Mécanique 1 : cinématique linéaire et calcul >>
Chapitre 10
Sujets mathématiques
issus de la 3D graphique
Je ne pense pas qu’il y ait quoi que ce soit de mal à de belles images.
— Shigeru Miyamoto (1952–)
Ce chapitre traite d’un certain nombre de questions mathématiques qui surviennent lors de la création de graphismes 3D sur ordinateur. Bien sûr, nous ne pouvons pas espérer couvrir le vaste sujet de l’infographie en détail dans un seul chapitre. Des livres entiers sont écrits qui ne font que survoler le sujet. Ce chapitre est à l’infographie ce que ce livre entier est aux applications 3D interactives : il présente un aperçu extrêmement bref et de haut niveau du sujet, en se concentrant sur les sujets pour lesquels les mathématiques jouent un rôle essentiel. Comme dans le reste de ce livre, nous essayons d’accorder une attention particulière aux sujets qui, de notre expérience, sont traités superficiellement dans d’autres sources ou sont une source de confusion pour les débutants.
Pour être un peu plus direct : ce chapitre seul ne suffit pas pour vous apprendre à afficher de belles images à l’écran. Cependant, il devrait être utilisé en parallèle (ou avant !) un autre cours, livre ou auto-apprentissage sur l’infographie, et nous espérons qu’il vous aidera à surmonter facilement quelques obstacles traditionnels. Bien que nous présentions quelques extraits d’exemples en High Level Shading Language (HLSL) à la fin de ce chapitre, vous ne trouverez pas grand-chose d’autre pour vous aider à déterminer quels appels de fonctions DirectX ou OpenGL effectuer pour obtenir un effet désiré. Ces questions sont certainement d’une importance pratique capitale, mais hélas, elles appartiennent aussi à la catégorie des connaissances que Robert Maynard Hutchins qualifiait de « faits à vieillissement rapide », et nous avons essayé d’éviter d’écrire un livre qui nécessite une mise à jour tous les deux ans quand ATI sort une nouvelle carte ou Microsoft une nouvelle version de DirectX. Heureusement, les références et exemples d’API à jour abondent sur Internet, qui est un endroit beaucoup plus approprié pour ce genre de choses. (API signifie interface de programmation d’application. Dans ce chapitre, API désignera le logiciel que nous utilisons pour communiquer avec le sous-système de rendu.)
Une dernière mise en garde : comme il s’agit d’un livre sur les maths pour les jeux vidéo, nous aurons un biais vers le temps réel. Cela ne veut pas dire que le livre ne peut pas être utilisé si vous vous intéressez à l’écriture d’un lanceur de rayons ; seulement que notre expertise et notre focus se situe dans le rendu en temps réel.
Ce chapitre progresse grosso modo de la théorie en tour d’ivoire aux extraits de code concrets.
La Section 10.1 donne une approche théorique très générale (et sophistiquée) de l’infographie, aboutissant à l’équation de rendu.
Nous baissons ensuite notre niveau d’abstraction pour nous concentrer sur des questions d’application pratique plus directe, tout en maintenant notre indépendance vis-à-vis des plates-formes et en essayant de rester pertinents dans dix ans.
La Section 10.2 traite de quelques mathématiques de base liées à la visualisation en 3D.
La Section 10.3 introduit quelques espaces de coordonnées et transformations importants.
La Section 10.4 examine comment représenter les surfaces de la géométrie de notre scène à l’aide d’un maillage polygonal.
La Section 10.5 montre comment contrôler les propriétés des matériaux (comme la « couleur » de l’objet) à l’aide de cartes de texture.
Les sections suivantes portent sur l’éclairage.
La Section 10.6 définit l’omniprésent modèle d’éclairage de Blinn-Phong.
La Section 10.7 discute de quelques méthodes courantes pour représenter les sources lumineuses.
En s’éloignant un peu plus de la théorie intemporelle, les sections suivantes discutent de deux questions d’intérêt contemporain particulier.
La Section 10.8 porte sur l’animation squelettique.
La Section 10.9 explique le fonctionnement du bump mapping.
Le dernier tiers de ce chapitre est le plus susceptible de devenir obsolète dans les années à venir, car il est le plus immédiatement pratique.
La Section 10.10 donne un aperçu d’un pipeline graphique temps réel simple, puis descend ce pipeline en abordant certaines questions mathématiques en chemin.
