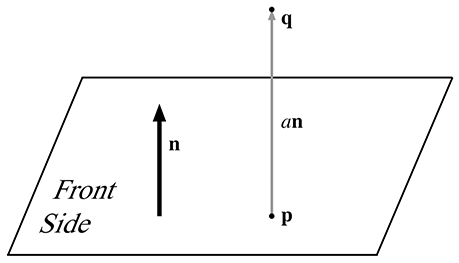
Figure 9.14 Calcul de la distance entre un point et un plan
Si nous supposons que la normale du plan est un vecteur unitaire, alors la distance de à (et donc la distance du plan à ) est simplement . C’est une distance signée, ce qui signifie qu’elle sera négative lorsque est du côté arrière du plan. Ce qui est surprenant, c’est que nous pouvons calculer sans connaître la position de . Nous revenons à notre définition originale de et effectuons ensuite quelques opérations vectorielles pour éliminer :
Calcul de la distance signée d’un plan à un point 3D arbitraire
9.6Triangles
Les triangles sont d’une importance fondamentale en modélisation et graphique. La surface d’un objet 3D complexe, comme une voiture ou un corps humain, est approximée avec de nombreux triangles. Un tel groupe de triangles connectés forme un maillage de triangles, qui est le sujet de la Section 10.4. Mais avant de pouvoir apprendre à manipuler de nombreux triangles, nous devons d’abord apprendre à manipuler un seul triangle.
Cette section couvre les propriétés fondamentales des triangles. La Section 9.6.1 introduit quelques notations et propriétés de base des triangles. La Section 9.6.2 répertorie plusieurs méthodes pour calculer l’aire d’un triangle en 2D ou en 3D. La Section 9.6.3 présente l’espace barycentrique. La Section 9.6.5 présente quelques points sur un triangle qui ont une signification géométrique particulière.
9.6.1Notation
Un triangle est défini en listant ses trois sommets. L’ordre dans lequel ces points sont listés est important. Dans un système de coordonnées main gauche, nous énumérons généralement les points dans le sens des aiguilles d’une montre lorsqu’on les voit depuis le côté avant du triangle. Nous désignerons les trois sommets par , et .
Un triangle se trouve dans un plan, et l’équation de ce plan (la normale et la distance à l’origine ) est importante dans un certain nombre d’applications. Nous venons de discuter des plans, notamment de la façon de calculer l’équation du plan à partir de trois points, à la Section 9.5.2.
Nommons les angles intérieurs, les vecteurs d’arêtes dans le sens des aiguilles d’une montre, et les longueurs des côtés comme le montre la Figure 9.15.
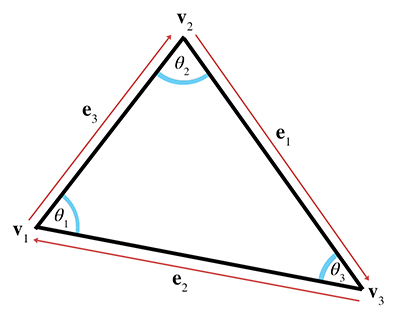
Figure 9.15Étiquetage des triangles
Soit la longueur de . Notez que et sont opposés à , le sommet avec l’index correspondant, et sont donnés par
Notation pour les vecteurs d’arêtes et les longueurs
Par exemple, écrivons la loi des sinus et la loi des cosinus en utilisant cette notation :
Loi des sinus
Loi des cosinus
Le périmètre du triangle est souvent une valeur importante, et est calculé trivialement en additionnant les trois côtés :
Périmètre d’un triangle
9.6.2Aire d’un triangle
Cette section explore plusieurs techniques pour calculer l’aire d’un triangle. La méthode la plus connue est de calculer l’aire à partir de la base et de la hauteur (aussi connue sous le nom d’altitude). Examinez le parallélogramme et le triangle inclus dans la Figure 9.16.
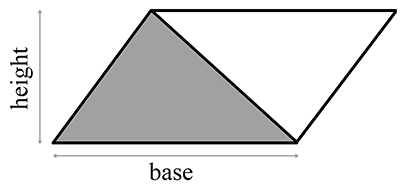
Figure 9.16 Un triangle inclus dans un parallélogramme
D’après la géométrie classique, nous savons que l’aire d’un parallélogramme est égale au produit de la base et de la hauteur. (Voir la Section 2.12.2 pour une explication de pourquoi c’est vrai.) Comme le triangle occupe exactement la moitié de cette aire, l’aire d’un triangle est
Aire d’un triangle
Si l’altitude n’est pas connue, alors la formule de Héron peut être utilisée, qui ne nécessite que les longueurs des trois côtés. Soit égal à la moitié du périmètre (aussi connu sous le nom de demi-périmètre). Alors l’aire est donnée par
Formule de Héron pour l’aire d’un triangle
La formule de Héron est particulièrement intéressante en raison de la facilité avec laquelle elle peut être appliquée en 3D.
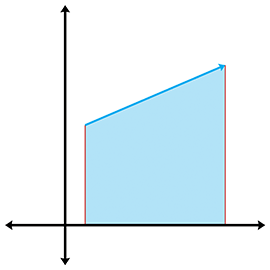
Figure 9.17 L’aire « sous » un vecteur d’arête
Souvent, l’altitude ou les longueurs des côtés ne sont pas facilement disponibles et tout ce que nous avons, ce sont les coordonnées cartésiennes des sommets. (Bien sûr, nous pourrions toujours calculer les longueurs des côtés à partir des coordonnées, mais il y a des situations pour lesquelles nous souhaitons éviter ce calcul relativement coûteux.) Voyons si nous pouvons calculer l’aire d’un triangle à partir des coordonnées des sommets seules.
