Chapitre 3
Espaces de coordonnées multiples
Les frontières ont été fixées pour moi dans des endroits agréables ;
j’ai vraiment reçu un bel héritage.
— Psaume 16:6 (Nouvelle Version Internationale)
Chapitre 1 a montré comment nous pouvons établir un espace de coordonnées n’importe où simplement en choisissant un point comme origine et en décidant de l’orientation des axes. Nous ne prenons généralement pas ces décisions arbitrairement ; nous créons des espaces de coordonnées pour des raisons spécifiques (on pourrait dire « des espaces différents pour des cas différents »). Ce chapitre donne quelques exemples d’espaces de coordonnées courants utilisés en infographie et dans les jeux. Nous verrons ensuite comment les espaces de coordonnées s’imbriquent les uns dans les autres.
Ce chapitre introduit l’idée de systèmes de coordonnées multiples. Il est divisé en cinq sections principales.
Section 3.1 justifie la nécessité de systèmes de coordonnées multiples.
Section 3.2 introduit quelques espaces de coordonnées courants. Les principaux concepts introduits sont
l’espace monde
l’espace objet
l’espace caméra
l’espace vertical
Section 3.3 décrit les transformations d’espaces de coordonnées.
Section 3.3.1 expose une dualité entre deux façons de concevoir les transformations d’espaces de coordonnées.
Section 3.3.2 décrit comment spécifier un système de coordonnées en termes d’un autre espace.
Section 3.3.3 aborde le concept très important des vecteurs de base.
Section 3.4 traite des espaces de coordonnées imbriqués, couramment utilisés pour animer des objets articulés hiérarchiquement dans l’espace 3D.
Section 3.5 est une campagne pour un code plus lisible par les humains.
3.1Pourquoi s’encombrer de plusieurs espaces de coordonnées ?
Pourquoi avons-nous besoin de plus d’un espace de coordonnées ? Après tout, tout un seul système de coordonnées 3D s’étend infiniment et contient donc tous les points dans l’espace. Nous pourrions donc simplement choisir un espace de coordonnées, le déclarer espace de coordonnées « monde », et tous les points pourraient être localisés dans cet espace. Ne serait-ce pas plus simple ? En pratique, la réponse est « non ». La plupart des gens trouvent plus commode d’utiliser différents espaces de coordonnées dans différentes situations.
La raison pour laquelle des espaces de coordonnées multiples sont utilisés est que certaines informations ne sont connues que dans le contexte d’un référentiel particulier. Il peut être vrai qu’en théorie tous les points pourraient être exprimés à l’aide d’un seul système de coordonnées « monde ». Cependant, pour un certain point , il est possible que nous ne connaissions pas les coordonnées de dans le système de coordonnées « monde ». Mais nous pourrions être en mesure d’exprimer par rapport à un autre système de coordonnées.
Par exemple, les habitants de Cartésia (voir Section 1.2.1) utilisent une carte de leur ville avec l’origine centrée sensiblement au centre-ville et les axes dirigés selon les points cardinaux de la boussole. Les habitants de Dyslexia utilisent une carte de leur ville avec les coordonnées centrées en un point arbitraire et les axes orientés dans des directions arbitraires qui semblaient probablement une bonne idée à l’époque. Les citoyens de ces deux villes sont très satisfaits de leurs cartes respectives, mais l’ingénieur des transports de l’État chargé d’établir le budget pour la première autoroute entre Cartésia et Dyslexia a besoin d’une carte montrant les détails des deux villes, ce qui introduit un troisième système de coordonnées qui lui est supérieur, bien que pas nécessairement à quiconque d’autre. Chaque point important des deux cartes doit être converti depuis les coordonnées locales de la ville respective vers le nouveau système de coordonnées pour créer la nouvelle carte.
Le concept de systèmes de coordonnées multiples a un précédent historique. Tandis qu’Aristote (384–322 av. J.-C.), dans ses livres Du Ciel et Physique, proposait un univers géocentrique avec la Terre à l’origine, Aristarque (ca. 310–230 av. J.-C.) proposait un univers héliocentrique avec le soleil à l’origine. Nous voyons ainsi qu’il y a plus de deux millénaires, le choix du système de coordonnées était déjà un sujet brûlant de discussion. La question ne fut pas réglée avant encore quelques millénaires, lorsque Nicolas Copernic (1473–1543) observa dans son livre De Revolutionibus Orbium Coelestium (Des Révolutions des Orbes Célestes) que les orbites des planètes peuvent s’expliquer plus simplement dans un univers héliocentrique sans toutes ces complications avec des roues dans des roues d’un univers géocentrique.
Dans L’Arenaire, Archimède (mort en 212 av. J.-C.), peut-être motivé par certains des concepts introduits dans Section 1.1, développa une notation pour noter de très grands nombres—des nombres bien plus grands que quiconque n’avait jamais comptés à cette époque. Au lieu de choisir de compter des moutons morts, comme dans Section 1.1, il choisit de compter le nombre de grains de sable nécessaires pour remplir l’univers. (Il estima qu’il faudrait grains de sable, mais il n’aborda pas la question de l’origine du sable.) Afin d’obtenir des nombres plus grands, il choisit non pas l’univers géocentrique généralement accepté à l’époque, mais le révolutionnaire nouvel univers héliocentrique d’Aristarque. Dans un univers héliocentrique, la Terre orbite autour du soleil, auquel cas le fait que les étoiles ne montrent aucune parallaxe signifie qu’elles doivent être bien plus loin qu’Aristote n’aurait pu l’imaginer. Pour se compliquer la vie, Archimède choisit délibérément le système de coordonnées qui produirait les plus grands nombres. Nous adopterons l’approche diamétralement opposée. En créant notre univers virtuel dans l’ordinateur, nous choisirons des systèmes de coordonnées qui nous faciliteront la vie, pas nous la compliqueront.
À notre époque éclairée, nous sommes habitués à entendre dans les médias parler de relativisme culturel, qui promeut l’idée qu’il est incorrect de considérer une culture, un système de croyances ou un agenda national comme supérieur à un autre. Il n’est pas trop difficile d’étendre cela à ce que nous pourrions appeler le « relativisme transformationnel »—la thèse qu’aucun lieu, orientation ou système de coordonnées ne peut être considéré comme supérieur aux autres. Dans un certain sens c’est vrai, mais pour paraphraser George Orwell dans La Ferme des animaux : « Tous les systèmes de coordonnées sont considérés comme égaux, mais certains sont plus égaux que d’autres. » Voyons maintenant quelques exemples de systèmes de coordonnées courants que vous rencontrerez en infographie 3D.
3.2Quelques espaces de coordonnées utiles
Des espaces de coordonnées différents sont nécessaires parce que certaines informations ne sont significatives ou disponibles que dans un contexte particulier. Dans cette section, nous donnons quelques exemples d’espaces de coordonnées courants.
3.2.1L’espace monde
Les auteurs ont écrit ce livre en 2011 depuis Chicago, Illinois, et Denton, Texas. Plus précisément, leurs positions étaient celles indiquées dans Tableau 3.1.
Auteur
Ville
Latitude
Longitude
Fletcher
Chicago
41°57’
Nord
87°39’
Ouest
Ian
Denton
33°11’
Nord
97°
Ouest
Tableau 3.1Positions des auteurs, incluant un décalage aléatoire introduit pour nous protéger de nos nombreux fans trop enthousiastes.
Ces valeurs de latitude et de longitude expriment notre position « absolue » dans le monde. Vous n’avez pas besoin de savoir où se trouvent Denton, Chicago, le Texas, l’Illinois, ou même les États-Unis pour utiliser cette information car la position est absolue. L’origine, ou point , dans le monde a été décidée pour des raisons historiques : elle est située sur l’équateur à la même longitude que l’Observatoire royal de la ville de Greenwich, en Angleterre.
(Le lecteur perspicace remarquera que ces coordonnées ne sont pas des coordonnées cartésiennes, mais plutôt des coordonnées sphériques—voir Section 7.3.2. Ce n’est pas important pour cette discussion. Nous vivons dans un monde 2D plat enroulé autour d’une sphère, concept qui aurait échappé à la plupart des gens jusqu’à ce que Christophe Colomb le vérifie expérimentalement.)
Le système de coordonnées monde est un système de coordonnées particulier qui établit le référentiel « global » pour que tous les autres systèmes de coordonnées soient spécifiés. Autrement dit, nous pouvons exprimer la position d’autres espaces de coordonnées en termes de l’espace de coordonnées monde, mais nous ne pouvons pas exprimer l’espace de coordonnées monde en termes d’un espace extérieur plus grand.
Dans un sens non technique, le système de coordonnées monde établit le système de coordonnées le « plus grand » qui nous intéresse, ce qui dans la plupart des cas n’est pas réellement le monde entier. Par exemple, si nous voulions rendre une vue de Cartésia, alors Cartésia serait pour ainsi dire « le monde », puisque nous ne nous préoccuperions pas de savoir où se trouve Cartésia (ni même si elle existe réellement). Pour trouver la façon optimale de ranger des pièces automobiles dans une boîte, nous pourrions écrire une simulation physique qui « secoue » une boîte pleine de pièces jusqu’à ce qu’elles se tassent. Dans ce cas, nous confinerions notre « monde » à l’intérieur d’une boîte. Ainsi, selon les situations, l’espace de coordonnées monde définira un « monde » différent.
Nous avons dit que l’espace de coordonnées monde est utilisé pour décrire des positions absolues. Nous espérons que vous avez dressé l’oreille en entendant cela, car nous n’étions pas tout à fait honnêtes. Nous avons déjà évoqué dans Section 2.4.1 qu’il n’existe pas vraiment de « position absolue ». Dans ce livre, nous utilisons le terme « absolu » pour signifier « absolu par rapport au système de coordonnées le plus grand qui nous intéresse ». Autrement dit, « absolu » pour nous signifie en réalité « exprimé dans l’espace de coordonnées monde ».
