<< Matrices et transformations linéaires
Systèmes de coordonnées polaires >>
Chapter 6
Complément sur les matrices
L’esprit de l’homme étendu à une nouvelle idée
ne revient jamais à ses dimensions originales.
— Oliver Wendell Holmes Jr. (1841–1935)
Le chapitre 4 a présenté quelques-unes des propriétés et opérations les plus importantes des matrices et a discuté de la façon dont les matrices peuvent être utilisées pour exprimer des transformations géométriques en général. Le chapitre 5 a considéré les matrices et les transformations géométriques en détail. Ce chapitre complète notre couverture des matrices en abordant quelques opérations matricielles supplémentaires intéressantes et utiles.
La section 6.1 couvre le déterminant d’une matrice.
La section 6.2 couvre l’inverse d’une matrice.
La section 6.3 traite des matrices orthogonales.
La section 6.4 introduit les vecteurs homogènes et les matrices , et montre comment ils peuvent être utilisés pour effectuer des transformations affines en 3D.
La section 6.5 traite de la projection en perspective et montre comment la réaliser avec une matrice .
6.1Déterminant d’une matrice
Pour les matrices carrées, il existe un scalaire spécial appelé le déterminant de la matrice. Le déterminant a de nombreuses propriétés utiles en algèbre linéaire, et il a aussi des interprétations géométriques intéressantes.
Comme c’est notre habitude, nous discutons d’abord de quelques mathématiques, puis nous faisons des interprétations géométriques. La section 6.1.1 introduit la notation pour les déterminants et donne les règles d’algèbre linéaire pour calculer le déterminant d’une matrice ou . La section 6.1.2 traite des mineurs et des cofacteurs. Puis, la section 6.1.3 montre comment calculer le déterminant d’une matrice arbitraire, en utilisant les mineurs et les cofacteurs. Enfin, la section 6.1.4 interprète le déterminant d’un point de vue géométrique.
6.1.1 Déterminants des matrices et
Le déterminant d’une matrice carrée est noté ou, dans certains autres livres, « ». Le déterminant d’une matrice non carrée n’est pas défini. Cette section montre comment calculer les déterminants des matrices et . Le déterminant d’une matrice générale, qui est assez complexe, est discuté dans la section 6.1.3
Le déterminant d’une matrice est donné par
Déterminant d’une matrice
Notez que lorsque nous écrivons le déterminant d’une matrice, nous remplaçons les crochets par des barres verticales.
L’équation (6.1) peut être mémorisée plus facilement avec le diagramme suivant. Il suffit de multiplier les entrées le long de la diagonale et de la contre-diagonale, puis de soustraire le terme de la contre-diagonale du terme de la diagonale.
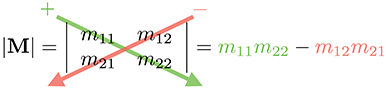
Quelques exemples aident à clarifier ce calcul simple :
Le déterminant d’une matrice est donné par
Déterminant d’une matrice
Un diagramme similaire peut être utilisé pour mémoriser l’équation (6.2). Nous écrivons deux copies de la matrice côte à côte et multiplions les entrées le long des diagonales et contre-diagonales, en additionnant les termes des diagonales et en soustrayant les termes des contre-diagonales.
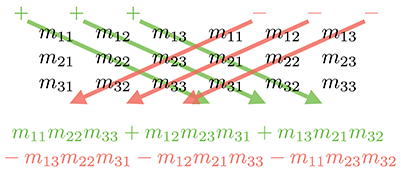
Par exemple,
Si nous interprétons les lignes d’une matrice comme trois vecteurs, alors le déterminant de la matrice est équivalent au « produit mixte » des trois vecteurs :
Déterminant vs. produit mixte de vecteurs 3D
6.1.2Mineurs et cofacteurs
Avant d’examiner les déterminants dans le cas général, nous devons introduire d’autres constructions : les mineurs et les cofacteurs.
Supposons que soit une matrice avec lignes et colonnes. Considérons la matrice obtenue en supprimant la ligne et la colonne de . Cette matrice aura évidemment lignes et colonnes. Le déterminant de cette sous-matrice, noté , est appelé un mineur de . Par exemple, le mineur est le déterminant de la matrice résultant de la suppression de la ligne 1 et de la colonne 2 de la matrice :
Un mineur d’une matrice
Le cofacteur d’une matrice carrée à une ligne et une colonne données est identique au mineur correspondant, mais avec les mineurs alternés négativés :
Cofacteur d’une matrice
Comme le montre l’équation (6.4), nous utilisons la notation pour désigner le cofacteur de à la ligne , colonne . Le terme a pour effet de négativer un cofacteur sur deux, selon un motif en damier :
Dans la section suivante, nous utilisons les mineurs et cofacteurs pour calculer les déterminants d’une dimension arbitraire, et à nouveau dans la section 6.2 pour calculer l’inverse d’une matrice.
6.1.3Déterminants de matrices arbitraires
Plusieurs définitions équivalentes existent pour le déterminant d’une matrice de dimension arbitraire. La définition que nous considérons ici exprime un déterminant en termes de ses cofacteurs. Cette définition est récursive, puisque les cofacteurs sont eux-mêmes des déterminants signés. D’abord, nous sélectionnons arbitrairement une ligne ou une colonne de la matrice. Ensuite, pour chaque élément de la ligne ou de la colonne, nous multiplions cet élément par le cofacteur correspondant. La somme de ces produits donne le déterminant de la matrice. Par exemple, en sélectionnant arbitrairement la ligne , le déterminant peut être calculé par
Calcul d’un déterminant par les cofacteurs de la ligne
Il s’avère que peu importe la ligne ou la colonne que nous choisissons ; elles produisent toutes le même résultat.