La Section 10.11 conclut le chapitre en plein territoire des « faits à vieillissement rapide » avec plusieurs exemples HLSL illustrant certaines des techniques abordées précédemment.
10.1Fonctionnement de l’infographie
Nous commençons notre discussion de l’infographie en vous expliquant comment les choses fonctionnent vraiment, ou peut-être plus précisément, comment elles devraient vraiment fonctionner, si nous avions suffisamment de connaissances et de puissance de traitement pour faire les choses correctement. L’étudiant débutant est averti que beaucoup de matériel introductif (surtout les tutoriels sur Internet) et la documentation d’API souffrent d’un grand manque de perspective. Vous pourriez avoir l’impression en lisant ces sources que les diffuse maps, l’ombrage de Blinn-Phong et l’occlusion ambiante sont « La façon dont les images du monde réel fonctionnent », alors qu’en réalité vous lisez probablement une description de la façon dont un modèle d’éclairage particulier a été implémenté dans un langage particulier sur un matériel particulier via une API particulière. En définitive, tout tutoriel entrant dans les détails doit choisir un modèle d’éclairage, un langage, une plate-forme, une représentation des couleurs, des objectifs de performance, etc. — comme nous devrons le faire plus loin dans ce chapitre. (Ce manque de perspective est généralement intentionnel et justifié.) Cependant, nous pensons qu’il est important de savoir quels sont les principes fondamentaux et intemporels, et quels sont les choix arbitraires basés sur des approximations et des compromis, guidés par des limitations technologiques qui peuvent n’être applicables qu’au rendu en temps réel, ou susceptibles de changer dans un avenir proche. Donc avant d’entrer trop dans les détails du type particulier de rendu le plus utile pour l’infographie temps réel introductive, nous voulons décrire comment le rendu fonctionne vraiment.
Nous nous empressons également d’ajouter que cette discussion suppose que l’objectif est le photoréalisme, simulant le fonctionnement des choses dans la nature. En fait, ce n’est souvent pas l’objectif, et ce n’est certainement jamais le seul objectif. Comprendre comment la nature fonctionne est un point de départ très important, mais des facteurs artistiques et pratiques dictent souvent une stratégie différente de la simple simulation de la nature.
10.1.1Les deux grandes approches du rendu
Nous commençons avec la fin en tête. L’objectif final du rendu est un bitmap, ou peut-être une séquence de bitmaps si nous produisons une animation. Vous savez presque certainement déjà qu’un bitmap est un tableau rectangulaire de couleurs, et chaque entrée de la grille est connue sous le nom de pixel, qui est l’abréviation de « picture element » (élément d’image). Au moment où nous produisons l’image, ce bitmap est également connu sous le nom de tampon de trame (frame buffer), et souvent il y a un post-traitement ou une conversion supplémentaire lorsque nous copions le tampon de trame vers la sortie bitmap finale.
Comment déterminons-nous la couleur de chaque pixel ? C’est la question fondamentale du rendu. Comme tant de défis en informatique, un excellent point de départ est d’examiner comment la nature fonctionne.
Nous voyons la lumière. L’image que nous percevons est le résultat de la lumière qui rebondit dans l’environnement et entre finalement dans l’œil. Ce processus est compliqué, pour le moins. Non seulement la physique1 de la lumière rebondissant est très compliquée, mais il en va de même pour la physiologie de l’équipement de détection dans nos yeux2 et les mécanismes d’interprétation dans nos esprits. Ainsi, en ignorant un grand nombre de détails et de variations (comme tout livre introductif doit le faire), la question de base à laquelle tout système de rendu doit répondre pour chaque pixel est « Quelle couleur de lumière s’approche de la caméra depuis la direction correspondant à ce pixel ? »
Il y a essentiellement deux cas à considérer. Soit nous regardons directement une source lumineuse et la lumière a voyagé directement de la source lumineuse à notre œil, soit (plus couramment) la lumière est partie d’une source lumineuse dans une autre direction, a rebondi une ou plusieurs fois, puis est entrée dans notre œil. Nous pouvons décomposer la question clé posée précédemment en deux tâches. Ce livre appelle ces deux tâches l’algorithme de rendu, bien que ces deux procédures hautement abstraites cachent évidemment une grande complexité concernant les algorithmes réels utilisés en pratique pour les implémenter.
L’algorithme de rendu
Détermination de la surface visible. Trouver la surface la plus proche de l’œil, dans la direction correspondant au pixel actuel.