L’espace de coordonnées monde est également connu sous le nom d’espace de coordonnées global ou universel.
3.2.2L’espace objet
L’espace objet est l’espace de coordonnées associé à un objet particulier. Chaque objet possède son propre espace objet indépendant. Lorsqu’un objet se déplace ou change d’orientation, l’espace de coordonnées objet associé à cet objet se déplace avec lui, il se déplace donc ou change d’orientation lui aussi. Par exemple, nous portons tous notre propre système de coordonnées personnel. Si nous vous demandions de « faire un pas en avant », nous vous donnons une instruction dans votre espace objet. (Veuillez nous pardonner de vous désigner comme un objet—vous voyez ce que nous voulons dire.) Nous n’avons aucune idée de la direction dans laquelle vous vous déplacerez en termes absolus. Certains d’entre vous iront vers le nord, d’autres vers le sud, et ceux portant des bottes magnétiques sur le flanc d’un bâtiment pourraient monter ! Des concepts comme « avant », « arrière », « gauche » et « droite » ont du sens dans l’espace de coordonnées objet. Lorsque quelqu’un vous donne des indications routières, on vous dira parfois « tournez à gauche » et d’autres fois « allez vers l’est ». « Tournez à gauche » est un concept exprimé dans l’espace objet, et « allez vers l’est » est exprimé dans l’espace monde.
Les positions ainsi que les directions peuvent être spécifiées dans l’espace objet. Par exemple, si je vous demandais où se trouve le silencieux de votre voiture, vous ne me répondriez pas « Cambridge,1 MA », même si vous étiez Tom ou Ray Magliozzi et que votre voiture était réellement à Cambridge. Dans ce cas, une réponse exprimée avec une perspective globale comme celle-là est totalement inutile ;2 je veux que vous exprimiez la position de votre silencieux dans l’espace objet de votre voiture.
Dans le contexte de l’infographie, l’espace objet est également appelé espace modèle, car les coordonnées des sommets d’un modèle sont exprimées dans l’espace modèle. L’espace objet est également appelé espace corps, surtout dans les contextes de physique. Il est également courant d’utiliser une expression comme « par rapport aux axes du corps », qui signifie la même chose que « exprimé en coordonnées de l’espace corps ».
3.2.3L’espace caméra
Un exemple particulièrement important d’espace objet est l’espace caméra, qui est l’espace objet associé au point de vue utilisé pour le rendu. Dans l’espace caméra, la caméra est à l’origine, avec pointant vers la droite, pointant vers l’avant (dans l’écran, la direction vers laquelle la caméra est orientée), et pointant « vers le haut ». (Pas « vers le haut » par rapport au monde, « vers le haut » par rapport au dessus de la caméra.) Figure 3.1 montre un diagramme de l’espace caméra.
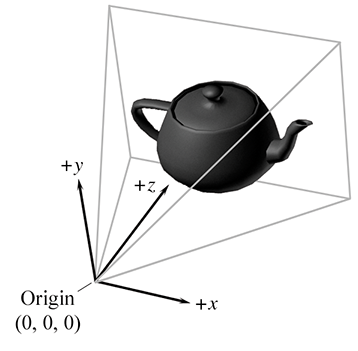
Figure 3.1Espace caméra selon les conventions main gauche
Ce sont les conventions traditionnelles main gauche ; d’autres sont courantes. En particulier, la tradition OpenGL est main droite, avec pointant dans l’écran et sortant de l’écran vers le spectateur.
Notez soigneusement les différences entre l’espace caméra, qui est un espace 3D, et l’espace écran, qui est un espace 2D. Le mappage des coordonnées de l’espace caméra vers les coordonnées de l’espace écran implique une opération connue sous le nom de projection. Nous aborderons l’espace caméra plus en détail, et ce processus de conversion en particulier, lorsque nous parlerons des espaces de coordonnées utilisés dans le rendu dans Section 10.3.
3.2.4L’espace vertical
Parfois, la bonne terminologie est la clé pour débloquer une meilleure compréhension d’un sujet. Don Knuth a inventé l’expression « nommer et conquérir » pour désigner la pratique courante et importante en mathématiques et en informatique de donner un nom à un concept fréquemment utilisé. L’objectif est d’éviter de répéter les détails de cette idée chaque fois qu’elle est invoquée, ce qui réduit l’encombrement et permet de se concentrer plus facilement sur la question plus large, dont la chose nommée n’est qu’une partie. Nous avons constaté que pour maîtriser les transformations d’espaces de coordonnées, que ce soit en communiquant avec des êtres humains via des mots ou avec des ordinateurs via du code, il est utile d’associer à chaque objet un nouvel espace de coordonnées, que nous appelons l’espace de coordonnées vertical de l’objet. L’espace vertical d’un objet est, dans un certain sens, « à mi-chemin » entre l’espace monde et son espace objet. Les axes de l’espace vertical sont parallèles aux axes de l’espace monde, mais l’ origine de l’espace vertical coïncide avec l’origine de l’espace objet. Figure 3.2 illustre ce principe en 2D. (Remarquons que nous avons fait le choix arbitraire de placer l’origine entre les pieds du robot, plutôt qu’à son centre de masse.)
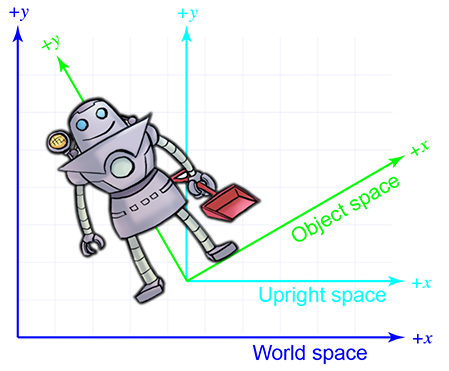
Figure 3.2Espace objet, espace vertical et espace monde.
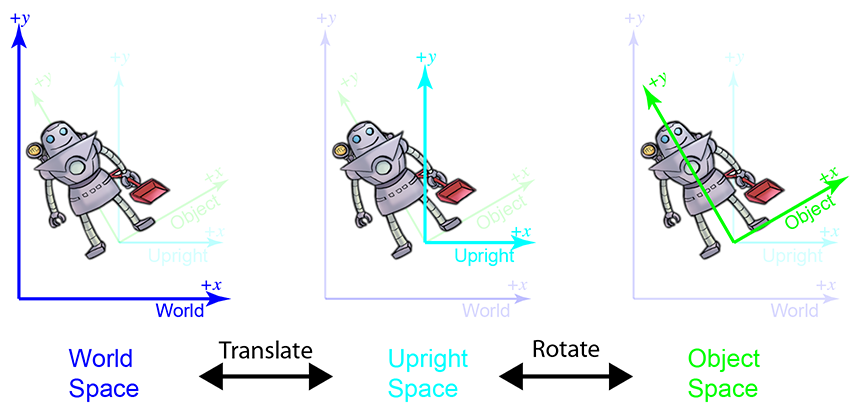
Figure 3.3 Conversion entre l’espace monde et l’espace vertical par translation ; l’espace vertical et l’espace objet sont liés par rotation
Pourquoi l’espace vertical est-il intéressant ? Transformer un point entre l’espace objet et l’espace vertical ne requiert qu’une rotation, et transformer un point entre l’espace vertical et l’espace monde ne requiert qu’un changement de position, généralement appelé translation. Il est plus facile de considérer ces deux choses indépendamment que d’essayer de les gérer toutes les deux à la fois. C’est illustré dans Figure 3.3. L’espace monde (à gauche) est transformé en espace vertical (au centre) en translatant l’origine. Pour transformer l’espace vertical en espace objet, nous faisons pivoter les axes jusqu’à ce qu’ils s’alignent avec les axes de l’espace objet. Dans cet exemple, le robot pense que son axe pointe de ses pieds vers sa tête et que son axe pointe vers sa gauche.3 Nous reviendrons à ce concept dans Section 3.3.
Le terme « vertical » est de notre invention et n’est pas (encore !) un terme standard que vous trouverez ailleurs. Mais c’est un concept puissant en quête d’un bon nom. En physique, le terme « coordonnées du centre de masse » est parfois utilisé pour décrire les coordonnées exprimées dans l’espace que nous appelons espace vertical. Dans la première édition de ce livre, nous utilisions le terme « espace inertiel » pour désigner cet espace, mais nous l’avons changé pour éviter toute confusion avec les référentiels inertiels en physique, qui ont des connotations similaires mais sont différents. Nous aurons encore quelques réflexions philosophiques sur l’espace vertical à la fin de ce chapitre.
3.3Vecteurs de base et transformations d’espaces de coordonnées
Nous avons dit qu’une justification majeure de l’existence de plus d’un espace de coordonnées est que certaines positions ou directions ne sont connues que dans un espace de coordonnées particulier. De même, parfois certaines questions ne peuvent être répondues que dans des espaces de coordonnées particuliers. Lorsque la question se pose le mieux dans un espace, et que les informations dont nous avons besoin pour y répondre sont connues dans un espace différent, nous avons un problème à résoudre.
Par exemple, supposons que notre robot tente de ramasser un sandwich au hareng dans notre monde virtuel. Nous connaissons initialement la position du sandwich et la position du robot en coordonnées monde. Les coordonnées monde peuvent être utilisées pour répondre à des questions comme « Le sandwich est-il au nord ou au sud de moi ? » Un ensemble différent de questions pourrait être répondu si nous connaissions la position du sandwich dans l’espace objet du robot—par exemple, « Le sandwich est-il devant moi ou derrière moi ? » « Dans quelle direction dois-je me tourner pour faire face au sandwich ? » « Comment dois-je déplacer ma pince à sandwich au hareng pour me positionner pour ramasser le sandwich ? » Notez que pour décider comment manipuler les engrenages et les circuits, les coordonnées de l’espace objet sont les coordonnées pertinentes. De plus, toutes les données fournies par les capteurs seraient exprimées dans l’espace objet. Bien sûr, nos propres corps fonctionnent selon des principes similaires. Nous sommes tous capables de voir une bonne bouchée devant nous et de la mettre dans notre bouche sans savoir quelle direction est le « nord ». (Et heureusement, sinon beaucoup d’entre nous mourraient de faim.)