Voyons un exemple. Nous réécrirons l’équation pour le déterminant en utilisant l’équation (6.5) :
Définition récursive du déterminant appliquée au cas
Maintenant, dérivons le déterminant de la matrice :
Définition récursive du déterminant appliquée au cas
En développant les cofacteurs, nous obtenons
Déterminant d’une matrice sous forme développée
Comme vous pouvez l’imaginer, la complexité des formules explicites pour les déterminants de degré plus élevé croît rapidement. Heureusement, nous pouvons effectuer une opération connue sous le nom de « pivotage », qui n’affecte pas la valeur du déterminant, mais fait qu’une ligne ou colonne particulière est remplie de zéros sauf pour un seul élément (l’élément « pivot »). Il faut alors n’évaluer qu’un seul cofacteur. Puisque nous n’aurons de toute façon pas besoin de déterminants de matrices au-delà du cas , une discussion complète du pivotage dépasse la portée de ce livre.
Énonçons brièvement quelques caractéristiques importantes des déterminants.
Le déterminant d’une matrice identité de n’importe quelle dimension est 1 : Déterminant de la matrice identité
Le déterminant d’un produit matriciel est égal au produit des déterminants : Déterminant d’un produit matriciel
Cela s’étend à plus de deux matrices :
Le déterminant de la transposée d’une matrice est égal au déterminant original : Déterminant de la transposée d’une matrice
Si une ligne ou colonne d’une matrice contient uniquement des 0, alors le déterminant de cette matrice est 0 : Déterminant d’une matrice avec une ligne/colonne remplie de 0
L’échange de toute paire de lignes inverse le signe du déterminant : L’échange de lignes inverse le signe du déterminant
Cette même règle s’applique à l’échange d’une paire de colonnes.
L’ajout de tout multiple d’une ligne (colonne) à une autre ligne (colonne) ne modifie pas la valeur du déterminant ! L’ajout d’une ligne à
une autre ne change
pas le
déterminantCela explique pourquoi nos matrices de cisaillement de la section 5.5 ont un déterminant de 1.
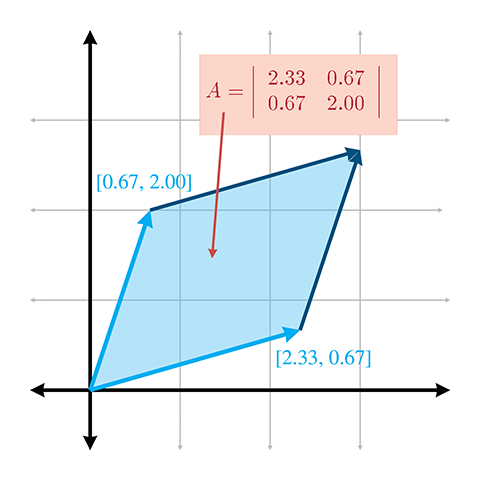
Figure 6.1 Le déterminant en 2D est l’aire signée de la boîte oblique formée par les vecteurs de base transformés.
6.1.4Interprétation géométrique du déterminant
Le déterminant d’une matrice a une interprétation géométrique intéressante. En 2D, le déterminant est égal à l’aire signée du parallélogramme ou boîte oblique ayant les vecteurs de base comme deux côtés (voir la figure 6.1). (Nous avons discuté de la façon dont nous pouvons utiliser les boîtes obliques pour visualiser les transformations d’espaces de coordonnées dans la section 4.2.) Par aire signée, nous voulons dire que l’aire est négative si la boîte oblique est « retournée » par rapport à son orientation originale.
En 3D, le déterminant est le volume du parallélépipède ayant les vecteurs de base transformés comme trois arêtes. Il sera négatif si l’objet est réfléchi (« retourné de l’intérieur ») à la suite de la transformation.
Le déterminant est lié au changement de taille résultant de la transformation par la matrice. La valeur absolue du déterminant est liée au changement d’aire (en 2D) ou de volume (en 3D) qui se produira à la suite de la transformation d’un objet par la matrice, et le signe du déterminant indique si une réflexion ou projection est contenue dans la matrice.
Le déterminant de la matrice peut également être utilisé pour aider à classer le type de transformation représenté par une matrice. Si le déterminant d’une matrice est zéro, la matrice contient une projection. Si le déterminant est négatif, une réflexion est contenue dans la matrice. Voir la section 5.7 pour plus de détails sur les différentes catégories de transformations.
6.2Inverse d’une matrice
Une autre opération importante qui ne s’applique qu’aux matrices carrées est la
inverse d’une matrice. Cette section traite de l’inverse matricielle d’un point de vue mathématique et géométrique.
L’inverse d’une matrice carrée , notée , est la matrice telle que lorsqu’on multiplie par d’un côté ou de l’autre, le résultat est la matrice identité. En d’autres termes,
Inverse d’une matrice
Toutes les matrices n’ont pas d’inverse. Un exemple évident est une matrice avec une ligne ou colonne remplie de 0 — peu importe par quoi on multiplie cette matrice, la ligne ou colonne correspondante du résultat sera également remplie de 0. Si une matrice a une inverse, on dit qu’elle est inversible ou non singulière. Une matrice qui n’a pas d’inverse est dite non inversible ou singulière. Pour toute matrice inversible , l’égalité vectorielle n’est vraie que lorsque . De plus, les lignes d’une matrice inversible sont linéairement indépendantes, tout comme les colonnes. Les lignes (et colonnes) d’une matrice singulière sont linéairement dépendantes.
Le déterminant d’une matrice singulière est zéro et le déterminant d’une matrice non singulière est non nul. Vérifier l’amplitude du déterminant est le test le plus couramment utilisé pour l’inversibilité car c’est le plus facile et le plus rapide. Dans des circonstances ordinaires, cela est correct, mais veuillez noter que la méthode peut échouer. Un exemple est une matrice de cisaillement extrême avec des vecteurs de base formant un parallélépipède très long et mince de volume unitaire. Cette matrice mal conditionnée est presque singulière, bien que son déterminant soit 1. Le nombre de condition est l’outil approprié pour détecter de tels cas, mais c’est un sujet avancé légèrement au-delà de la portée de ce livre.
Il existe plusieurs façons de calculer l’inverse d’une matrice. Celle que nous utilisons est basée sur l’adjoint classique, qui fait l’objet de la prochaine section.