Attaquons d’abord ce problème en 2D. L’idée de base est de calculer, pour chacune des trois arêtes du triangle, l’aire signée du trapèze délimité en haut par l’arête et en bas par l’axe , comme le montre la Figure 9.17. Par « aire signée », nous voulons dire que l’aire est positive si l’arête pointe de gauche à droite, et négative si l’arête pointe de droite à gauche. Notez que quelle que soit l’orientation du triangle, il y aura toujours au moins une arête positive et au moins une arête négative. Une arête verticale aura une aire nulle. Les formules pour les aires sous chaque arête sont
En additionnant les aires signées des trois trapèzes, nous obtenons l’aire du triangle lui-même. En fait, la même idée peut être utilisée pour calculer l’aire d’un polygone avec n’importe quel nombre de côtés.
Nous supposons un ordre dans le sens des aiguilles d’une montre des sommets autour du triangle. Énumérer les sommets dans l’ordre inverse inverse le signe de l’aire. Avec ces considérations à l’esprit, nous additionnons les aires des trapèzes pour calculer l’aire signée du triangle :
Nous pouvons en réalité simplifier cela encore un peu. L’idée de base est de réaliser que nous pouvons translater le triangle sans affecter l’aire. Nous faisons le choix arbitraire de décaler le triangle verticalement, en soustrayant de chacune des coordonnées (au cas où vous vous demandiez si l’astuce de sommation des trapèzes fonctionne si une partie du triangle s’étend sous l’axe , ce décalage montre correctement que c’est le cas) :
Calcul de l’aire d’un triangle 2D à partir des coordonnées des sommets
En 3D, nous pouvons utiliser le produit vectoriel pour calculer l’aire d’un triangle. Rappelons de la Section 2.12.2 que la magnitude du produit vectoriel de deux vecteurs et est égale à l’aire du parallélogramme formé sur deux côtés par et . Comme l’aire d’un triangle est la moitié de l’aire du parallélogramme enclosant, nous avons une façon simple de calculer l’aire du triangle. Étant donné deux vecteurs d’arêtes du triangle, et , l’aire du triangle est donnée par
Notez que si nous étendons un triangle 2D en 3D en supposant , alors l’Équation (9.15) et l’Équation (9.16) sont équivalentes.
9.6.3Espace barycentrique
Même si nous utilisons certainement des triangles en 3D, la surface d’un triangle se trouve dans un plan et est intrinsèquement un objet 2D. Se déplacer sur la surface d’un triangle orienté arbitrairement en 3D est quelque peu délicat. Il serait agréable d’avoir un espace de coordonnées lié à la surface du triangle et indépendant de l’espace 3D dans lequel le triangle « vit ». L’espace barycentrique est justement un tel espace de coordonnées. De nombreux problèmes pratiques qui se posent lors de la création de jeux vidéo, comme l’interpolation et l’intersection, peuvent être résolus en utilisant les coordonnées barycentriques. Nous introduisons les coordonnées barycentriques dans le contexte des triangles ici, mais elles ont une applicabilité large. En fait, nous les rencontrons à nouveau sous une forme légèrement plus générale dans le contexte des courbes 3D au Chapitre 13.
Tout point dans le plan d’un triangle peut être exprimé comme une moyenne pondérée des sommets. Ces poids sont connus sous le nom de coordonnées barycentriques. La conversion des coordonnées barycentriques vers l’espace 3D standard est définie par
Calcul d’un point 3D à partir des coordonnées barycentriques
Bien sûr, c’est simplement une combinaison linéaire de certains vecteurs. La Section 3.3.3 a montré comment les coordonnées cartésiennes ordinaires peuvent également être interprétées comme une combinaison linéaire des vecteurs de base, mais la subtile distinction entre les coordonnées barycentriques et les coordonnées cartésiennes ordinaires est que pour les coordonnées barycentriques, la somme des coordonnées est restreinte à être unitaire :
Cette contrainte de normalisation supprime un degré de liberté, c’est pourquoi même si il y a trois coordonnées, c’est toujours un espace 2D.
Les valeurs , , sont les « contributions » ou « poids » que chaque sommet apporte au point. La Figure 9.18 montre quelques exemples de points et leurs coordonnées barycentriques.
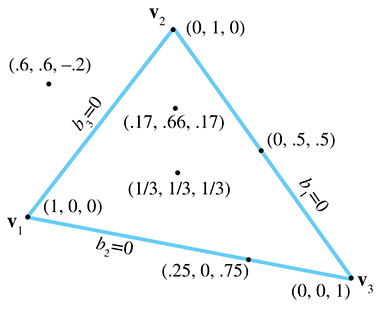
Figure 9.18 Exemples de coordonnées barycentriques
Faisons quelques observations ici. Premièrement, notez que les trois sommets du triangle ont une forme triviale dans l’espace barycentrique :
Deuxièmement, tous les points sur le côté opposé à un sommet auront un zéro pour la coordonnée barycentrique correspondant à ce sommet. Par exemple, pour tous les points sur la droite contenant (qui est opposé à ).
Enfin, n’importe quel point dans le plan peut être décrit en coordonnées barycentriques, pas seulement les points à l’intérieur du triangle. Les coordonnées barycentriques d’un point à l’intérieur du triangle seront toutes dans la plage . Tout point en dehors du triangle aura au moins une coordonnée négative. L’espace barycentrique pavèle le plan en triangles de la même taille que le triangle original, comme le montre la Figure 9.19.