Supposons en outre que nous souhaitons rendre une image du robot ramassant le sandwich, et que la scène est éclairée par la lumière montée sur son épaule. Nous connaissons la position de la lumière dans l’espace objet du robot, mais pour correctement éclairer la scène, nous devons connaître la position de la lumière dans l’espace monde.
Ces problèmes sont les deux faces d’une même pièce : nous savons comment exprimer un point dans un espace de coordonnées, et nous devons exprimer ce point dans un autre espace de coordonnées. Le terme technique pour ce calcul est une transformation d’espace de coordonnées. Nous devons transformer la position de l’espace monde vers l’espace objet (dans l’exemple du sandwich) ou de l’espace objet vers l’espace monde (dans l’exemple de la lumière). Notez que dans cet exemple, ni le sandwich ni la lumière ne bougent vraiment, nous exprimons simplement leurs positions dans un autre espace de coordonnées.
Le reste de cette section décrit comment effectuer des transformations d’espaces de coordonnées. Parce que ce sujet est d’une importance fondamentale, et qu’il peut être si diablement déroutant, permettez-nous de présenter une transition très progressive du niveau conceptuel chaleureux vers les mathématiques froides. Section 3.3.1 examine les transformations dans le contexte même où elles sont souvent rencontrées pour les débutants en programmation de jeux vidéo : l’infographie. À l’aide de l’exemple le plus ridicule auquel nous ayons pu penser, nous montrons le besoin fondamental des transformations, et démontrons également la dualité entre deux façons utiles de visualiser les transformations. Section 3.3.2 s’assure que nous sommes clairs sur ce que signifie spécifier un espace de coordonnées en termes d’un autre espace. Enfin, Section 3.3.3 présente l’idée clé des vecteurs de base.
3.3.1Deux perspectives
Dans notre exemple du robot, la discussion était formulée de telle sorte que le processus de transformation d’un point ne « déplaçait » pas vraiment le point, nous changions simplement notre référentiel et pouvions décrire le point à l’aide d’un espace de coordonnées différent. En fait, on pourrait dire que nous n’avons pas vraiment transformé le point, nous avons transformé l’espace de coordonnées ! Mais il existe une autre façon d’envisager les transformations d’espaces de coordonnées. Certaines personnes trouvent plus facile dans certaines situations d’imaginer que l’espace de coordonnées reste immobile tandis que le point se déplace d’un endroit à un autre. Lorsque nous développons les mathématiques pour calculer réellement ces transformations, c’est le paradigme qui est le plus naturel. Les transformations d’espaces de coordonnées sont un outil si important, et la confusion qui peut surgir d’une conscience incomplète de ces deux perspectives est si courante que nous allons consacrer un peu de temps supplémentaire à travailler sur quelques exemples.
Voici maintenant cet exemple ridicule. Supposons que nous travaillons pour une agence publicitaire qui vient de décrocher un gros contrat avec un fabricant de produits alimentaires. Nous sommes affectés au projet de créer une publicité générée par ordinateur pour l’un de leurs articles les plus populaires, les Paquets de Harengs, des produits alimentaires à base de hareng micro-ondables pour robots.

Figure 3.4 Une portion contient 100 % de l’apport journalier recommandé en huiles essentielles pour un robot.
Bien sûr, le client a tendance à vouloir des changements de dernière minute, donc nous pourrions avoir besoin de modèles du produit et du robot dans toutes les positions et orientations possibles. Notre première tentative pour y parvenir consiste à demander au département artistique le modèle du robot et le modèle du produit dans toutes les configurations possibles de positions et d’orientations. Malheureusement, ils estiment que puisqu’il s’agit d’une quantité infinie, il faudra toute l’éternité pour produire autant d’éléments, même en tenant compte de la loi de Moore et du fait que le modèle du produit n’est qu’une boîte. La directrice suggère d’augmenter l’équipe artistique pour réaliser sa vision, mais malheureusement, après avoir fait les calculs, le producteur découvre que cela ne réduit pas le temps nécessaire pour terminer le projet.4 En fait, la société peut se permettre de produire seulement un modèle de robot et une boîte de produit alimentaire à base de hareng micro-ondable.
Bien que vous puissiez regretter d’avoir passé les 60 dernières secondes de votre vie à lire le paragraphe précédent, cet exemple illustre bien la nécessité fondamentale des transformations d’espaces de coordonnées. C’est aussi une représentation relativement fidèle du processus créatif. Les estimations de temps sont toujours gonflées, les chefs de projet ajouteront des personnes dans un projet de manière désespérée, les projets doivent être terminés à une certaine date pour satisfaire un trimestre, et, ce qui est le plus pertinent pour ce livre, les artistes ne livreront qu’un modèle, nous laissant le soin de le déplacer dans le monde.
Le modèle 3D que nous obtenons de l’artiste est une représentation mathématique d’un robot. Cette description inclut probablement des points de contrôle, appelés sommets, et une sorte de description de surface, qui indique comment relier les sommets pour former la surface de l’objet. Selon les outils utilisés par l’artiste pour créer le modèle, la description de surface peut être un maillage polygonal ou une surface de subdivision. Nous ne nous préoccupons pas trop de la description de surface ici ; ce qui est important, c’est que nous pouvons déplacer le modèle en déplaçant ses sommets. Ignorons pour l’instant le fait que le robot est une créature articulée, et supposons que nous ne pouvons le déplacer dans le monde que comme une pièce d’échecs, sans l’animer.
L’artiste qui a construit notre modèle de robot a décidé (tout à fait raisonnablement) de le créer à l’origine de l’espace monde. C’est illustré dans Figure 3.5.

Figure 3.5 Le modèle du robot a été créé avec l’origine du monde à ses pieds.
Pour simplifier le reste de cet exemple, nous allons regarder les choses de dessus. Bien que ce soit essentiellement un exemple 2D, nous allons utiliser nos conventions 3D, en ignorant l’axe pour l’instant. Dans ce livre, la convention est que pointe « vers l’avant » dans l’espace objet et « vers le nord » dans l’espace vertical, tandis que pointe « vers la droite » dans l’espace objet et « vers l’est » dans l’espace vertical.
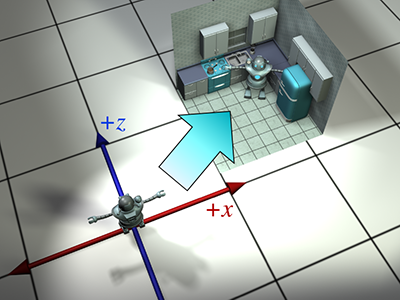
Figure 3.6Déplacer le modèle en position
Pour l’instant, parce que le modèle est dans sa position de départ, l’espace objet et l’espace monde (et l’espace vertical) sont tous identiques par définition. En pratique, dans la scène que l’artiste a construite contenant uniquement le modèle du robot, l’espace monde est l’espace objet.
| initiale |  |
| Rotation |  |
| Translation |  |
Figure 3.7Transformer le robot de l’espace objet à l’espace monde en faisant d’abord une rotation, puis une translation
Revenons à la publicité. Notre objectif est de transformer les sommets du modèle depuis leur emplacement « de départ » vers un nouvel emplacement (dans notre cas, dans une cuisine imaginaire), selon la position et l’orientation souhaitées du robot en fonction des caprices du moment, comme montré dans Figure 3.6.
Parlons un peu de la façon d’y parvenir. Nous n’entrerons pas trop dans les détails mathématiques—c’est le sujet du reste de ce chapitre. Conceptuellement, pour mettre le robot en position nous le faisons d’abord pivoter de dans le sens horaire (ou, comme nous l’apprendrons dans Section 8.3, en « tournant à gauche de »). Puis nous le translatons de 18 pieds vers l’est et 10 pieds vers le nord, ce qui, selon nos conventions, correspond à un déplacement 3D de . Cela est illustré dans Figure 3.7.
À ce stade, permettez-nous une brève digression pour répondre à une question que certains lecteurs se posent peut-être : « Faut-il obligatoirement faire la rotation d’abord, puis la translation ? » La réponse à cette question est essentiellement « oui ». Bien qu’il puisse sembler plus naturel de translater avant de faire pivoter, il est généralement plus facile de faire la rotation en premier. Voici pourquoi. Lorsque nous faisons pivoter l’objet en premier, le centre de rotation est l’origine. La rotation autour de l’origine et la translation sont deux outils primitifs dont nous disposons, et chacun est simple. (Rappelons notre motivation pour introduire l’espace vertical dans Section 3.2.4.) Si nous faisons la rotation en second, cette rotation se produira autour d’un point qui n’est pas l’origine. La rotation autour de l’origine est une transformation linéaire, mais la rotation autour de tout autre point est une transformation affine. Comme nous le montrons dans Section 6.4.3, pour effectuer une transformation affine, nous composons une séquence d’opérations primitives. Pour une rotation autour d’un point arbitraire, nous translatons le centre de rotation à l’origine, effectuons la rotation autour de l’origine, puis translatons de nouveau. Autrement dit, si nous voulons mettre le robot en place en translatant d’abord puis en faisant pivoter ensuite, nous effectuons probablement le processus suivant :
Translater d’abord, puis faire pivoter
Translater.