6.2.1L’adjoint classique
Notre méthode pour calculer l’inverse d’une matrice est basée sur l’ adjoint classique. L’adjoint classique d’une matrice , noté « », est défini comme la transposée de la matrice des cofacteurs de .
Voyons un exemple. Prenons la matrice donnée précédemment :
D’abord, nous calculons les cofacteurs de , comme discuté dans la section 6.1.2 :
L’adjoint classique de est la transposée de la matrice des cofacteurs :
L’adjoint classique
6.2.2Inverse matricielle — Règles officielles d’algèbre linéaire
Pour calculer l’inverse d’une matrice, nous divisons l’adjoint classique par le déterminant :
Calcul de l’inverse matricielle à partir de l’adjoint classique et du déterminant
Si le déterminant est zéro, la division est indéfinie, ce qui s’accorde avec notre affirmation antérieure que les matrices avec un déterminant nul ne sont pas inversibles.
Voyons un exemple. Dans la section précédente, nous avons calculé l’adjoint classique d’une matrice ; calculons maintenant son inverse :
Ici, la valeur de vient de l’équation (6.6), et vient de l’équation (6.3).
Il existe d’autres techniques pour calculer l’inverse d’une matrice, comme l’élimination gaussienne. De nombreux manuels d’algèbre linéaire affirment que de telles techniques sont mieux adaptées à l’implémentation sur ordinateur car elles nécessitent moins d’opérations arithmétiques, et cette affirmation est vraie pour les matrices plus grandes et les matrices dont la structure peut être exploitée. Cependant, pour des matrices arbitraires de petit ordre, telles que les matrices , , et rencontrées le plus souvent dans les applications géométriques, la méthode de l’adjoint classique est généralement la méthode de choix. La raison est que la méthode de l’adjoint classique permet une implémentation sans branchement, c’est-à-dire sans instructions if ni boucles qui ne peuvent pas être déroulées statiquement. Sur les architectures superscalaires d’aujourd’hui et les processeurs vectoriels dédiés, c’est un grand avantage.
Nous terminons cette section par une liste rapide de plusieurs propriétés importantes concernant les inverses matricielles.
L’inverse de l’inverse d’une matrice est la matrice originale :
(Cela suppose bien sûr que est non singulière.)
La matrice identité est sa propre inverse :
Notez qu’il existe d’autres matrices qui sont leur propre inverse. Par exemple, considérons n’importe quelle matrice de réflexion, ou une matrice qui fait pivoter de autour de n’importe quel axe.
L’inverse de la transposée d’une matrice est la transposée de l’inverse de la matrice :
L’inverse d’un produit matriciel est égal au produit des inverses des matrices, prises en ordre inverse :
Cela s’étend à plus de deux matrices :
Le déterminant de l’inverse est l’inverse du déterminant de la matrice originale :
6.2.3Inverse matricielle — Interprétation géométrique
L’inverse d’une matrice est géométriquement utile car elle nous permet de calculer la transformation « inverse » ou « opposée » — une transformation qui « annule » une autre transformation si elles sont effectuées en séquence. Ainsi, si nous prenons un vecteur, le transformons par une matrice , puis le transformons par l’inverse , nous retrouvons le vecteur original. Nous pouvons facilement vérifier cela algébriquement :
6.3Matrices orthogonales
Nous avons fait précédemment référence à une catégorie particulière de matrices carrées connues sous le nom de matrices orthogonales. Cette section examine les matrices orthogonales de façon plus approfondie. Comme d’habitude, nous présentons d’abord quelques mathématiques pures (la section 6.3.1), puis nous donnons quelques interprétations géométriques (la section 6.3.2). Enfin, nous discutons de la façon d’ajuster une matrice arbitraire pour la rendre orthogonale (la section 6.3.3).
6.3.1Matrices orthogonales — Règles officielles d’algèbre linéaire
Une matrice carrée est orthogonale si et seulement si1 le produit de la matrice et de sa transposée est la matrice identité :
Définition de matrice orthogonale
Rappelons de la section 6.2.2 que, par définition, une matrice multipliée par son inverse est la matrice identité ( ). Ainsi, si une matrice est orthogonale, sa transposée et son inverse sont égales :
Définition équivalente de matrice orthogonale
C’est une information extrêmement puissante, car l’inverse d’une matrice est souvent nécessaire, et les matrices orthogonales apparaissent fréquemment en pratique dans les graphiques 3D. Par exemple, comme mentionné dans la section 5.7.5, les matrices de rotation et de réflexion sont orthogonales. Si nous savons que notre matrice est orthogonale, nous pouvons essentiellement éviter de calculer l’inverse, ce qui est un calcul relativement coûteux.
6.3.2Matrices orthogonales — Interprétation géométrique
Les matrices orthogonales nous intéressent principalement parce que leur inverse est trivial à calculer. Mais comment savoir si une matrice est orthogonale pour exploiter sa structure ?
Dans de nombreux cas, nous pouvons avoir des informations sur la façon dont la matrice a été construite et donc savoir a priori qu’elle ne contient que de la rotation et/ou de la réflexion. C’est une situation très courante, et il est très important d’en tirer parti lorsqu’on utilise des matrices pour décrire la rotation. Nous reviendrons sur ce sujet dans la section 8.2.1.
Mais que faire si nous ne savons rien à l’avance sur la matrice ? En d’autres termes, comment peut-on savoir si une matrice arbitraire est orthogonale ? Examinons le cas , qui est le plus intéressant pour nos besoins. Les conclusions que nous tirons dans cette section peuvent être étendues aux matrices de n’importe quelle dimension.
Soit une matrice orthogonale . En développant la définition de l’orthogonalité donnée par l’équation (6.7), nous obtenons
Cela nous donne neuf équations, qui doivent toutes être vraies pour que soit orthogonale :
Conditions satisfaites par une matrice orthogonale
Soient les vecteurs , , et les lignes de :
Nous pouvons maintenant réécrire les neuf équations plus compactement :
Conditions satisfaites par une matrice orthogonale
Ce changement de notation facilite l’interprétation.