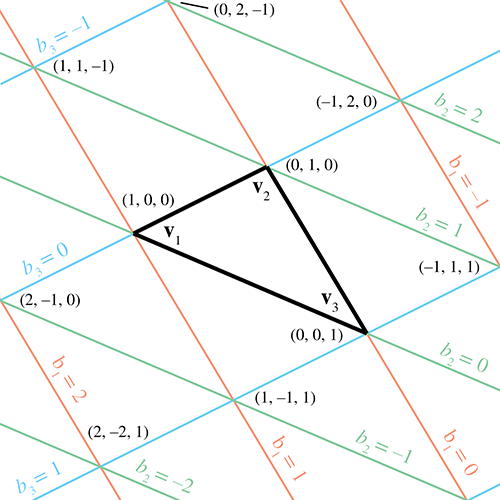
Figure 9.19Les coordonnées barycentriques pavèlent le plan
Il y a une autre façon de penser aux coordonnées barycentriques. En ignorant , nous pouvons interpréter comme des coordonnées 2D régulières, où l’origine est à , l’axe est , et l’axe est . Cela peut être rendu plus explicite en réarrangeant l’Équation (9.17) : Interprétation de comme des coordonnées 2D ordinaires
Cela rend très clair que, en raison de la contrainte de normalisation, bien qu’il y ait trois coordonnées, il n’y a que deux degrés de liberté. Nous pourrions décrire complètement un point dans l’espace barycentrique en utilisant seulement deux des coordonnées. En fait, le rang de l’espace décrit par les coordonnées ne dépend pas de la dimension des « points d’échantillonnage » mais plutôt du nombre de points d’échantillonnage. Le nombre de degrés de liberté est inférieur d’un au nombre de coordonnées barycentriques, puisque nous avons la contrainte que les coordonnées somment à un. Par exemple, si nous avons deux points d’échantillonnage, la dimension des coordonnées barycentriques est deux, et l’espace qui peut être décrit en utilisant ces coordonnées est une droite, qui est un espace 1D. Notez que la droite peut être une droite 1D (c’est-à-dire une interpolation d’un scalaire), une droite 2D, une droite 3D, ou une droite dans un espace de dimension supérieure. Dans cette section, nous avons eu trois points d’échantillonnage (les sommets de notre triangle) et trois coordonnées barycentriques, résultant en un espace 2D — un plan. Si nous avions quatre points d’échantillonnage en 3D, nous pourrions utiliser les coordonnées barycentriques pour localiser des points en 3D. Quatre coordonnées barycentriques induisent un espace « tétraédrique », plutôt que l’espace « triangulaire » que l’on obtient avec trois coordonnées.
Pour convertir un point de coordonnées barycentriques en coordonnées cartésiennes standard, nous calculons simplement la moyenne pondérée des sommets en appliquant l’Équation (9.17). La conversion inverse — calculer les coordonnées barycentriques à partir des coordonnées cartésiennes — est légèrement plus difficile, et est discutée à la Section 9.6.4. Cependant, avant d’entrer trop dans les détails (qui pourraient être sautés par un lecteur occasionnel), maintenant que vous avez l’idée de base derrière les coordonnées barycentriques, profitons de cette occasion pour mentionner quelques endroits où les coordonnées barycentriques sont utiles.
En infographie, il est courant que des paramètres soient édités (ou calculés) par sommet, tels que les coordonnées de texture, les couleurs, les normales de surface, les valeurs d’éclairage, etc. Nous devons souvent ensuite déterminer la valeur interpolée de l’un de ces paramètres à un emplacement arbitraire à l’intérieur du triangle. Les coordonnées barycentriques rendent cette tâche facile. Nous déterminons d’abord les coordonnées barycentriques du point intérieur en question, puis nous prenons la moyenne pondérée des valeurs aux sommets pour le paramètre que nous cherchons.
Un autre exemple important est le test d’intersection. Une façon simple d’effectuer un test rayon-triangle consiste à déterminer le point où le rayon intersecte le plan infini contenant le triangle, puis à décider si ce point se trouve à l’intérieur du triangle. Une façon simple de prendre cette décision est de calculer les coordonnées barycentriques du point, en utilisant les techniques décrites ici. Si toutes les coordonnées se trouvent dans l’intervalle , alors le point est à l’intérieur du triangle ; sinon, au moins une coordonnée est hors de cet intervalle et le point est à l’extérieur du triangle. Il est courant que les coordonnées barycentriques calculées soient utilisées pour récupérer une propriété de surface interpolée. Par exemple, supposons que nous lancions un rayon pour déterminer si une lumière est visible depuis un certain point ou si le point est dans l’ombre. Nous frappons un triangle sur un modèle à un emplacement arbitraire. Si le modèle est opaque, la lumière n’est pas visible. Cependant, si le modèle utilise la transparence, nous pouvons avoir besoin de déterminer l’opacité à cet emplacement pour déterminer quelle fraction de la lumière est bloquée. Typiquement, cette transparence se trouve dans une carte de texture, indexée avec des coordonnées UV. (Plus d’informations sur le mappage de texture sont présentées à la Section 10.5.) Pour récupérer la transparence à l’emplacement de l’intersection du rayon, nous utilisons les coordonnées barycentriques au point pour interpoler les UV à partir des sommets. Nous utilisons ensuite ces UV pour récupérer le texel dans la carte de texture et déterminer la transparence de cet emplacement particulier sur la surface.
9.6.4Calcul des coordonnées barycentriques
Voyons maintenant comment déterminer les coordonnées barycentriques à partir des coordonnées cartésiennes. Nous commençons en 2D avec la Figure 9.20, qui montre les trois sommets , , et et le point . Nous avons également étiqueté les trois « sous-triangles » , , , qui sont opposés au sommet du même indice. Ceux-ci deviendront utiles dans un instant.
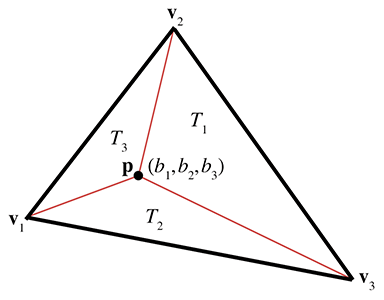
Figure 9.20 Calcul des coordonnées barycentriques pour un point arbitraire
Nous connaissons les coordonnées cartésiennes des trois sommets et du point . Notre tâche est de calculer les coordonnées barycentriques , et . Cela nous donne trois équations et trois inconnues :
La résolution de ce système d’équations donne
Calcul des coordonnées barycentriques pour un point 2D
En examinant l’Équation (9.18) de près, nous constatons que le dénominateur est le même dans chaque expression — il est égal au double de l’aire du triangle, selon l’Équation (9.15). De plus, pour chaque coordonnée barycentrique , le numérateur est égal au double de l’aire du « sous-triangle » . En d’autres termes,
Interprétation des coordonnées barycentriques comme rapports d’aires
Notez que cette interprétation s’applique même si est hors du triangle, puisque notre équation pour le calcul de l’aire donne un résultat négatif si les sommets sont énumérés dans le sens inverse des aiguilles d’une montre. Si les trois sommets du triangle sont colinéaires, alors le triangle est dégénéré et l’aire au dénominateur sera nulle, et donc les coordonnées barycentriques ne peuvent pas être calculées.