Faire pivoter. Puisque nous faisons pivoter autour d’un point qui n’est pas l’origine, c’est un processus en trois étapes :
a. Translater le centre de rotation à l’origine. (Cela annule l’étape 1.)
b. Effectuer la rotation autour de l’origine.
c. Translater pour remettre le centre de rotation en place.
Remarquons que les étapes 1 et 2a s’annulent mutuellement, et il nous reste les deux étapes : faire pivoter d’abord, puis translater.
 |
 |
| Vue de dessus | Vue de la caméra |
Figure 3.8La disposition de la caméra et du robot dans la scène
Nous avons donc réussi à placer le modèle du robot au bon endroit dans le monde. Mais pour le rendre, nous devons transformer les sommets du modèle en espace caméra. Autrement dit, nous devons exprimer les coordonnées des sommets par rapport à la caméra. Par exemple, si un sommet se trouve à 9 pieds devant la caméra et à 3 pieds sur la droite, alors les coordonnées et de ce sommet dans l’espace caméra seraient respectivement 9 et 3. Figure 3.8 montre un plan particulier que nous pourrions vouloir capturer. À gauche, nous voyons la disposition du plan depuis une perspective externe, et à droite ce que la caméra voit.
Il était facile de visualiser la transformation du modèle dans l’espace monde. Nous l’avons littéralement « déplacé » en position.5 Mais comment transformer de l’espace monde vers l’espace caméra ? Les objets sont tous deux déjà « en place », alors où les « déplaçons »-nous ? Pour des situations comme celle-ci, il est utile de penser à transformer l’espace de coordonnées plutôt que de transformer les objets, une technique que nous aborderons dans la section suivante. Cependant, voyons si nous pouvons garder l’espace de coordonnées fixe et atteindre quand même le résultat souhaité en ne « déplaçant que des objets ».
Lorsque nous avons transformé de l’espace objet à l’espace monde, nous avons pu le faire parce que nous imaginions le robot démarrer à l’origine dans l’espace monde. Bien sûr, le robot n’était jamais vraiment à cet endroit dans l’espace monde, mais nous l’avons imaginé. Puisque nous avons transformé de l’espace objet à l’espace monde en déplaçant l’objet, peut-être pouvons-nous transformer de l’espace monde à l’espace caméra en déplaçant le monde ! Imaginez prendre le monde entier, y compris le robot, la caméra et la cuisine, et tout déplacer. Clairement, de telles opérations n’affecteraient pas ce que la caméra « verrait », car elles ne changent pas la relation relative entre la caméra et les objets du monde. Si nous déplacions le monde et la caméra ensemble, de telle façon que la caméra se retrouve à l’origine, alors les coordonnées de l’espace monde et les coordonnées de l’espace caméra seraient identiques. Figure 3.9 montre le processus en deux étapes que nous utiliserions pour y parvenir.
| initiale | 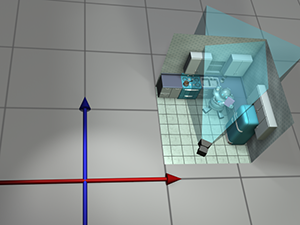 |
| Translation | 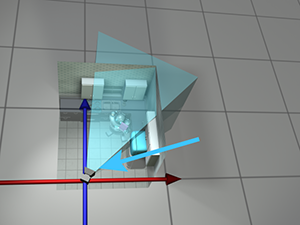 |
| Rotation |  |
Figure 3.9Transformer tout de l’espace monde à l’espace caméra en translatant, puis en faisant pivoter
Remarquons que, dans ce cas, il est plus facile de translater avant de faire pivoter. C’est parce que nous voulons faire pivoter autour de l’origine. De plus, nous utilisons les montants de translation et de rotation opposés, comparés à la position et l’orientation de la caméra. Par exemple, dans Figure 3.9 les coordonnées de la caméra sont approximativement . (Les lignes de grille représentent 10 unités.) Donc pour déplacer la caméra à l’origine, nous translatons tout de . La caméra est orientée approximativement vers le nord-est et a donc un cap horaire par rapport au nord ; une rotation antihoraire est nécessaire pour aligner les axes de l’espace caméra avec les axes de l’espace monde.
Après avoir soulevé et déplacé un robot entier dans la première étape, puis le monde entier6 dans la deuxième étape, nous avons enfin les coordonnées des sommets dans l’espace caméra, et pouvons procéder au rendu. Si tout ce déplacement imaginaire vous a épuisé, ne vous inquiétez pas ; dans un instant nous aborderons une autre façon de penser à ce processus.
Avant de continuer, quelques remarques importantes sur cet exemple. Premièrement, la transformation monde-vers-caméra est généralement effectuée dans un vertex shader ; vous pouvez laisser cela à l’API graphique si vous travaillez à un niveau élevé et n’écrivez pas vos propres shaders. Deuxièmement, l’espace caméra n’est pas la « ligne d’arrivée » du point de vue du pipeline graphique. Depuis l’espace caméra, les sommets sont transformés en espace de découpe et finalement projetés en espace écran. Ces détails sont couverts dans Section 10.2.3.
| Perspective absolue | Perspective locale | |
| du robot | 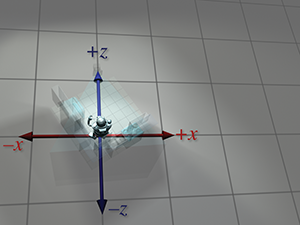 |
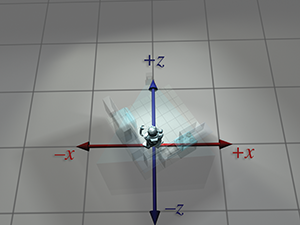 |
| du robot | 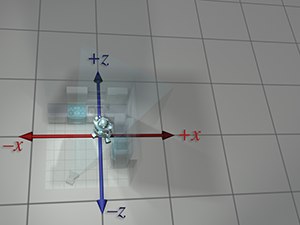 |
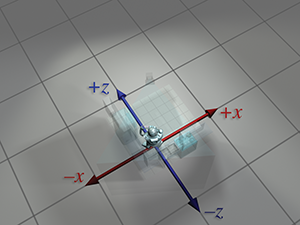 |
| monde | 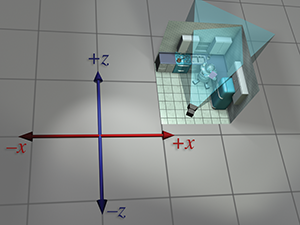 |
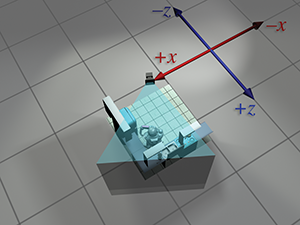 |
| de la caméra | 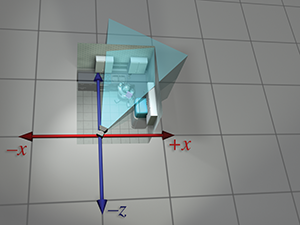 |
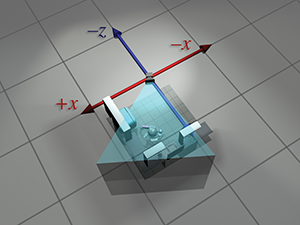 |
| caméra | 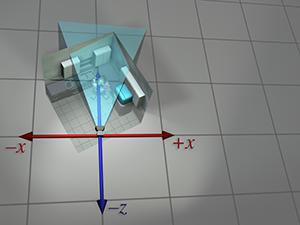 |
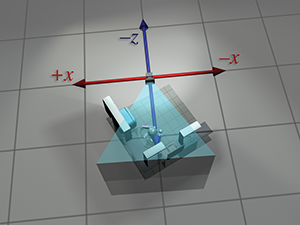 |
Figure 3.10 La même séquence de transformations d’espaces de coordonnées vue depuis deux perspectives. À gauche, il semble que les objets se déplacent et que les axes de coordonnées sont fixes. À droite, les objets semblent fixes et les axes de l’espace de coordonnées sont transformés.
Nous avons donc vu comment calculer les coordonnées de l’espace monde depuis les coordonnées de l’espace objet en imaginant déplacer le modèle depuis l’origine jusqu’à sa position dans le monde. Puis nous avons pu calculer les coordonnées de l’espace caméra depuis les coordonnées de l’espace monde en déplaçant le monde entier pour placer la caméra à l’origine. Il faut souligner que l’espace de coordonnées utilisé pour décrire les points est resté constant (même si nous l’avons appelé différemment à différents moments), tandis que nous imaginions les points se déplacer dans l’espace. Une transformation ainsi interprétée est parfois appelée transformation active.
Alternativement, nous pouvons considérer le même processus comme une transformation passive. Dans le paradigme passif, nous imaginons les points immobiles tandis que nous déplaçons l’espace de coordonnées utilisé pour les décrire. Dans les deux cas, les coordonnées des points sont les mêmes à chaque étape. Tout dépend de la façon dont nous choisissons de voir la situation. Précédemment, notre perspective était fixe avec l’espace de coordonnées, parce que nous pensions à la transformation en termes actifs. Nous montrons maintenant la perspective duale, qui est fixe par rapport à l’objet.
Figure 3.10 passe en revue la séquence en quatre étapes de l’espace objet du robot à l’espace objet de la caméra selon les deux perspectives. À gauche, nous répétons la présentation donnée précédemment, où l’espace de coordonnées est fixe et le robot se déplace. À droite, nous montrons le même processus comme une transformation passive, depuis une perspective qui reste fixe par rapport au robot. Remarquons comment l’espace de coordonnées semble se déplacer. Remarquons également que lorsque nous effectuons une certaine transformation sur les sommets, c’est équivalent à effectuer la transformation opposée sur l’espace de coordonnées. La dualité entre les transformations actives et passives est une source fréquente de confusion. Assurez-vous toujours, lorsque vous traduisez une transformation en mathématiques (ou en code), d’avoir à l’esprit si c’est l’objet ou l’espace de coordonnées qui est transformé. Nous examinons un exemple classique de cette confusion dans l’infographie dans Section 8.7.1, lorsque nous abordons la conversion des angles d’Euler en matrice de rotation correspondante.