Premièrement, le produit scalaire d’un vecteur avec lui-même est 1 si et seulement si le vecteur est un vecteur unitaire. Par conséquent, les équations avec un 1 à droite du signe égal (équations (6.8), (6.9), et (6.10)) seront vraies uniquement lorsque , , et sont des vecteurs unitaires.
Deuxièmement, rappelons depuis la section 2.11.2 que le produit scalaire de deux vecteurs est 0 si et seulement s’ils sont perpendiculaires. Par conséquent, les six autres équations (avec 0 à droite du signe égal) sont vraies lorsque , , et sont mutuellement perpendiculaires.
Donc, pour qu’une matrice soit orthogonale, les conditions suivantes doivent être remplies :
Chaque ligne de la matrice doit être un vecteur unitaire.
Les lignes de la matrice doivent être mutuellement perpendiculaires.
Des affirmations similaires peuvent être faites concernant les colonnes de la matrice, car si est orthogonale, alors doit également être orthogonale.
Notez que ces critères sont précisément ceux que nous avons dit dans la section 3.3.3 être satisfaits par un ensemble de vecteurs de base orthonormés. Dans cette section, nous avons également noté qu’une base orthonormée était particulièrement utile car nous pouvions effectuer, à l’aide du produit scalaire, la transformation de coordonnées « inverse » de celle toujours disponible. Lorsque nous disons que la transposée d’une matrice orthogonale est égale à son inverse, nous ne faisons que réexprimer ce fait dans le langage formel de l’algèbre linéaire.
Notez également que trois des équations d’orthogonalité sont des doublons, car le produit scalaire est commutatif. Ainsi, ces neuf équations n’expriment en réalité que six contraintes. Dans une matrice arbitraire, il y a neuf éléments et donc neuf degrés de liberté, mais dans une matrice orthogonale, six degrés de liberté sont supprimés par les contraintes, laissant trois degrés de liberté. Il est significatif que trois soit également le nombre de degrés de liberté inhérents à la rotation 3D. (Cependant, les matrices de rotation ne peuvent pas contenir de réflexion, donc il y a « légèrement plus de liberté » dans l’ensemble des matrices orthogonales que dans l’ensemble des orientations en 3D.)
Lors du calcul d’une inverse matricielle, nous ne tirerons généralement parti de l’orthogonalité que si nous savons a priori qu’une matrice est orthogonale. Si nous ne le savons pas à l’avance, il est probablement inutile de vérifier. Dans le meilleur des cas, nous vérifions l’orthogonalité et constatons que la matrice est bien orthogonale, puis nous la transposons. Mais cela peut prendre presque autant de temps que d’effectuer l’inversion. Dans le pire des cas, la matrice n’est pas orthogonale, et tout le temps passé à vérifier a été définitivement perdu. Enfin, même les matrices qui sont orthogonales dans l’abstrait peuvent ne pas être exactement orthogonales lorsqu’elles sont représentées en virgule flottante, et nous devons donc utiliser des tolérances, qui doivent être ajustées.
Une remarque importante s’impose ici sur une terminologie qui peut être légèrement déroutante. En algèbre linéaire, nous décrivons un ensemble de vecteurs de base comme orthogonal s’ils sont mutuellement perpendiculaires. Il n’est pas requis qu’ils aient une longueur unité. S’ils ont une longueur unité, ils forment une base orthonormée. Ainsi, les lignes et colonnes d’une matrice orthogonale sont des vecteurs de base orthonormés. Cependant, la construction d’une matrice à partir d’un ensemble de vecteurs de base orthogonaux ne donne pas nécessairement une matrice orthogonale (à moins que les vecteurs de base soient également orthonormés).
6.3.3Orthogonalisation d’une matrice
Il arrive parfois que nous rencontrions une matrice légèrement hors d’orthogonalité. Nous pouvons avoir acquis de mauvaises données d’une source externe, ou avoir accumulé des erreurs en virgule flottante (ce qu’on appelle dérive matricielle). Pour les vecteurs de base utilisés pour le bump mapping (voir la section 10.9), nous ajusterons souvent la base pour qu’elle soit orthogonale, même si les gradients du mapping de texture ne sont pas tout à fait perpendiculaires. Dans ces situations, nous aimerions orthogonaliser la matrice, ce qui donne une matrice avec des axes de vecteurs unitaires mutuellement perpendiculaires et (espérons-le) aussi proche que possible de la matrice originale.
L’algorithme standard pour construire un ensemble de vecteurs de base orthogonaux (ce que sont les lignes d’une matrice orthogonale) est l’orthogonalisation de Gram-Schmidt. L’idée de base est de parcourir les vecteurs de base dans l’ordre. Pour chaque vecteur de base, nous soustrayons la partie de ce vecteur qui est parallèle aux vecteurs de base précédents, ce qui doit donner un vecteur perpendiculaire.