Le calcul des coordonnées barycentriques pour un point arbitraire en 3D est plus compliqué qu’en 2D. Nous ne pouvons pas résoudre un système d’équations comme nous l’avons fait auparavant, puisque nous avons trois inconnues et quatre équations (une équation pour chaque coordonnée de , plus la contrainte de normalisation sur les coordonnées barycentriques). Une autre complication est que peut ne pas se trouver dans le plan contenant le triangle, auquel cas les coordonnées barycentriques sont indéfinies. Pour l’instant, supposons que se trouve dans le plan contenant le triangle.
Une astuce qui fonctionne est de transformer le problème 3D en un problème 2D en écartant simplement l’une des coordonnées , ou . Cela a pour effet de projeter le triangle sur l’un des trois plans cardinaux. Intuitivement, cela fonctionne parce que les aires projetées sont proportionnelles aux aires originales.
Mais quelle coordonnée doit-on écarter ? Nous ne pouvons pas toujours écarter la même, car les points projetés seront colinéaires si le triangle est perpendiculaire au plan de projection. Si notre triangle est presque perpendiculaire au plan de projection, nous aurons des problèmes de précision en virgule flottante. Une solution à ce dilemme est de choisir le plan de projection de manière à maximiser l’aire du triangle projeté. Cela peut être fait en examinant la normale au plan, et la coordonnée dont la valeur absolue est la plus grande est la coordonnée que nous écarterons. Par exemple, si la normale est , nous écarterions les valeurs des sommets et de , en projetant sur le plan . L’extrait de code dans le Listing 9.6 montre comment calculer les coordonnées barycentriques pour un point 3D arbitraire.
bool computeBarycentricCoords3d(
const Vector3 v[3], // sommets du triangle
const Vector3 &p, // point pour lequel calculer les coordonnées
float b[3] // coordonnées barycentriques retournées ici
) {
// D'abord, calculer deux vecteurs d'arête dans le sens horaire
Vector3 d1 = v[1] - v[0];
Vector3 d2 = v[2] - v[1];
// Calculer la normale de surface par produit vectoriel. Dans
// de nombreux cas, cette étape pourrait être ignorée, car nous
// aurions la normale de surface précalculée. Nous n'avons pas
// besoin de la normaliser, bien que si une normale précalculée
// était normalisée, ce serait correct.
Vector3 n = crossProduct(d1, d2);
// Localiser l'axe dominant de la normale, et sélectionner le
// plan de projection
float u1, u2, u3, u4;
float v1, v2, v3, v4;
if ((fabs(n.x) >= fabs(n.y)) && (fabs(n.x) >= fabs(n.z))) {
// Écarter x, projeter sur le plan yz
u1 = v[0].y - v[2].y;
u2 = v[1].y - v[2].y;
u3 = p.y - v[0].y;
u4 = p.y - v[2].y;
v1 = v[0].z - v[2].z;
v2 = v[1].z - v[2].z;
v3 = p.z - v[0].z;
v4 = p.z - v[2].z;
} else if (fabs(n.y) >= fabs(n.z)) {
// Écarter y, projeter sur le plan xz
u1 = v[0].z - v[2].z;
u2 = v[1].z - v[2].z;
u3 = p.z - v[0].z;
u4 = p.z - v[2].z;
v1 = v[0].x - v[2].x;
v2 = v[1].x - v[2].x;
v3 = p.x - v[0].x;
v4 = p.x - v[2].x;
} else {
// Écarter z, projeter sur le plan xy
u1 = v[0].x - v[2].x;
u2 = v[1].x - v[2].x;
u3 = p.x - v[0].x;
u4 = p.x - v[2].x;
v1 = v[0].y - v[2].y;
v2 = v[1].y - v[2].y;
v3 = p.y - v[0].y;
v4 = p.y - v[2].y;
}
// Calculer le dénominateur, vérifier s'il est invalide
float denom = v1*u2 - v2*u1;
if (denom == 0.0f) {
// Triangle invalide - probablement d'aire nulle
return false;
}
// Calculer les coordonnées barycentriques
float oneOverDenom = 1.0f / denom;
b[0] = (v4*u2 - v2*u4) * oneOverDenom;
b[1] = (v1*u3 - v3*u1) * oneOverDenom;
b[2] = 1.0f - b[0] - b[1];
// OK
return true;
}Une autre technique pour calculer les coordonnées barycentriques en 3D est basée sur la méthode de calcul de l’aire d’un triangle 3D en utilisant le produit vectoriel, discutée à la Section 9.6.2. Rappelons qu’à partir de deux vecteurs d’arête et d’un triangle, nous pouvons calculer l’aire du triangle comme . Une fois que nous avons l’aire du triangle entier et les aires des trois sous-triangles, nous pouvons calculer les coordonnées barycentriques.
Il y a un léger problème avec cela : la magnitude du produit vectoriel n’est pas sensible à l’ordre des sommets — la magnitude est par définition toujours positive. Cela ne fonctionnera pas pour les points hors du triangle, car ces points doivent toujours avoir au moins une coordonnée barycentrique négative.
Voyons si nous pouvons trouver un moyen de contourner ce problème. Il semble que ce dont nous avons vraiment besoin est un moyen de calculer la longueur du vecteur produit vectoriel qui donnerait une valeur négative si les sommets étaient énumérés dans le « mauvais » ordre. Il s’avère qu’il existe un moyen très simple de faire cela avec le produit scalaire.