Notez que pour plus de clarté, les deux premières lignes de Figure 3.10 ont la cuisine et la caméra principalement transparentes. En réalité, chaque objet individuel—les casseroles, le réfrigérateur, etc.—aurait pu être créé par un artiste au centre d’une scène, et conceptuellement chacun subit sa propre transformation unique de l’espace objet à l’espace monde.
Nous avons évoqué deux façons utiles d’imaginer les transformations d’espaces de coordonnées. Une façon est de fixer notre perspective avec l’espace de coordonnées. C’est le paradigme de la transformation active : les vecteurs et les objets se déplacent à mesure que leurs coordonnées changent. Dans le paradigme de la transformation passive, nous gardons notre perspective fixe par rapport à l’objet transformé, ce qui donne l’impression que nous transformons l’espace de coordonnées utilisé pour mesurer les coordonnées. Transformer un objet a le même effet sur les coordonnées que d’effectuer la transformation opposée sur l’espace de coordonnées. Les paradigmes actif et passif sont tous deux très utiles, et une appréciation insuffisante de la différence entre eux est une cause courante d’erreurs.
3.3.2Spécifier les espaces de coordonnées
Nous sommes presque prêts à parler des transformations. Mais il y a en réalité encore une question fondamentale à laquelle il faut répondre : comment précisément spécifions-nous un espace de coordonnées par rapport à un autre espace de coordonnées ?7 Rappelons de Section 1.2.2 qu’un système de coordonnées est défini par son origine et ses axes. L’origine définit la position de l’espace de coordonnées, et les axes décrivent son orientation. (En fait, les axes peuvent décrire d’autres informations, comme l’échelle et le cisaillement. Pour l’instant, nous supposons que les axes sont perpendiculaires et que les unités utilisées par les axes sont les mêmes que les unités utilisées par l’espace de coordonnées parent.) Donc si nous trouvons un moyen de décrire l’origine et les axes, nous avons entièrement documenté l’espace de coordonnées.
Spécifier la position de l’espace de coordonnées est simple. Tout ce que nous devons faire est de décrire l’emplacement de l’origine. Nous faisons cela exactement comme pour n’importe quel autre point. Bien sûr, nous devons exprimer ce point par rapport à l’espace de coordonnées parent, pas à l’espace enfant local. L’origine de l’espace enfant, par définition, est toujours lorsqu’exprimée dans l’espace de coordonnées enfant. Par exemple, considérons la position du robot 2D dans Figure 3.2. Pour établir une échelle pour le diagramme, disons que le robot mesure environ 1,65 m. Alors les coordonnées monde de son origine sont proches de .
Spécifier l’orientation d’un espace de coordonnées en 3D est légèrement plus complexe. Les axes sont des vecteurs (des directions), et peuvent être spécifiés comme n’importe quel autre vecteur direction. En revenant à notre exemple du robot, nous pourrions décrire son orientation en indiquant les directions vers lesquelles pointent les vecteurs verts étiquetés et —ce sont les axes de l’espace objet du robot. (En réalité, nous utiliserions des vecteurs de longueur unitaire. Les axes dans les diagrammes ont été dessinés aussi grands que possible, mais, comme nous le verrons dans un instant, des vecteurs unitaires sont généralement utilisés pour décrire les axes.) Tout comme pour la position, nous n’utilisons pas l’espace objet lui-même pour décrire les directions des axes de l’espace objet, car ces coordonnées sont et par définition. Au lieu de cela, les coordonnées sont spécifiées dans l’espace vertical. Dans cet exemple, les vecteurs unitaires dans les directions et de l’espace objet ont des coordonnées de l’espace vertical de et , respectivement.
Ce que nous venons de décrire est une façon de spécifier l’orientation d’un espace de coordonnées, mais il en existe d’autres. Par exemple, en 2D, plutôt que de lister deux vecteurs 2D, nous pourrions donner un seul angle. (Les axes objet du robot sont tournés de dans le sens horaire par rapport aux axes verticaux.) En 3D, décrire l’orientation est considérablement plus complexe, et nous avons en fait consacré tout le Chapitre 8 à ce sujet.
Nous spécifions un espace de coordonnées en décrivant son origine et ses axes. L’origine est un point qui définit la position de l’espace et peut être décrite comme n’importe quel autre point. Les axes sont des vecteurs et décrivent l’orientation de l’espace (et éventuellement d’autres informations comme l’échelle), et les outils habituels pour décrire les vecteurs peuvent être utilisés. Les coordonnées que nous utilisons pour mesurer l’origine et les axes doivent être relatives à un autre espace de coordonnées.
3.3.3Vecteurs de base
Nous sommes maintenant prêts à calculer concrètement des transformations d’espaces de coordonnées. Commençons par un exemple 2D concret. Disons que nous devons connaître les coordonnées monde de la lumière fixée sur l’épaule droite du robot. Nous partons des coordonnées de l’espace objet, qui sont . Comment obtenir les coordonnées monde ? Pour ce faire, nous devons revenir au début et approfondir certaines idées si fondamentales qu’on les tient pour acquises. Comment localisons-nous un point indiqué par un ensemble donné de coordonnées cartésiennes ? Disons que nous devons donner des instructions pas à pas pour localiser la lumière à quelqu’un qui ne sait pas comment fonctionnent les coordonnées cartésiennes. Nous dirions :
Partir de l’origine.
Se déplacer d’1 pied vers la droite.
Se déplacer de 5 pieds vers le haut.
Nous supposons que cette personne a un mètre ruban, et comprend que lorsque nous disons « droite » et « haut », nous désignons la « droite » et le « haut » du robot, les directions que nous, les gens éclairés, savons être parallèles aux axes de l’espace objet.
Voici le point clé : nous savons déjà comment décrire l’origine, la direction appelée « la droite du robot », et la direction appelée « le haut du robot » en coordonnées monde ! Ce sont des éléments de la spécification de l’espace de coordonnées, que nous venons de donner dans la section précédente. Donc tout ce que nous avons à faire est de suivre nos propres instructions, et à chaque étape, garder une trace des coordonnées monde. Examinez à nouveau Figure 3.2.
Partir de l’origine. Pas de problème, nous avons précédemment déterminé que son origine se trouvait à
Se déplacer d’1 pied vers la droite. Nous savons que le vecteur « la gauche du robot » est , donc nous mettons cette direction à l’échelle par la distance de unité, et nous ajoutons le déplacement à notre position, pour obtenir
Se déplacer de 5 pieds vers le haut. Une fois encore, nous savons que la direction « haut du robot » est , donc nous la mettons à l’échelle par 5 unités et l’ajoutons au résultat, ce qui donne
Si vous regardez à nouveau Figure 3.2, vous verrez qu’en effet, les coordonnées monde de la lumière sont approximativement .
Maintenant, supprimons les nombres spécifiques à cet exemple et formulons des énoncés plus abstraits. Soit un point arbitraire dont les coordonnées de l’espace corps sont connues. Soit les coordonnées monde de ce même point. Nous connaissons les coordonnées monde de l’origine et les directions gauche et haut, que nous notons respectivement et . Alors peut être calculé par
Soyons encore plus généraux. Pour ce faire, il sera très utile de retirer la translation de notre considération. Une façon de faire est d’abandonner les « points » et de penser exclusivement aux vecteurs, qui, en tant qu’entités géométriques, n’ont pas de position (seulement une norme et une direction) ; ainsi la translation n’a pas vraiment de signification pour eux. Alternativement, nous pouvons simplement restreindre l’origine de l’espace objet à être la même que l’origine de l’espace monde.
Rappelons que dans Section 2.3.1 nous avons expliqué comment tout vecteur peut être décomposé géométriquement en une séquence de déplacements alignés sur les axes. Ainsi, un vecteur arbitraire peut être écrit sous forme « développée » comme
Exprimer un vecteur 3D comme une combinaison linéaire de vecteurs de base
Ici, , et sont des vecteurs de base pour l’espace 3D. Le vecteur peut avoir n’importe quelle norme et direction possible, et nous pourrions déterminer de façon unique les coordonnées , , (sauf si , et sont mal choisis ; nous abordons ce point clé dans un moment). Équation (3.2) exprime comme une combinaison linéaire des vecteurs de base.
Voici une façon courante, mais un peu incomplète, de penser aux vecteurs de base : la plupart du temps, , et ; dans d’autres circonstances inhabituelles, , et ont des coordonnées différentes. Ce n’est pas tout à fait exact. Lorsqu’on réfléchit à , et , nous devons distinguer entre les vecteurs en tant qu’entités géométriques (précédemment, et étaient les directions physiques de « gauche » et de « haut ») et les coordonnées particulières utilisées pour décrire ces vecteurs. Le premier est intrinsèquement immuable ; le second dépend du choix de la base. De nombreux livres soulignent cela en définissant tous les vecteurs en termes de « vecteurs de base du monde », souvent notés , et et interprétés comme des entités géométriques élémentaires qui ne peuvent pas être décomposées davantage. Ils n’ont pas de « coordonnées », bien que certains axiomes soient considérés comme vrais, comme . Dans ce cadre, un triplet de coordonnées est une entité mathématique, qui n’a pas de signification géométrique jusqu’à ce que nous prenions la combinaison linéaire . Maintenant, en réponse à l’affirmation , on pourrait argumenter que puisque est une entité géométrique, elle ne peut pas être comparée à un objet mathématique, de la même façon que l’équation « » est un non-sens. Parce que les lettres , et portent cette lourde connotation élémentaire, nous utilisons à la place les symboles moins présomptueux , et , et chaque fois que nous utilisons ces symboles pour nommer nos vecteurs de base, le message est : « nous les utilisons comme vecteurs de base pour l’instant, mais nous pourrions savoir comment exprimer , , par rapport à une autre base, ils ne sont donc pas nécessairement la base « racine ». »
Les coordonnées de , et sont toujours égales à , et , respectivement, lorsqu’elles sont exprimées dans l’espace de coordonnées dont ils sont la base, mais par rapport à une autre base ils auront des coordonnées arbitraires. Lorsque nous disons que nous utilisons la base standard, cela équivaut à dire que nous ne nous préoccupons que d’un seul espace de coordonnées. Ce que nous appelons cet espace de coordonnées n’a aucune importance, car nous n’avons aucun moyen de faire référence à un autre espace de coordonnées sans introduire des vecteurs de base. Lorsque nous considérons une base alternative, nous avons implicitement introduit un autre espace de coordonnées : l’espace utilisé pour mesurer les coordonnées des vecteurs de base !