Examinons le cas comme exemple. Comme précédemment, soient , , et les lignes d’une matrice . (Rappelons que vous pouvez également les considérer comme les axes -, -, et - d’un espace de coordonnées.) Alors un ensemble orthogonal de vecteurs lignes, , , et , , et , peuvent être calculés selon l’algorithme suivant :
Orthogonalisation de Gram-Schmidt des vecteurs de base 3D
Après application de ces étapes, les vecteurs , , et sont garantis d’être mutuellement perpendiculaires, et formeront donc une base orthogonale. Cependant, ils ne sont pas nécessairement des vecteurs unitaires. Nous avons besoin d’une base orthonormée pour former une matrice orthogonale, et nous devons donc normaliser les vecteurs. (Là encore, la terminologie peut prêter à confusion ; voir la note à la fin de la section précédente.) Notez que si nous normalisons les vecteurs au fur et à mesure plutôt qu’en une seconde passe, nous pouvons éviter toutes les divisions. De plus, une astuce qui fonctionne en 3D (mais pas dans des dimensions supérieures) consiste à calculer le troisième vecteur de base à l’aide du produit vectoriel :
L’algorithme de Gram-Schmidt est biaisé selon l’ordre dans lequel les vecteurs de base sont listés. Par exemple, ne change jamais, et est susceptible de changer le plus. Une variante de l’algorithme qui n’est biaisée vers aucun axe particulier consiste à abandonner la tentative d’orthogonaliser entièrement la matrice en une seule passe. Nous sélectionnons une fraction , et au lieu de soustraire toute la projection, nous n’en soustrayons que . Nous soustrayons également la projection sur l’axe original et non sur l’axe ajusté. De cette façon, l’ordre dans lequel nous effectuons les opérations n’a pas d’importance et nous n’avons pas de biais dimensionnel. Cet algorithme est résumé par
Algorithme d’orthogonalisation incrémentale non biaisée
Une itération de cet algorithme produit un ensemble de vecteurs de base légèrement « plus orthogonaux » que les vecteurs originaux, mais peut-être pas complètement orthogonaux. En répétant cette procédure plusieurs fois, nous pouvons éventuellement converger vers une base orthogonale. Choisir une valeur suffisamment petite pour (par exemple ) et itérer un nombre de fois suffisant (par exemple dix) nous permet de nous en approcher assez. Ensuite, nous pouvons utiliser l’algorithme de Gram-Schmidt standard pour garantir une base parfaitement orthogonale.
6.4 Matrices homogènes
Jusqu’à présent, nous n’avons utilisé que des vecteurs 2D et 3D. Dans cette section, nous introduisons les vecteurs 4D et la soi-disant coordonnée « homogène ». Il n’y a rien de magique dans les vecteurs et matrices 4D (et non, la quatrième coordonnée dans ce cas n’est pas le « temps »). Comme nous allons le voir, les vecteurs 4D et les matrices ne sont rien de plus qu’une commodité de notation pour des opérations 3D simples.
Cette section présente l’espace homogène 4D et les matrices de transformation ainsi que leur application à la géométrie 3D affine. La section 6.4.1 aborde la nature de l’espace homogène 4D et sa relation avec l’espace 3D physique. La section 6.4.2 explique comment les matrices de transformation peuvent être utilisées pour exprimer des translations. La section 6.4.3 explique comment les matrices de transformation peuvent être utilisées pour exprimer des transformations affines.
6.4.1Espace homogène 4D
Comme mentionné dans la section 2.1, les vecteurs 4D ont quatre composantes, les trois premières étant les composantes standard , , et . La quatrième composante d’un vecteur 4D est , parfois appelée la coordonnée homogène.
Pour comprendre comment l’espace 3D physique standard est étendu en 4D, examinons d’abord les coordonnées homogènes en 2D, qui sont de la forme . Imaginons le plan 2D standard comme existant en 3D dans le plan , de sorte que le point 2D physique est représenté dans l’espace homogène par . Pour tous les points qui ne se trouvent pas dans le plan , nous pouvons calculer le point 2D correspondant en projetant le point sur le plan , en divisant par . Ainsi, la coordonnée homogène est mappée au point 2D physique . Cela est illustré dans la figure 6.2.
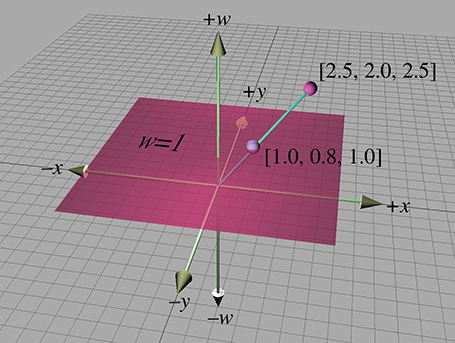
Figure 6.2 Projection des coordonnées homogènes sur le plan en 2D
Pour tout point 2D physique donné, il existe une infinité de points correspondants dans l’espace homogène, tous de la forme , à condition que . Ces points forment une droite passant par l’origine (homogène).
Lorsque , la division est indéfinie et il n’existe pas de point physique correspondant dans l’espace 2D. Cependant, nous pouvons interpréter un point homogène 2D de la forme comme un « point à l’infini », qui définit une direction plutôt qu’une position. Lorsque nous faisons la distinction conceptuelle entre « points » et « vecteurs » (voir la section 2.4), les « positions » où sont des « points » et les « directions » avec sont des « vecteurs ». Nous reviendrons là-dessus dans la section suivante.
La même idée de base s’applique lorsqu’on étend l’espace 3D physique en espace homogène 4D (bien que ce soit beaucoup plus difficile à visualiser). Les points 3D physiques peuvent être considérés comme vivant dans l’hyperplan 4D en . Un point 4D est de la forme , et nous projetons un point 4D sur cet hyperplan pour obtenir le point 3D physique correspondant . Lorsque , le point 4D représente un « point à l’infini », qui définit une direction plutôt qu’une position.
Les coordonnées homogènes et la projection par division par sont intéressantes, mais pourquoi diable voudrait-on utiliser l’espace 4D ? Il y a deux raisons principales d’utiliser des vecteurs 4D et des matrices . La première raison, que nous abordons dans la section suivante, n’est en réalité rien de plus qu’une commodité de notation. La deuxième raison est que si nous mettons la valeur appropriée dans , la division homogène aura pour résultat une projection en perspective, comme nous l’abordons dans la section 6.5.
6.4.2 Matrices de translation
Rappelons d’après la section 4.2 qu’une matrice de transformation représente une transformation linéaire, qui ne contient pas de translation. En raison de la nature de la multiplication matricielle, le vecteur nul est toujours transformé en vecteur nul, et donc toute transformation pouvant être représentée par une multiplication matricielle ne peut pas contenir de translation. C’est regrettable, car la multiplication et l’inversion matricielles sont des outils très pratiques pour composer des transformations complexes à partir de transformations simples et pour manipuler des relations d’espaces de coordonnées imbriquées. Il serait pratique de trouver un moyen d’étendre la matrice de transformation standard afin de pouvoir gérer les transformations avec translation ; les matrices fournissent un « bricolage » mathématique qui nous permet de faire cela.