Attribuons au produit vectoriel de deux vecteurs d’arête d’un triangle. Rappelons que la magnitude de sera égale au double de l’aire du triangle. Supposons que nous ayons une normale de longueur unitaire. Or, et sont parallèles, car ils sont tous deux perpendiculaires au plan contenant le triangle. Cependant, ils peuvent pointer dans des directions opposées. Rappelons d’après la Section 2.11.2 que le produit scalaire de deux vecteurs est égal au produit de leurs magnitudes fois le cosinus de l’angle entre eux. Puisque nous savons que est un vecteur unitaire, et que les vecteurs pointent soit exactement dans la même direction soit exactement dans la direction opposée, nous avons
En divisant ce résultat par deux, nous avons un moyen de calculer l’« aire signée » d’un triangle en 3D. Armés de cette astuce, nous pouvons maintenant appliquer l’observation de la section précédente, selon laquelle chaque coordonnée barycentrique est proportionnelle à l’aire du sous-triangle . Commençons par étiqueter tous les vecteurs impliqués, comme le montre la Figure 9.21.
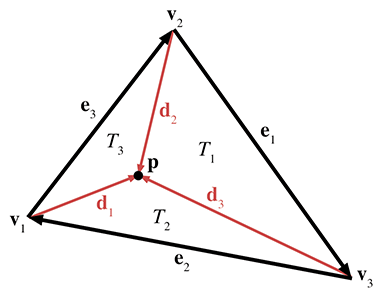
Figure 9.21 Calcul des coordonnées barycentriques en 3D
Comme le montre la Figure 9.21, chaque sommet a un vecteur de vers , nommé . En résumant les équations pour les vecteurs, nous avons
Nous aurons également besoin d’une normale de surface, qui peut être calculée par
Les aires pour le triangle entier (que nous appellerons simplement ) et les trois sous-triangles sont données par
Chaque coordonnée barycentrique est donnée par :
Calcul des coordonnées barycentriques en 3D
Notez que est utilisé dans tous les numérateurs et tous les dénominateurs, et n’a donc pas nécessairement besoin d’être un vecteur unitaire.
Cette technique de calcul des coordonnées barycentriques implique plus d’opérations scalaires que la méthode de projection en 2D. Cependant, elle est sans branchement et offre une meilleure optimisation SIMD.
9.6.5Points spéciaux
Dans cette section, nous discutons de trois points d’un triangle qui ont une signification géométrique particulière :
centre de gravité
incentre
centre du cercle circonscrit.
Pour présenter ces calculs classiques, nous suivons l’article de Goldman [3] dans Graphics Gems. Pour chaque point, nous discutons de sa signification géométrique et de sa construction et donnons ses coordonnées barycentriques.
Le centre de gravité est le point sur lequel le triangle s’équilibrerait parfaitement. C’est l’intersection des médianes. (Une médiane est une droite reliant un sommet au milieu du côté opposé.) La Figure 9.22 montre le centre de gravité d’un triangle.
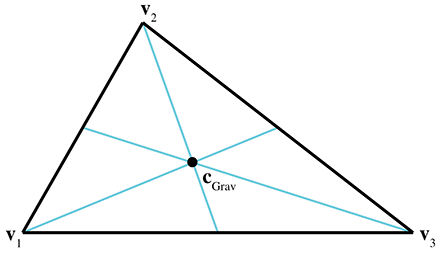
Figure 9.22 Le centre de gravité d’un triangle
Le centre de gravité est la moyenne géométrique des trois sommets :
Les coordonnées barycentriques sont
Le centre de gravité est également connu sous le nom de centroïde.
L’incentre est le point dans le triangle qui est équidistant des côtés. Il est appelé incentre parce qu’il est le centre du cercle inscrit dans le triangle. L’incentre est construit comme l’intersection des bissectrices des angles, comme le montre la Figure 9.23.
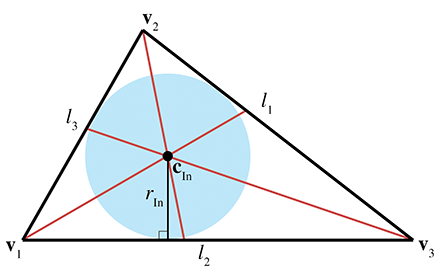
Figure 9.23L’incentre d’un triangle
L’incentre est calculé par
où est le périmètre du triangle. Ainsi, les coordonnées barycentriques de l’incentre sont
Le rayon du cercle inscrit peut être calculé en divisant l’aire du triangle par son périmètre :
Le cercle inscrit résout le problème de trouver un cercle tangent à trois droites.
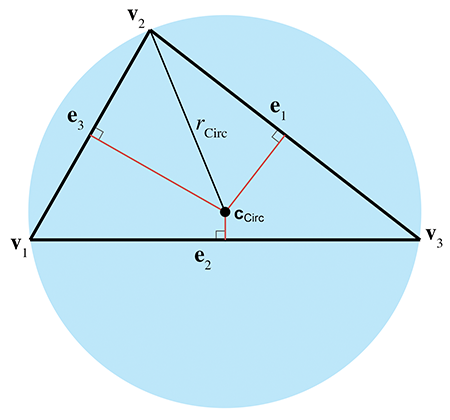
Figure 9.24Le centre du cercle circonscrit d’un triangle
Le centre du cercle circonscrit est le point du triangle qui est équidistant des sommets. C’est le centre du cercle qui circonscrit le triangle. Il est construit comme l’intersection des médiatrices des côtés. La Figure 9.24 montre le centre du cercle circonscrit d’un triangle.
Pour calculer le centre du cercle circonscrit, nous définissons d’abord les valeurs intermédiaires suivantes :
Avec ces valeurs intermédiaires, les coordonnées barycentriques du centre du cercle circonscrit sont données par
ainsi, le centre du cercle circonscrit est donné par
Le rayon du cercle circonscrit est donné par
Le rayon et le centre du cercle circonscrit résolvent le problème de trouver un cercle passant par trois points.