Les coordonnées des vecteurs de base sont mesurées dans un référentiel différent de celui pour lequel ils constituent une base. Ainsi les vecteurs de base sont intimement liés aux transformations d’espaces de coordonnées.
Nous avons dit plus tôt que , et pouvaient être mal choisis. Cela soulève la question : qu’est-ce qui fait une bonne base ? Nous avons l’habitude d’avoir des vecteurs de base qui sont mutuellement perpendiculaires. Nous avons aussi l’habitude qu’ils aient la même longueur : nous attendons que les déplacements et aillent dans des directions différentes, mais nous supposerions normalement qu’ils ont la même longueur. Enfin, lorsque plusieurs espaces de coordonnées sont impliqués, nous avons également l’habitude qu’ils aient tous la même échelle. C’est-à-dire que le vecteur a la même norme numérique, quel que soit le système de coordonnées utilisé pour le mesurer. Mais comme nous allons le voir, ce n’est pas nécessairement le cas. Ces propriétés sont certainement souhaitables ; en fait, nous pourrions dire que c’est la « meilleure base » dans de nombreux cas. Mais elles peuvent ne pas toujours être immédiatement disponibles, elles ne sont souvent pas nécessaires, et il existe des situations pour lesquelles nous choisissons délibérément des vecteurs de base sans ces propriétés.
Nous mentionnons brièvement ici deux exemples, tous deux du domaine de l’infographie. Imaginez que nous voulions animer un mouvement d’écrasement ou d’étirement de notre modèle de robot. Pour ce faire, nous modifierions l’espace de coordonnées utilisé pour interpréter les coordonnées de nos sommets. Nous animerons les vecteurs de base de l’espace objet du robot, probablement de manière à ce qu’ils aient des longueurs différentes les uns des autres ou cessent d’être perpendiculaires. Pendant que nous écrasions ou étirions les vecteurs de l’espace objet, les coordonnées de l’espace objet des sommets restent constantes, mais les coordonnées de l’espace caméra résultantes changent, produisant l’animation souhaitée.
Un autre exemple apparaît avec les vecteurs de base pour le placage de texture. (Nous anticipons un peu, puisque nous ne parlerons pas de placage de texture avant Section 10.5 ; cependant, nous sommes conscients que nos lecteurs ne sont pas une tabula rasa, et nous supposons que vous avez au moins entendu parler de ces concepts. Nous sommes également conscients que de nombreux lecteurs ont eu leur première introduction au terme vecteur de base dans le contexte du bump mapping ; cet exemple aidera à placer cette utilisation particulière du terme dans son contexte approprié.) Il est souvent utile d’établir un espace de coordonnées local sur la surface d’un objet où un axe (nous utiliserons ) est parallèle à la normale de surface, et les autres axes pointent dans la direction des et croissants dans la texture. Ces deux derniers vecteurs de base sont parfois appelés tangente et binormale. Un mouvement en espace 3D dans la direction du vecteur de base tangente correspond à un mouvement horizontal dans l’espace image 2D de la texture, tandis qu’un déplacement en espace 3D dans la direction de la binormale correspond à un déplacement vertical dans l’espace image. Le fait essentiel est que la texture 2D plane doit souvent être déformée pour s’enrouler autour d’une surface irrégulière, et les vecteurs de base ne sont pas garantis d’être perpendiculaires.8
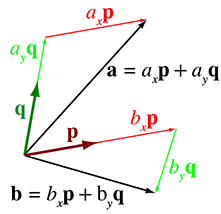
Figure 3.11Les vecteurs de base n’ont pas besoin d’être perpendiculaires.
Figure 3.11 montre une situation dans laquelle les vecteurs de base et ont la même longueur, mais ne sont pas perpendiculaires. Bien que nous n’ayons montré que deux vecteurs d’exemple, et , l’ensemble des vecteurs pouvant être décrits comme une combinaison linéaire remplissent un plan infini, et pour tout vecteur dans ce plan, les coordonnées sont uniquement déterminées.
L’ensemble des vecteurs pouvant être exprimés comme une combinaison linéaire des vecteurs de base est appelé l’espace engendré par la base. Dans l’exemple de Figure 3.11, l’espace engendré est un plan 2D infini. Cela pourrait sembler au premier abord être le seul scénario possible, mais examinons des situations plus intéressantes. Premièrement, notez que nous avons dit que les vecteurs remplissent « un » plan infini, et non « le » plan. Le fait que nous ayons deux coordonnées et deux vecteurs de base ne signifie pas que et doivent être des vecteurs 2D ! Ils pourraient être des vecteurs 3D, auquel cas leur espace engendré sera un certain plan arbitraire dans l’espace 3D, tel que représenté dans Figure 3.12.
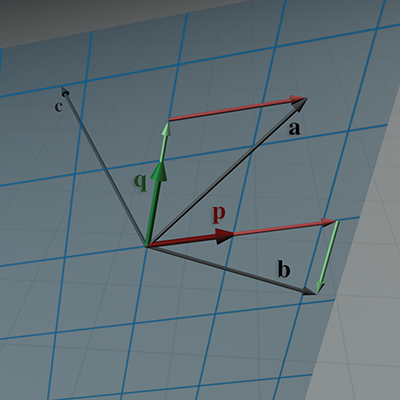
Figure 3.12 Les deux vecteurs de base et engendrent un sous-ensemble 2D de l’espace 3D.
Figure 3.12 illustre plusieurs points clés. Remarquons que nous avons choisi et avec les mêmes coordonnées que dans Figure 3.11, du moins par rapport aux vecteurs de base et . Deuxièmement, lorsque nous travaillons dans l’espace de et , nos vecteurs d’exemple et sont des vecteurs 2D ; ils n’ont que deux coordonnées, et . Nous pourrions également être intéressés par leurs coordonnées « monde » 3D ; celles-ci s’obtiennent simplement en développant la combinaison linéaire ; le résultat de cette expression est un vecteur 3D.
Considérons le vecteur , qui se trouve derrière le plan dans Figure 3.12. Ce vecteur n’est pas dans l’espace engendré par et , ce qui signifie que nous ne pouvons pas l’exprimer comme une combinaison linéaire de la base. Autrement dit, il n’existe pas de coordonnées telles que .
Le terme utilisé pour décrire le nombre de dimensions de l’espace engendré par la base est le rang de la base. Dans les deux exemples précédents, nous avons deux vecteurs de base qui engendrent un espace bidimensionnel. Clairement, si nous avons vecteurs de base, le mieux que nous puissions espérer est le rang plein, ce qui signifie que l’espace engendré est un espace à dimensions. Mais est-il possible que le rang soit inférieur à ? Par exemple, si nous avons trois vecteurs de base, est-il possible que l’espace engendré par ces vecteurs de base ne soit que 2D ou 1D ? La réponse est « oui », et cette situation correspond à ce que nous entendions précédemment par « mauvais choix » de vecteurs de base.
Par exemple, disons que nous ajoutons un troisième vecteur de base à notre ensemble et . Si se trouve dans l’espace engendré par et (par exemple, si nous choisissions ou comme troisième vecteur de base), alors les vecteurs de base sont linéairement dépendants, et n’ont pas le rang plein. L’ajout de ce dernier vecteur ne nous a pas permis de décrire des vecteurs qui ne pouvaient pas déjà être décrits avec simplement et . De plus, maintenant les coordonnées pour un vecteur donné dans l’espace engendré par la base ne sont pas uniquement déterminées. Les vecteurs de base engendrent un espace avec seulement deux degrés de liberté, mais nous avons trois coordonnées. Le blâme ne retombe pas particulièrement sur , il se trouve juste être le nouveau venu. Nous aurions pu choisir n’importe quelle paire de vecteurs parmi , , et , comme base valide pour ce même espace. Le problème de la dépendance linéaire est un problème avec l’ensemble dans son ensemble, pas seulement avec un vecteur particulier. En revanche, si notre troisième vecteur de base était choisi comme étant tout autre vecteur ne se trouvant pas dans le plan engendré par et (par exemple, le vecteur ), alors la base serait linéairement indépendante et aurait le rang plein. Si un ensemble de vecteurs de base est linéairement indépendant, il n’est pas possible d’exprimer un vecteur de base comme une combinaison linéaire des autres.
Donc un ensemble de vecteurs linéairement dépendants est certainement un mauvais choix pour une base. Mais il y a d’autres propriétés plus contraignantes que nous pourrions souhaiter d’une base. Pour le voir, revenons aux transformations d’espaces de coordonnées. Supposons, comme précédemment, que nous avons un objet dont les vecteurs de base sont , et , et que nous connaissons les coordonnées de ces vecteurs dans l’espace monde. Soit les coordonnées d’un vecteur arbitraire dans l’espace corps, et les coordonnées de ce même vecteur dans l’espace vertical. D’après notre exemple du robot, nous connaissons déjà la relation entre et :
Assurez-vous de comprendre la relation entre ces équations et Équation (3.1) avant de continuer.