Supposons pour l’instant que soit toujours 1. Ainsi, le vecteur 3D standard sera toujours représenté en 4D par . Toute matrice de transformation peut être représentée en 4D en utilisant la conversion
Extension d’une matrice de transformation en 4D
Lorsque nous multiplions un vecteur 4D de la forme par une matrice de cette forme, nous obtenons le même résultat que dans le cas standard , la seule différence étant la coordonnée supplémentaire :
Voici maintenant la partie intéressante. En 4D, nous pouvons également exprimer une translation comme une multiplication matricielle, ce que nous ne pouvions pas faire en 3D :
Utilisation d’une matrice pour effectuer une translation en 3D
Il est important de comprendre que cette multiplication matricielle est toujours une transformation linéaire. La multiplication matricielle ne peut pas représenter une « translation » en 4D, et le vecteur nul 4D sera toujours transformé en vecteur nul 4D. La raison pour laquelle cette astuce fonctionne pour transformer des points en 3D est que nous effectuons en réalité un cisaillement de l’espace 4D. (Comparez l’équation (6.11) avec les matrices de cisaillement de la section 5.5.) L’hyperplan 4D qui correspond à l’espace 3D physique ne passe pas par l’origine en 4D. Ainsi, lorsque nous cisaillons l’espace 4D, nous sommes capables de translater en 3D.
Examinons ce qui se passe lorsque nous effectuons une transformation sans translation suivie d’une transformation avec translation uniquement. Soit une matrice de rotation. (En fait, pourrait contenir d’autres transformations linéaires 3D, mais pour l’instant, supposons que ne contient que de la rotation.) Soit une matrice de translation de la forme de l’équation (6.11) :
Ensuite, nous pourrions faire pivoter puis translater un point pour calculer un nouveau point par
Rappelons que l’ordre des transformations est important, et puisque nous avons choisi d’utiliser des vecteurs ligne, l’ordre des transformations coïncide avec l’ordre dans lequel les matrices sont multipliées, de gauche à droite. Nous effectuons d’abord la rotation puis la translation.
Tout comme avec les matrices , nous pouvons concaténer les deux matrices en une seule matrice de transformation, que nous assignons à la matrice :
Examinons maintenant le contenu de :
Remarquez que la partie supérieure de contient la partie rotation, et la ligne inférieure contient la partie translation. La colonne la plus à droite (pour l’instant) sera .
En appliquant ces informations en sens inverse, nous pouvons prendre n’importe quelle matrice et la séparer en une partie transformation linéaire et une partie translation. Nous pouvons l’exprimer de façon concise avec la notation matricielle par blocs, en assignant le vecteur de translation au vecteur :
Pour l’instant, nous supposons que la colonne la plus à droite d’une matrice de transformation est toujours . Nous commencerons à rencontrer des situations où ce n’est pas le cas dans la section 6.5.
Voyons ce qui se passe avec les soi-disant « points à l’infini » (les vecteurs avec ). En multipliant par une matrice de transformation linéaire « standard » étendue en 4D (une transformation ne contenant pas de translation), nous obtenons
Multiplication d’un « point à l’infini » par une matrice sans translation
Autrement dit, lorsque nous transformons un vecteur point-à-l’infini de la forme par une matrice de transformation contenant de la rotation, de la mise à l’échelle, etc., la transformation attendue se produit, et le résultat est un autre vecteur point-à-l’infini de la forme .
Lorsque nous transformons un vecteur point-à-l’infini par une transformation qui contient de la translation, nous obtenons le résultat suivant :
Multiplication d’un « point à l’infini » par une matrice avec translation
Remarquez que le résultat est le même — c’est-à-dire qu’aucune translation ne se produit.
En d’autres termes, la composante d’un vecteur 4D peut être utilisée pour « désactiver » sélectivement la partie translation d’une matrice . Cela est utile car certains vecteurs représentent des « positions » et doivent être translatés, et d’autres vecteurs représentent des « directions », comme les normales de surface, et ne doivent pas être translatés. Dans un sens géométrique, nous pouvons considérer le premier type de données, avec , comme des « points », et le second type de données, les « points à l’infini » avec , comme des « vecteurs ».
Ainsi, l’une des raisons pour lesquelles les matrices sont utiles est qu’une matrice de transformation peut contenir de la translation. Lorsque nous utilisons des matrices uniquement à cette fin, la colonne la plus à droite de la matrice sera toujours . Puisque c’est le cas, pourquoi ne pas simplement supprimer cette colonne et utiliser une matrice ? Selon les règles de l’algèbre linéaire, les matrices sont indésirables pour plusieurs raisons :
Nous ne pouvons pas multiplier une matrice par une autre matrice .
Nous ne pouvons pas inverser une matrice , car la matrice n’est pas carrée.
Lorsque nous multiplions un vecteur 4D par une matrice , le résultat est un vecteur 3D.
La stricte adhésion aux règles de l’algèbre linéaire nous oblige à ajouter la quatrième colonne. Bien entendu, dans notre code, nous ne sommes pas liés par les règles de l’algèbre linéaire. Il est courant d’écrire une classe de matrice utile pour représenter des transformations contenant de la translation. En gros, une telle matrice est une matrice dont la colonne la plus à droite est supposée être et n’est donc pas explicitement stockée.
6.4.3Transformations affines générales
Le chapitre 5 a présenté des matrices pour de nombreuses transformations primitives. Comme une matrice ne peut représenter que des transformations linéaires en 3D, la translation n’était pas considérée. Armés de matrices de transformation , nous pouvons maintenant créer des transformations affines plus générales contenant de la translation, telles que :
une rotation autour d’un axe ne passant pas par l’origine,
une mise à l’échelle par rapport à un plan ne passant pas par l’origine,
une réflexion par rapport à un plan ne passant pas par l’origine, et
une projection orthographique sur un plan ne passant pas par l’origine.