9.7Polygones
Cette section introduit les polygones et discute de quelques-uns des problèmes les plus importants qui surviennent lorsqu’on traite des polygones. Il est difficile de donner une définition simple pour un polygone, car la définition précise varie généralement selon le contexte. En général, un polygone est un objet plan composé de sommets et d’arêtes. Les prochaines sections discuteront de plusieurs façons dont les polygones peuvent être classifiés.
La Section 9.7.1 présente la différence entre les polygones simples et complexes et mentionne les polygones auto-intersectants. La Section 9.7.2 discute de la différence entre les polygones convexes et concaves. La Section 9.7.3 décrit comment tout polygone peut être transformé en triangles connectés.
9.7.1Polygones simples versus complexes
Un polygone simple n’a pas de « trous », tandis qu’un polygone complexe peut en avoir (voir la Figure 9.25.) Un polygone simple peut être décrit en énumérant les sommets dans l’ordre autour du polygone. (Rappelons que dans un monde à main gauche, nous les énumérons généralement dans le sens horaire lorsqu’on les voit depuis le côté « avant » du polygone.) Les polygones simples sont utilisés beaucoup plus fréquemment que les polygones complexes.
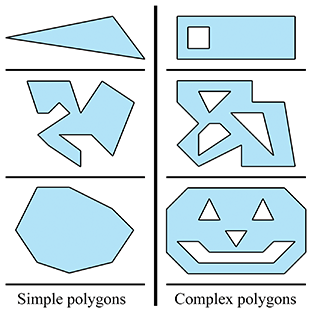
Figure 9.25Polygones simples versus complexes
Nous pouvons transformer tout polygone complexe en un polygone simple en ajoutant des paires d’arêtes de « couture », comme le montre la Figure 9.26. Comme le montre le gros plan à droite, nous ajoutons deux arêtes par couture. Les arêtes sont en réalité coïncidentes, bien que dans le gros plan elles aient été séparées pour qu’on puisse les voir. Lorsque nous pensons aux arêtes ordonnées autour du polygone, les deux arêtes de couture pointent dans des directions opposées.
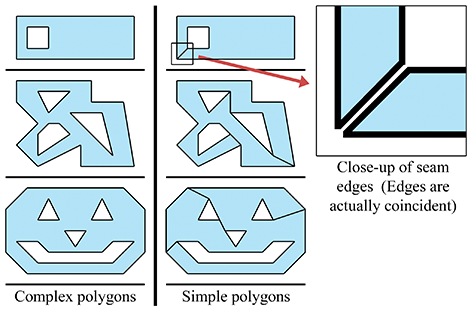
Figure 9.26 Transformation de polygones complexes en polygones simples en ajoutant des paires d’arêtes de couture
Les arêtes de la plupart des polygones simples ne se croisent pas entre elles. Si les arêtes se croisent, le polygone est considéré comme un polygone auto-intersectant. Un exemple de polygone auto-intersectant est montré à la Figure 9.27.
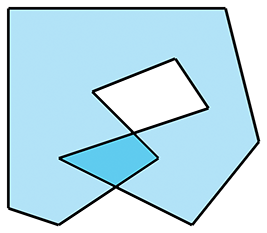
Figure 9.27Un polygone auto-intersectant
La plupart des gens trouvent généralement plus facile d’organiser les choses de sorte que les polygones auto-intersectants soient évités, ou simplement rejetés. Dans la plupart des situations, ce n’est pas une grande contrainte pour l’utilisateur.
9.7.2Polygones convexes versus concaves
Les polygones simples non auto-intersectants peuvent être classifiés davantage comme convexes ou concaves. Donner une définition précise de « convexe » est en fait assez délicat car il existe de nombreux cas dégénérés. Pour la plupart des polygones, les définitions couramment utilisées suivantes sont équivalentes, bien que certains polygones dégénérés puissent être classifiés comme convexes selon une définition et concaves selon une autre.
Intuitivement, un polygone convexe n’a pas de « creux ». Un polygone concave a au moins un sommet qui est un « creux », appelé un point de concavité (voir la Figure 9.28).
Dans un polygone convexe, la droite entre deux points quelconques du polygone est entièrement contenue dans le polygone. Dans un polygone concave, il existe au moins une paire de points du polygone pour laquelle la droite entre les points est partiellement hors du polygone.
En parcourant le périmètre d’un polygone convexe, à chaque sommet nous tournerons dans la même direction. Dans un polygone concave, nous ferons certains virages à gauche et certains virages à droite. Nous tournerons dans la direction opposée aux points de concavité. (Notez que cela s’applique uniquement aux polygones non auto-intersectants.)
Comme nous l’avons mentionné, les cas dégénérés peuvent rendre même ces définitions relativement claires floues. Par exemple, qu’en est-il d’un polygone avec deux sommets coïncidants consécutifs, ou d’une arête qui revient sur elle-même ? Ces polygones sont-ils considérés comme convexes ? En pratique, les « définitions » suivantes de la convexité sont souvent utilisées :
Si mon code, qui est censé fonctionner uniquement pour les polygones convexes, peut le traiter, alors c’est convexe. (C’est la définition « si ça marche, n’y touche pas ».)
Si mon algorithme qui teste la convexité décide que c’est convexe, alors c’est convexe. (C’est une explication de type « l’algorithme comme définition ».)
Pour l’instant, ignorons les cas pathologiques et donnons des exemples de polygones sur lesquels nous pouvons tous convenir qu’ils sont définitivement convexes ou définitivement concaves. Le polygone concave du haut dans la Figure 9.28 a un point de concavité. Le polygone concave du bas en a cinq.
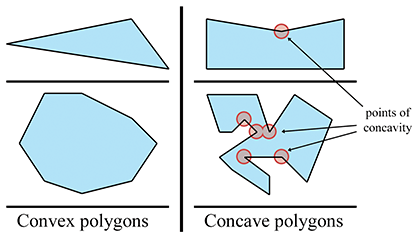
Figure 9.28Polygones convexes vs. concaves
Tout polygone concave peut être divisé en pièces convexes. L’idée de base est de localiser les points de concavité (appelés « sommets réflexes ») et de les supprimer systématiquement en ajoutant des diagonales. O’Rourke [6] fournit un algorithme qui fonctionne pour les polygones simples, et de Berg et al. [2] montrent une méthode plus complexe qui fonctionne aussi pour les polygones complexes.