Voici maintenant le problème clé : que faire si est connu et est le vecteur que nous cherchons à déterminer ? Pour illustrer la profonde différence entre ces deux questions, écrivons les deux systèmes côte à côte, en remplaçant le vecteur inconnu par « ? » :
Le système d’équations à gauche n’est pas vraiment un « système » du tout, c’est juste une liste ; chaque équation est indépendante, et chaque quantité inconnue peut être immédiatement calculée à partir d’une seule équation. À droite, cependant, nous avons trois équations interdépendantes, et aucune des quantités inconnues ne peut être déterminée sans les trois équations. En fait, si les vecteurs de base sont linéairement dépendants, le système de droite peut avoir zéro solution ( n’est pas dans l’espace engendré), ou il pourrait avoir une infinité de solutions ( est dans l’espace engendré et les coordonnées ne sont pas uniquement déterminées). Nous nous empressons d’ajouter que la distinction critique n’est pas entre l’espace vertical et l’espace corps ; nous utilisons simplement ces espaces pour avoir un exemple concret. Ce qui importe, c’est de savoir si les coordonnées connues du vecteur à transformer sont exprimées par rapport à la base (la situation facile à gauche), ou si les coordonnées du vecteur et les vecteurs de base sont tous exprimés dans le même espace de coordonnées (la situation difficile à droite).
L’algèbre linéaire fournit un certain nombre d’outils généraux pour résoudre des systèmes d’équations linéaires comme celui-ci, mais nous n’avons pas besoin de nous plonger dans ces sujets, car la résolution de ce système n’est pas notre objectif principal. Pour l’instant, nous nous intéressons à comprendre une situation particulière pour laquelle la solution est simple. (Dans Section 6.2, nous montrons comment utiliser l’inverse matricielle pour résoudre le cas général.)
Le produit scalaire est la clé. Rappelons de Section 2.11.2 que le produit scalaire peut être utilisé pour mesurer une distance dans une direction particulière. Comme nous l’avons observé dans cette même section, lorsque nous utilisons la base standard , et , correspondant au cas où les axes objet sont parallèles aux axes monde dans notre exemple du robot, nous pouvons calculer le produit scalaire du vecteur avec un vecteur de base pour « extraire » la coordonnée correspondante.
Algébriquement, c’est assez évident. Mais cette action d’« extraction » fonctionne-t-elle pour une base arbitraire ? Parfois, mais pas toujours. En fait, nous pouvons voir qu’elle ne fonctionne pas pour l’exemple que nous avons utilisé. Figure 3.13 compare les coordonnées correctes et avec les produits scalaires et . (L’illustration n’est entièrement correcte que si et sont des vecteurs unitaires.)
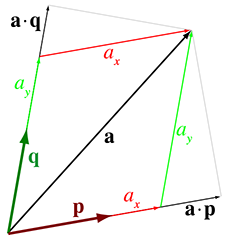
Figure 3.13 Le produit scalaire n’« extrait » pas la coordonnée dans ce cas.
Remarquons que, dans chaque cas, le résultat produit par le produit scalaire est plus grand que la valeur de coordonnée correcte. Pour comprendre ce qui ne va pas, nous devons revenir en arrière et corriger un petit mensonge que nous avons dit dans Chapitre 1. Nous avons dit qu’une coordonnée mesure le déplacement depuis l’origine dans une direction donnée ; c’est exactement ce que le produit scalaire mesure. Bien que ce soit la façon la plus simple d’expliquer les coordonnées, cela ne fonctionne que dans des circonstances particulières. (Notre mensonge n’est pas trop nuisible parce que ces circonstances sont très courantes !) Maintenant que nous comprenons les vecteurs de base, nous sommes prêts pour la description plus complète.
Les coordonnées numériques d’un vecteur par rapport à une base donnée sont les coefficients dans le développement de ce vecteur comme combinaison linéaire des vecteurs de base. Par exemple, .
La raison pour laquelle le produit scalaire n’« extrait » pas les coordonnées dans Figure 3.13 est que nous ignorons le fait que va causer un certain déplacement parallèle à . Pour visualiser cela, imaginez que nous augmenterions tout en maintenant constant. Tandis que se déplace vers la droite et légèrement vers le haut, sa projection sur , mesurée par le produit scalaire, augmente.
Le problème est que les vecteurs de base ne sont pas perpendiculaires. Un ensemble de vecteurs de base mutuellement perpendiculaires est appelé une base orthogonale.
Lorsque les vecteurs de base sont orthogonaux, les coordonnées sont découplées. Toute coordonnée donnée d’un vecteur peut être déterminée uniquement à partir de et du vecteur de base correspondant. Par exemple, nous pouvons calculer en ne connaissant que , à condition que les autres vecteurs de base soient perpendiculaires à .
Bien que nous n’approfondissions pas ce sujet dans ce livre, l’idée de base orthonormée est d’une puissance étendue avec des applications au-delà de nos préoccupations immédiates. Par exemple, c’est l’idée à la base de l’analyse de Fourier.
S’il est bien que les vecteurs de base soient orthogonaux, c’est mieux s’ils ont tous une longueur unitaire. Un tel ensemble de vecteurs est appelé une base orthonormée. Pourquoi la longueur unitaire est-elle utile ? Rappelons la définition géométrique du produit scalaire : est égal à la longueur signée de projetée sur , multipliée par la longueur de . Si le vecteur de base n’a pas de longueur unitaire, mais est perpendiculaire à tous les autres, nous pouvons quand même déterminer la coordonnée correspondante avec le produit scalaire ; nous devons juste diviser par le carré de la longueur du vecteur de base.
Dans une base orthonormée, chaque coordonnée d’un vecteur est le déplacement signé de mesuré dans la direction du vecteur de base correspondant. Cela peut être calculé directement en prenant le produit scalaire de avec ce vecteur de base.
Ainsi, dans la circonstance particulière d’une base orthonormée, nous avons un moyen simple de déterminer les coordonnées de l’espace corps, en ne connaissant que les coordonnées monde des axes du corps. Ainsi, en supposant que , et forment une base orthonormée,
Bien que notre exemple utilise l’espace corps et l’espace vertical pour la concrétude, ce sont des idées générales qui s’appliquent à toute transformation d’espace de coordonnées.
Les bases orthonormées sont les circonstances particulières dans lesquelles notre mensonge de Chapitre 1 est inoffensif ; heureusement, elles sont extrêmement courantes. Au début de cette section, nous avons mentionné que la plupart des espaces de coordonnées auxquels nous sommes « habitués » ont certaines propriétés. Tous ces espaces de coordonnées « habituels » ont une base orthonormée, et en fait ils satisfont une restriction encore plus forte : l’espace de coordonnées n’est pas en miroir. C’est-à-dire que , et les axes respectent les conventions de chiralité en vigueur (dans ce livre, nous utilisons les conventions main gauche). Une base en miroir où peut toujours être une base orthonormée.
3.4Espaces de coordonnées imbriqués
Chaque objet dans un univers virtuel 3D a son propre espace de coordonnées—sa propre origine et ses propres axes. Son origine pourrait être placée à son centre de masse, par exemple. Ses axes spécifient les directions qu’il considère comme « haut », « droite » et « avant » par rapport à son origine. Un modèle 3D créé par un artiste pour un monde virtuel aura son origine et ses axes décidés par l’artiste, et les points qui constituent le maillage polygonal seront relatifs à l’espace objet défini par cette origine et ces axes. Par exemple, le centre d’un mouton pourrait être placé à , le bout de son museau à , le bout de sa queue à et le bout de son oreille droite à . Ce sont les positions de ces parties dans l’espace mouton.
La position et l’orientation d’un objet à un moment donné doivent être spécifiées en coordonnées monde afin que nous puissions calculer les interactions entre les objets proches. Pour être précis, nous devons spécifier la position et l’orientation des axes de l’objet en coordonnées monde. Pour spécifier la position de la ville de Cartésia (voir Section 1.2.1) dans l’espace monde, nous pourrions indiquer que l’origine est à la longitude et à la latitude et que l’axe positif pointe vers l’est et l’axe positif pointe vers le nord. Pour localiser le mouton dans un monde virtuel, il suffit de spécifier la position de son origine et l’orientation de ses axes dans l’espace monde. La position mondiale du bout de son museau, par exemple, peut être déterminée à partir de la position relative de son museau par rapport aux coordonnées monde de son origine. Mais si le mouton n’est pas réellement dessiné, nous pouvons économiser des efforts en ne gardant une trace que de la position et de l’orientation de son espace objet dans l’espace monde. Il devient nécessaire de calculer les coordonnées monde de son museau, de sa queue et de son oreille droite seulement à certains moments—par exemple, lorsqu’il entre dans le champ de vision de la caméra.
Puisque l’espace objet se déplace dans l’espace monde, il est pratique de voir l’espace monde comme un espace « parent », et l’espace objet comme un espace « enfant ». Il est également pratique de décomposer les objets en sous-objets et de les animer indépendamment. Un modèle décomposé en une hiérarchie comme celle-ci est parfois appelé un modèle articulé. Par exemple,
à mesure que le mouton marche, sa tête se balance d’avant en arrière et ses oreilles battent de haut en bas. Dans l’espace de coordonnées de la tête du mouton, les oreilles semblent battre de haut en bas—le mouvement n’est que sur l’axe et est donc relativement facile à comprendre et à animer. Dans l’espace de coordonnées du mouton, sa tête se balance d’un côté à l’autre le long de l’axe du mouton, ce qui est de nouveau relativement facile à comprendre. Supposons maintenant que le mouton se déplace le long de l’axe du monde. Chacune des trois actions—les oreilles qui battent, la tête qui se balance et le mouton qui avance—implique un seul axe et est facile à comprendre isolément des autres. Le mouvement du bout de l’oreille droite du mouton, cependant, trace un chemin complexe à travers l’espace de coordonnées monde, un véritable cauchemar pour un programmeur à calculer de zéro. En décomposant le mouton en une séquence hiérarchique d’objets avec des espaces de coordonnées imbriqués, cependant, le mouvement peut être calculé en composantes séparées et combiné relativement facilement avec des outils d’algèbre linéaire tels que les matrices et les vecteurs, comme nous le verrons dans les chapitres suivants.