L’idée de base est de translater le « centre » de la transformation vers l’origine, d’effectuer la transformation linéaire en utilisant les techniques développées dans le chapitre 5, puis de retransformer le centre vers sa position d’origine. Nous commençons avec une matrice de translation qui translate le point vers l’origine, et une matrice de transformation linéaire du chapitre 5 qui effectue la transformation linéaire. La matrice de transformation affine finale sera égale au produit matriciel , où est la matrice de translation avec le montant de translation opposé à celui de .
Il est intéressant d’observer la forme générale d’une telle matrice. Écrivons d’abord , , et sous la forme partitionnée utilisée précédemment :
En évaluant la multiplication matricielle, nous obtenons
Ainsi, la translation supplémentaire dans une transformation affine ne modifie que la dernière ligne de la matrice . La partie supérieure, qui contient la transformation linéaire, n’est pas affectée.
Notre utilisation des coordonnées « homogènes » jusqu’ici n’a vraiment été qu’un bricolage mathématique pour nous permettre d’inclure de la translation dans nos transformations. Nous mettons des guillemets autour d’« homogènes » parce que la valeur était toujours 1 (ou 0, dans le cas des points à l’infini). Dans la section suivante, nous supprimerons les guillemets et discuterons de façons significatives d’utiliser les coordonnées 4D avec d’autres valeurs de .
6.5 Matrices et projection en perspective
La section 6.4.1 a montré que lorsque nous interprétons un vecteur homogène 4D en 3D, nous divisons par . Cette division est un outil mathématique dont nous n’avons pas vraiment profité dans la section précédente, puisque était toujours 1 ou 0. Cependant, si nous jouons bien nos cartes, nous pouvons utiliser la division par pour encapsuler de façon très concise l’opération géométrique importante qu’est la projection en perspective.

Figure 6.3La projection orthographique utilise des projecteurs parallèles.
Nous pouvons en apprendre beaucoup sur la projection en perspective en la comparant à un autre type de projection déjà abordé, la projection orthographique. La section 5.3 a montré comment projeter l’espace 3D sur un plan 2D, appelé plan de projection, en utilisant la projection orthographique. La projection orthographique est également connue sous le nom de projection parallèle, car les projecteurs sont parallèles. (Un projecteur est une droite reliant le point d’origine au point projeté sur le plan.) Les projecteurs parallèles utilisés dans la projection orthographique sont représentés dans la figure 6.3.
La projection en perspective en 3D se projette également sur un plan 2D. Cependant, les projecteurs ne sont pas parallèles. En fait, ils se croisent en un point, connu sous le nom de centre de projection. Cela est illustré dans la figure 6.4.
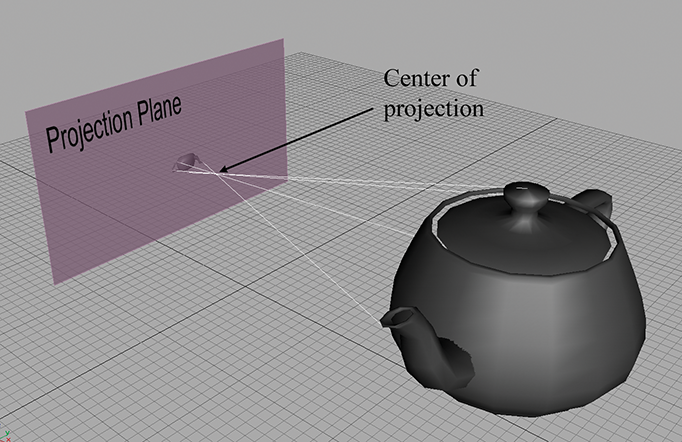
Figure 6.4 Avec la projection en perspective, les projecteurs se croisent au centre de projection.
Comme le centre de projection se trouve devant le plan de projection, les projecteurs se croisent avant de toucher le plan, ce qui entraîne une inversion de l’image. Lorsqu’on éloigne un objet du centre de projection, sa projection orthographique reste constante, mais la projection en perspective devient plus petite, comme illustré dans la figure 6.5. La théière de droite est plus éloignée du plan de projection, et sa projection est (légèrement) plus petite que celle de la théière plus proche. C’est un signal visuel très important connu sous le nom de raccourcissement perspectif.

Figure 6.5 En raison du raccourcissement perspectif, la projection de la théière de gauche est plus grande que la projection de la théière de droite. La théière de gauche est plus proche du plan de projection.
6.5.1Un sténopé
La projection en perspective est importante en infographie car elle modélise le fonctionnement du système visuel humain. En réalité, le système visuel humain est plus complexe car nous avons deux yeux, et pour chaque œil, la surface de projection (notre rétine) n’est pas plane ; examinons donc l’exemple plus simple d’un sténopé. Un sténopé est une boîte avec un minuscule trou sur l’un de ses côtés. Les rayons de lumière entrent dans le trou (convergeant ainsi en un point), puis frappent l’extrémité opposée de la boîte, qui est le plan de projection. Cela est illustré dans la figure 6.6.

Figure 6.6Un sténopé.
Dans cette vue, les côtés gauche et arrière de la boîte ont été supprimés pour que vous puissiez voir l’intérieur. Remarquez que l’image projetée sur le fond de la boîte est inversée. Cela est dû au fait que les rayons de lumière (les projecteurs) se croisent lorsqu’ils se rejoignent au niveau du trou (le centre de projection).
Examinons la géométrie derrière la projection en perspective d’un sténopé. Considérons un espace de coordonnées 3D avec l’origine au niveau du trou, l’axe perpendiculaire au plan de projection, et les axes et parallèles au plan de projection, comme indiqué dans la figure 6.7.

Figure 6.7 Un plan de projection parallèle au plan
Voyons si nous pouvons calculer, pour un point arbitraire , les coordonnées 3D de , qui est projeté à travers le trou sur le plan de projection. Premièrement, nous devons connaître la distance du trou au plan de projection. Nous assignons cette distance à la variable . Ainsi, le plan est défini par l’équation . Regardons maintenant les choses de côté et résolvons pour (voir la figure 6.8).