Comment savoir si un polygone est convexe ou concave ? Une méthode consiste à examiner la somme des angles aux sommets. Considérons un polygone convexe à sommets. La somme des angles intérieurs d’un polygone convexe est . Nous avons deux façons différentes de montrer que cela est vrai.
Premièrement, soit l’angle intérieur au sommet . Clairement, si le polygone est convexe, alors . Le montant du « virage » qui se produit à chaque sommet sera . Un polygone fermé tournera bien sûr d’une révolution complète, soit . Par conséquent,
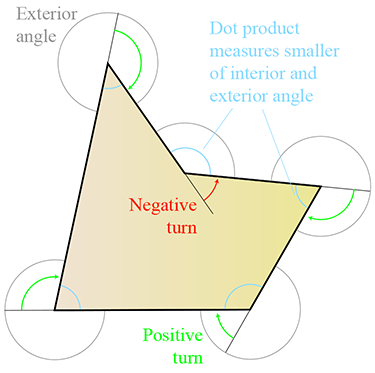
Figure 9.29 Utilisation du produit scalaire pour déterminer si un polygone est convexe ou concave
Deuxièmement, comme nous le montrerons à la Section 9.7.3, tout polygone convexe à sommets peut être triangulé en triangles. D’après la géométrie classique, la somme des angles intérieurs d’un triangle est . La somme des angles intérieurs de tous les triangles est , et nous pouvons voir que cette somme doit également être égale à la somme des angles intérieurs du polygone lui-même.
Malheureusement, la somme des angles intérieurs est pour les polygones concaves ainsi que pour les polygones convexes. Alors comment cela nous rapproche-t-il de la détermination si un polygone est convexe ou non ? Comme le montre la (voir Figure ???), le produit scalaire peut être utilisé pour mesurer le plus petit des angles extérieur et intérieur. L’angle extérieur d’un sommet de polygone est le complément de l’angle intérieur, ce qui signifie qu’ils somment à . (Ce n’est pas la même chose que l’« angle de virage », et vous pourrez remarquer que la définition de l’angle extérieur pour les sommets de polygone est différente de celle classique utilisée pour les sommets de triangle.) Donc, si nous prenons la somme du plus petit angle (intérieur ou extérieur) à chaque sommet, la somme sera pour les polygones convexes, et inférieure à cela si le polygone est concave.
Le Listing 9.7 montre comment déterminer si un polygone est convexe en sommant les angles.
bool isPolygonConvex(
int n, // Nombre de sommets
const Vector3 vl[], // pointeur vers le tableau des sommets
) {
// Initialiser la somme à 0 radians
float angleSum = 0.0f;
// Parcourir le polygone et sommer l'angle à chaque sommet
for (int i = 0 ; i < n ; ++i) {
// Obtenir les vecteurs d'arête. Nous devons être prudents avec
// le premier et le dernier sommet. Notez également que
// cela pourrait être considérablement optimisé
Vector3 e1;
if (i == 0) {
e1 = vl[n-1] - vl[i];
} else {
e1 = vl[i-1] - vl[i];
}
Vector3 e2;
if (i == n-1) {
e2 = vl[0] - vl[i];
} else {
e2 = vl[i+1] - vl[i];
}
// Normaliser et calculer le produit scalaire
e1.normalize();
e2.normalize();
float dot = e1 * e2;
// Calculer le plus petit angle en utilisant une fonction
// « sûre » qui se protège contre les erreurs de plage pouvant
// être causées par une imprécision numérique
float theta = safeAcos(dot);
// Additionner
angleSum += theta;
}
// Déterminer quelle devrait être la somme des angles en supposant
// que nous sommes convexes. Rappelons que pi rad = 180 degrés
float convexAngleSum = (float)(n - 2) * kPi;
// Vérifier si la somme des angles est inférieure à ce qu'elle
// devrait être ; si oui, nous sommes concaves. Nous accordons une
// légère tolérance pour l'imprécision numérique
if (angleSum < convexAngleSum - (float)n * 0.0001f) {
// Nous sommes concaves
return false;
}
// Nous sommes convexes, dans la tolérance
return true;
}Une autre méthode pour déterminer la convexité consiste à rechercher des sommets qui sont des points de concavité. Si aucun n’est trouvé, alors le polygone est convexe. L’idée de base est que chaque sommet doit tourner dans la même direction. Tout sommet qui tourne dans la direction opposée est un point de concavité. Nous pouvons déterminer dans quel sens un sommet tourne en utilisant le produit vectoriel sur les vecteurs d’arête. Rappelons d’après la Section 2.12.2 que dans un système de coordonnées à main gauche, le produit vectoriel pointera vers vous si les vecteurs forment un virage dans le sens horaire. Par « vers vous », nous supposons que vous regardez le polygone depuis l’avant, tel que déterminé par la normale du polygone. Si cette normale n’est pas initialement disponible, des précautions doivent être prises pour la calculer ; car nous ne savons pas si le polygone est convexe ou non, nous ne pouvons pas simplement choisir trois sommets quelconques pour calculer la normale. Les techniques de la Section 9.5.3 pour calculer la normale de meilleur ajustement à partir d’un ensemble de points peuvent être utilisées dans ce cas.
Une fois que nous avons une normale, nous vérifions chaque sommet du polygone, calculant une normale à ce sommet en utilisant les vecteurs d’arête adjacents dans le sens horaire. Nous prenons le produit scalaire de la normale du polygone avec la normale calculée à ce sommet pour déterminer si elles pointent dans des directions opposées. Si c’est le cas (le produit scalaire est négatif), alors nous avons localisé un point de concavité.