Par exemple, disons que nous devons connaître les coordonnées monde du bout de l’oreille du mouton. Pour calculer ces coordonnées, nous utiliserions d’abord ce que nous savons sur la relation de l’oreille du mouton par rapport à sa tête pour calculer les coordonnées de ce point dans « l’espace tête ». Ensuite, nous utilisons la position et l’orientation de la tête par rapport au corps pour calculer les coordonnées dans « l’espace corps ». Enfin, puisque nous connaissons la position et l’orientation du corps du mouton par rapport à l’origine et aux axes du monde, nous pouvons calculer les coordonnées dans l’espace monde. Les prochains chapitres approfondiront les détails de la façon de procéder.
Il est pratique de penser à l’espace de coordonnées du mouton se déplaçant par rapport à l’espace monde, à l’espace de coordonnées de la tête du mouton se déplaçant par rapport à l’espace du mouton, et à l’espace de l’oreille du mouton se déplaçant par rapport à l’espace de la tête du mouton. Ainsi, nous voyons l’espace tête comme un enfant de l’espace mouton, et l’espace oreille comme un enfant de l’espace tête. L’espace objet peut être divisé en de nombreux sous-espaces différents à de nombreux niveaux différents, selon la complexité de l’objet animé. Nous pouvons dire que l’espace de coordonnées enfant est imbriqué dans l’espace de coordonnées parent. Cette relation parent-enfant entre espaces de coordonnées définit une hiérarchie, ou arbre, d’espaces de coordonnées. L’espace de coordonnées monde est la racine de cet arbre. L’arbre d’espaces de coordonnées imbriqués peut changer dynamiquement pendant la durée de vie d’un monde virtuel ; par exemple, la toison du mouton peut être tondue et retirée du mouton, et ainsi l’espace de coordonnées de la toison passe d’être un enfant de l’espace de coordonnées du corps du mouton à être un enfant de l’espace monde. La hiérarchie des espaces de coordonnées imbriqués est dynamique et peut être organisée de la manière la plus pratique pour les informations qui nous importent.
3.5En défense de l’espace vertical
Enfin, permettez-nous quelques paragraphes pour essayer de vous convaincre que le concept d’espace vertical est très utile, même si le terme n’est peut-être pas standard. Beaucoup9 de personnes ne prennent pas la peine de distinguer entre l’espace monde et l’espace vertical. Elles parleraient simplement de la rotation d’un vecteur de l’espace objet vers « l’espace monde ». Mais considérons la situation courante dans le code lorsque le même type de données, disons float3, est utilisé pour stocker à la fois des « points » et des « vecteurs ». (Voir Section 2.4 si vous ne vous souvenez plus pourquoi ces termes ont été mis entre guillemets.) Disons que nous avons un float3 qui représente la position d’un sommet dans l’espace objet, et nous voulons connaître la position de ce sommet dans l’espace monde. La transformation de l’espace objet vers l’espace monde doit impliquer une translation par la position de l’objet. Comparons cela à un float3 différent qui décrit une direction, comme une normale de surface ou la direction vers laquelle pointe un canon. La conversion des coordonnées du vecteur direction de l’espace objet vers « l’espace monde » (ce que nous appellerions « espace vertical ») ne devrait pas contenir cette translation.
Lorsque vous communiquez vos intentions à une personne, parfois l’autre personne est capable de comprendre ce que vous voulez dire et de déduire si la translation se produit ou non quand vous dites « espace monde ». C’est parce qu’elle peut visualiser ce dont vous parlez et sait implicitement si la grandeur transformée est un « point » ou un « vecteur ». Mais un ordinateur n’a pas cette intuition, donc nous devons trouver un moyen d’être explicite. Une stratégie pour communiquer cela explicitement à un ordinateur est d’utiliser deux types de données différents, par exemple, une classe nommée Point3 et une autre nommée Vector3. L’ordinateur saurait que les vecteurs ne devraient jamais être traduits mais les points devraient l’être, car vous écririez deux routines de transformation différentes. C’est une stratégie adoptée dans certaines sources d’origine académique, mais dans le code de production du secteur du jeu, elle n’est pas courante. (Elle ne fonctionne pas non plus vraiment bien en HLSL/Cg, qui encourage fortement l’utilisation du type générique float3.) Donc nous devons trouver une autre façon de communiquer à l’ordinateur si, lors de la transformation d’un float3 donné de l’espace objet vers « l’espace monde », la translation doit se produire.
Ce qui semble être la norme dans beaucoup de code de jeu est d’avoir simplement des détails de calcul vectoriel éparpillés partout, qui multiplient par une matrice de rotation (ou son inverse) et ont explicitement (ou n’ont pas) une addition ou soustraction de vecteur, selon le cas. Nous préconisons de donner un nom à cet espace intermédiaire pour le différencier de « l’espace monde », afin de faciliter l’écriture de code utilisant des mots lisibles par les humains comme « objet », « vertical » et « monde », plutôt que des tokens mathématiques explicites comme « ajouter », « soustraire » et « inverse ». Nous avons constaté que ce type de code est plus facile à lire et à écrire. Nous espérons également que cette terminologie rendra ce livre plus facile à lire ! Décidez vous-même si notre terminologie vous est utile, mais veuillez vous assurer de lire le reste de notre petite croisade pour un code plus lisible par les humains dans Section 8.2.1.
Exercices
Dans quel espace de coordonnées (objet, vertical, caméra ou monde) est-il le plus approprié de poser les questions suivantes ?
(a) Mon ordinateur est-il devant moi ou derrière moi ?
(b) Le livre est-il à l’est ou à l’ouest de moi ?
(c) Comment aller d’une pièce à une autre ?
(d) Puis-je voir mon ordinateur ?
Supposons que les axes monde sont transformés en nos axes objet en les faisant pivoter dans le sens antihoraire autour de l’axe de 42°, puis en les translatant de 6 unités le long de l’axe et de 12 unités le long de l’axe . Décrivez cette transformation du point de vue d’un point sur l’objet.
Pour les ensembles de vecteurs de base suivants, déterminez s’ils sont linéairement indépendants. Sinon, expliquez pourquoi.
(a)
(b)
(c)
(d)
(e)
(f)
Pour les ensembles de vecteurs de base suivants, déterminez s’ils sont orthogonaux. Sinon, expliquez pourquoi.
(a)
(b)
(c)
(d)
(e)
Ces vecteurs de base sont-ils orthonormés ? Sinon, expliquez pourquoi.
(a)
(b)
(c)
(d)
(e)
(f)
(g)
Supposons que le robot se trouve à la position , et que ses vecteurs droite, haut et avant exprimés dans l’espace vertical sont , et , respectivement. (Notez que ces vecteurs forment une base orthonormée.) Les points suivants sont exprimés dans l’espace objet. Calculez les coordonnées de ces points dans l’espace vertical et dans l’espace monde.
(a)
(b)
(c)
(d)
(e)
Les coordonnées ci-dessous sont dans l’espace monde. Transformez ces coordonnées de l’espace monde vers l’espace vertical et vers l’espace objet.
(f)
(g)
(h)
(i)
(j)
Donnez cinq exemples de hiérarchies d’espaces de coordonnées imbriqués.
Beaucoup de petites choses ont été rendues grandes
par le bon type de publicité.
— Mark Twain (1835–1910),
Un Yankee du Connecticut à la cour du roi Arthur
Notre belle ville.
En y pensant bien, c’est exactement ce que Tom ou Ray Magliozzi diraient.
Veuillez nous pardonner d’avoir tourné le robot vers vous, ce qui nous a amenés à déroger à nos conventions habituelles où est « droite » dans l’espace objet. Pour notre défense, c’est un diagramme 2D, et nous ne sommes pas vraiment sûrs que les gens vivant dans un monde plat auraient le concept de « devant » et « derrière » (bien qu’ils pourraient probablement distinguer entre les états « normal » et « en miroir »—tout comme en 3D nous avons des systèmes de coordonnées main gauche et main droite). Alors qui peut dire si un robot 2D vous tourne vraiment le dos ou vous fait face, ou quelle direction elle considère comme sa gauche ou sa droite ?
Bien que ce soit un exemple extrême, il illustre un principe bien connu selon lequel, dans la plupart des projets créatifs, le temps total du projet n’est pas simplement la quantité de travail divisée par le nombre de travailleurs. Comme dit le proverbe, « Neuf femmes ne peuvent pas faire un bébé en un mois. »
D’accord, puisque tout cela se passe dans notre imagination, le mot littéralement pourrait être un peu déplacé.
Oui, y compris l’évier de la cuisine.
Nous imaginons que si ce chapitre était un épisode du Monde d’Elmo, cette question évidente et importante serait celle que le poisson rouge d’Elmo, Dorothy, aurait posée d’emblée.
Notez que c’est une optimisation courante d’ignorer cette possibilité et de supposer qu’ils sont perpendiculaires, même lorsqu’ils ne le sont pas. Cette hypothèse introduit quelques erreurs dans certains cas, mais elle permet une réduction du stockage et de la bande passante, et l’erreur n’est généralement pas perceptible en pratique. Nous en discuterons plus en détail dans Section 10.9.
Ici, le mot « beaucoup » signifie « presque tout le monde ».
Retour en haut