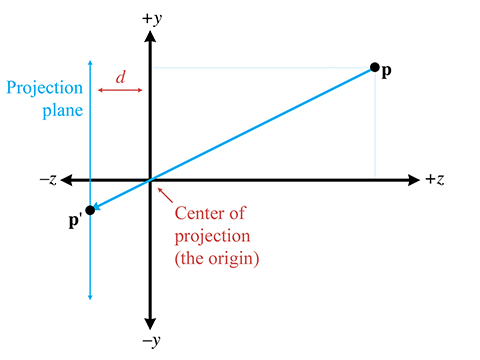
Figure 6.8 Vue de côté du plan de projection
Par triangles semblables, nous pouvons voir que
Remarquez que puisqu’un sténopé retourne l’image à l’envers, les signes de et sont opposés. La valeur de est calculée de la même manière :
Les valeurs de de tous les points projetés sont les mêmes : . Ainsi, le résultat de la projection d’un point à travers l’origine sur un plan en est
Projection sur le plan
En pratique, les signes moins supplémentaires créent des complications inutiles, et nous déplaçons donc le plan de projection en , qui se trouve devant le centre de projection, comme indiqué dans la figure 6.9. Bien entendu, cela ne fonctionnerait jamais pour un vrai sténopé, puisque le but du trou est précisément de n’admettre que la lumière passant par un seul point. Cependant, dans l’univers mathématique d’un ordinateur, cela fonctionne très bien.
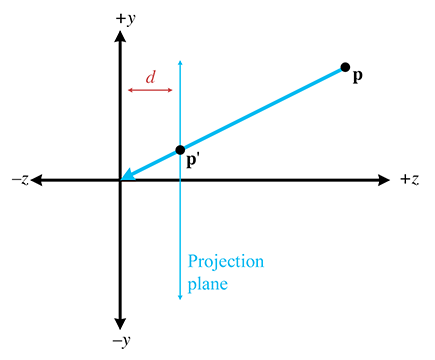
Figure 6.9 Plan de projection devant le centre de projection
Comme prévu, déplacer le plan de projection devant le centre de projection supprime les signes moins gênants :
Projection d’un point sur le plan
6.5.2Matrices de projection en perspective
Comme la conversion de l’espace 4D en espace 3D implique une division, nous pouvons encoder une projection en perspective dans une matrice . L’idée de base est de trouver une équation pour avec un dénominateur commun pour , , et , puis de configurer une matrice qui fixe égal à ce dénominateur. Nous supposons que les points originaux ont .
Premièrement, nous manipulons l’équation (6.12) pour avoir un dénominateur commun :
Pour diviser par ce dénominateur, nous plaçons le dénominateur dans , de sorte que le point 4D sera de la forme
Nous avons donc besoin d’une matrice qui multiplie un vecteur homogène pour produire . La matrice qui réalise cela est
Projection sur le plan à l’aide d’une matrice
Nous avons ainsi dérivé une matrice de projection .
Plusieurs points importants méritent d’être soulignés ici :
La multiplication par cette matrice n’effectue pas réellement la transformation perspective ; elle ne fait que calculer le dénominateur approprié dans . Rappelons que la division perspective se produit réellement lorsqu’on convertit de 4D en 3D en divisant par .
Il existe de nombreuses variantes. Par exemple, on peut placer le plan de projection en , et le centre de projection en . Il en résulte une équation légèrement différente.
Tout cela semble excessivement compliqué. Il semblerait plus simple de diviser directement par plutôt que de s’embarrasser de matrices. Alors pourquoi l’espace homogène est-il intéressant ? Premièrement, les matrices offrent un moyen d’exprimer la projection comme une transformation pouvant être concaténée avec d’autres transformations. Deuxièmement, la projection sur des plans non alignés axialement est possible. En gros, nous n’avons pas besoin des coordonnées homogènes, mais les matrices fournissent un moyen compact de représenter et de manipuler des transformations de projection.
La matrice de projection dans un pipeline de géométrie graphique réel (connue plus précisément sous le nom de « matrice de découpage ») fait plus que simplement copier dans . Elle diffère de celle que nous avons dérivée sur deux points importants :
La plupart des systèmes graphiques appliquent un facteur d’échelle normalisateur tel que au plan de découpage lointain. Cela garantit que les valeurs utilisées pour le tampon de profondeur sont réparties de manière appropriée pour la scène à rendre, afin de maximiser la précision du tampon de profondeur.
La matrice de projection dans la plupart des systèmes graphiques met également à l’échelle les valeurs et en fonction du champ de vision de la caméra.
Nous entrerons dans ces détails dans la section 10.3.2, où nous montrerons à quoi ressemble une matrice de projection en pratique, en utilisant DirectX et OpenGL comme exemples.
Exercices
Calculez le déterminant de la matrice suivante :
Calculez le déterminant, l’adjoint classique et l’inverse de la matrice suivante :
La matrice suivante est-elle orthogonale ?
Inversez la matrice de l’exercice précédent.
Inversez la matrice
Construisez une matrice pour translater de .
Construisez une matrice pour effectuer une rotation de 20° autour de l’axe , puis une translation de .
Construisez une matrice pour translater de , puis effectuer une rotation de 20° autour de l’axe .
Construisez une matrice pour effectuer une projection en perspective sur le plan . (Supposez que l’origine est le centre de projection.)
Utilisez la matrice de l’exercice précédent pour calculer les coordonnées 3D de la projection du point sur le plan .
Une tentative de visualisation de la quatrième dimension :
Prenez un point, étirez-le en une droite, enroulez-la en un cercle,
tordez-le en une sphère, et percez la sphère.
— Albert Einstein (1879–1955)
La notation « » doit se lire « si et seulement si » et indique que l’énoncé est vrai si et seulement si est également vrai. « Si et seulement si » est en quelque sorte un signe égal pour les valeurs booléennes. En d’autres termes, si ou est vrai, alors les deux doivent être vrais, et si ou est faux, alors les deux doivent être faux. La notation est également similaire à la notation « = » standard en ce sens qu’elle est réflexive. C’est une façon élaborée de dire que peu importe lequel est à gauche et lequel est à droite ; implique .
<< Matrices et transformations linéaires
Retour en haut