En 2D, nous pouvons simplement agir comme si le polygone était en 3D dans le plan , et supposer que la normale est . Il existe des difficultés subtiles avec toute méthode pour déterminer la convexité. Schorn et Fisher [7] discutent du sujet plus en détail.
9.7.3Triangulation et découpage en éventail
Tout polygone peut être divisé en triangles. Ainsi, toutes les opérations et calculs pour les triangles peuvent être appliqués par morceaux aux polygones. La triangulation de polygones complexes, auto-intersectants, ou même simplement concaves n’est pas une tâche triviale [6][2] et dépasse légèrement le cadre de ce livre.
Heureusement, la triangulation de polygones convexes simples est une tâche triviale. Une technique de triangulation évidente consiste à choisir un sommet (disons, le premier) et à « déployer en éventail » le polygone autour de ce sommet. Étant donné un polygone à sommets, énumérés autour du polygone, nous pouvons facilement former triangles, chacun de la forme avec l’indice allant de 3 à , comme le montre la Figure 9.30.
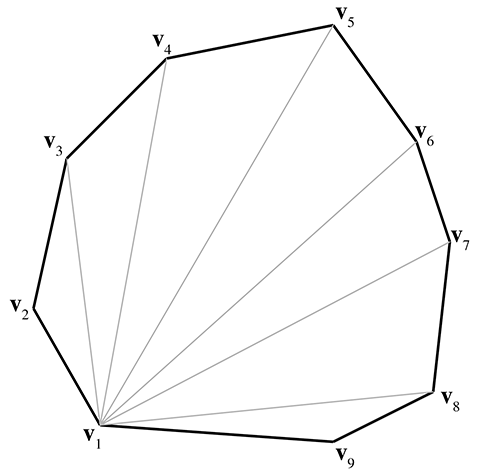
Figure 9.30 Triangulation d’un polygone convexe par découpage en éventail
Le découpage en éventail tend à créer de nombreux triangles longs et fins, ce qui peut être problématique dans certaines situations, comme le calcul d’une normale de surface. Certains matériels grand public peuvent rencontrer des problèmes de précision lors du découpage d’arêtes très longues sur le tronc de vue. Des techniques plus intelligentes existent pour tenter de minimiser ce problème. Une idée est de trianguler comme suit : considérons que nous pouvons diviser un polygone en deux parties avec une diagonale entre deux sommets. Lorsque cela se produit, les deux angles intérieurs aux sommets de la diagonale sont chacun divisés en deux nouveaux angles intérieurs. Ainsi, un total de quatre nouveaux angles intérieurs sont créés. Pour subdiviser un polygone, sélectionner la diagonale qui maximise le plus petit de ces quatre nouveaux angles intérieurs. Diviser le polygone en deux en utilisant cette diagonale. Appliquer récursivement la procédure à chaque moitié, jusqu’à ce qu’il ne reste que des triangles. Cet algorithme aboutit à une triangulation avec moins de triangles dégénérés.
Exercices
Étant donné le rayon 2D sous forme paramétrique
déterminer la droite contenant ce rayon, sous forme pente-ordonnée.
Donner la pente et l’ordonnée à l’origine de la droite 2D définie implicitement par .
Considérer l’ensemble de cinq points :
(a)Déterminer l’AABB de cet ensemble. Quels sont et ?
(b)Lister les huit points de coin.
(c)Déterminer le point central et le vecteur taille .
(d)Multiplier les cinq points par la matrice suivante, que nous espérons que vous reconnaîtrez comme une rotation de autour de l’axe :
(e)Quelle est l’AABB de ces points transformés ?
(f)Quelle est l’AABB que l’on obtient en transformant l’AABB originale ? (La boîte englobante des points de coin transformés.)
Considérer un triangle défini par l’énumération dans le sens horaire des sommets , , .
(a)Quelle est l’équation du plan contenant ce triangle ?
(b)Le point est-il du côté avant ou arrière de ce plan ? Quelle est la distance de ce point au plan ?
(c)Calculer les coordonnées barycentriques du point .
(d)Quel est le centre de gravité ?
(e)Quel est l’incentre ?
(f)Quel est le centre du cercle circonscrit ?
Quelle est l’équation du plan de meilleur ajustement pour les points suivants, qui ne sont pas tout à fait coplanaires ?
Considérer un polygone convexe qui a sept sommets numérotés . Montrer comment décomposer ce polygone en éventail.
Un carré était assis tranquillement
Devant sa cabane rectangulaire
Quand un triangle est tombé — plouf !
« Je dois aller à l’hôpital, »
Cria le carré blessé,
Alors un cercle roulant qui passait
L’a ramassé et l’y a conduit.
— Shapes (1981) de Shel Silverstein
Références
[1] James F. Blinn. “A Generalization of Algebraic Surface Drawing.” ACM Trans. Graph. 1 (1982), 235–256.
[2] M. de Berg, M. van Kreveld, M. Overmars et O. Schwarzkopf. Computational Geometry—Algorithms and Applications. Springer-Verlag, 1997.
[3] Ronald Goldman. “Triangles.” Dans Graphics Gems, édité par Andrew S. Glassner. San Diego : Academic Press Professional, 1990.
[4] Eric Lengyel. Mathematics for 3D Game Programming and Computer Graphics, Deuxième édition. Boston : Charles River Media, 2004. http://www.terathon.com/books/mathgames2.html.
[5] William E. Lorensen et Harvey E. Cline. “Marching Cubes: A High Resolution 3D Surface Construction Algorithm.” Dans Proceedings of the 14th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH ’87, pp. 163–169. New York : ACM, 1987.
[6] Joseph O’Rourke. Computational Geometry in C, Deuxième édition. Cambridge, Royaume-Uni : Cambridge University Press, 1994.
[7] Peter Schorn et Frederick Fisher. “Testing the Convexity of a Polygon.” Dans Graphics Gems IV, édité par Paul S. Heckbert. San Diego : Academic Press Professional, 1994.
<< Rotation en trois dimensions
Retour en haut
Sujets mathématiques issus de la 3D graphique >>