Éclairage. Déterminer quelle lumière est émise et/ou réfléchie par cette surface dans la direction de l’œil.
À ce stade, il semble que nous ayons fait quelques simplifications importantes, et beaucoup d’entre vous lèvent sans doute leur main métaphorique pour demander « Qu’en est-il de la translucidité ? » « Qu’en est-il des réflexions ? » « Qu’en est-il de la réfraction ? » « Qu’en est-il des effets atmosphériques ? » Veuillez retenir toutes les questions jusqu’à la fin de la présentation.
La première étape de l’algorithme de rendu est connue sous le nom de détermination de la surface visible. Il existe deux solutions courantes à ce problème. La première est connue sous le nom de lancer de rayons (raytracing). Plutôt que de suivre les rayons lumineux dans la direction dans laquelle ils voyagent depuis les surfaces émissives, nous traçons les rayons à rebours, de sorte que nous ne traitons que les rayons lumineux qui comptent : ceux qui entrent dans notre œil depuis la direction donnée. Nous envoyons un rayon depuis l’œil dans la direction passant par le centre de chaque pixel3 pour voir le premier objet de la scène que ce rayon frappe. Ensuite, nous calculons la couleur émise ou réfléchie par cette surface dans la direction du rayon. Un résumé très simplifié de cet algorithme est illustré par le Listing 10.1.
for (each x,y screen pixel) {
// Sélectionner un rayon pour ce pixel
Ray ray = getRayForPixel(x,y);
// Intersecter le rayon avec la géométrie. Cela ne retournera
// pas seulement le point d'intersection, mais aussi une normale
// de surface et d'autres informations nécessaires pour ombrer
// le point, comme une référence d'objet, des informations de
// matériau, des coordonnées locales S,T, etc.
// Ne pas prendre ce pseudocode trop littéralement.
Vector3 pos, normal;
Object *obj; Material *mtl;
if (rayIntersectScene(ray, pos, normal, obj, mtl)) {
// Ombrer le point d'intersection. (Quelle lumière est
// émise/réfléchie depuis ce point vers la caméra ?)
Color c = shadePoint(ray, pos, normal, obj, mtl);
// Le mettre dans le tampon de trame
writeFrameBuffer(x,y, c);
} else {
// Le rayon a manqué toute la scène. Utiliser simplement une
// couleur de fond générique pour ce pixel
writeFrameBuffer(x,y, backgroundColor);
}
}L’autre stratégie principale pour la détermination de la surface visible, celle utilisée pour le rendu en temps réel au moment de la rédaction de ce texte, est connue sous le nom de tampon de profondeur (depth buffering). L’idée de base est qu’à chaque pixel nous stockons non seulement une valeur de couleur, mais aussi une valeur de profondeur. Cette valeur de tampon de profondeur enregistre la distance de l’œil à la surface qui réfléchit ou émet la lumière utilisée pour déterminer la couleur de ce pixel. Comme illustré dans le Listing 10.1, la « boucle externe » d’un lanceur de rayons est les pixels en espace écran, mais dans les graphismes temps réel, la « boucle externe » est les éléments géométriques qui constituent la surface de la scène.
Les différentes méthodes de description des surfaces ne sont pas importantes ici. Ce qui est important, c’est que nous pouvons projeter la surface sur l’espace écran et les mapper sur les pixels de l’espace écran via un processus connu sous le nom de rastérisation. Pour chaque pixel de la surface, connu sous le nom de fragment source, nous calculons la profondeur de la surface à ce pixel et la comparons à la valeur existante dans le tampon de profondeur, parfois connu sous le nom de fragment destination. Si le fragment source que nous sommes en train de rendre est plus loin de la caméra que la valeur existante dans le tampon, alors ce que nous avons rendu avant ceci cache la surface que nous rendons maintenant (du moins à ce pixel), et nous passons au pixel suivant. Cependant, si notre valeur de profondeur est plus proche que la valeur existante dans le tampon de profondeur, alors nous savons que c’est la surface la plus proche de l’œil (du moins parmi celles rendues jusqu’à présent) et donc nous mettons à jour le tampon de profondeur avec cette nouvelle valeur de profondeur plus proche. À ce stade, nous pourrions également passer à l’étape 2 de l’algorithme de rendu (du moins pour ce pixel) et mettre à jour le tampon de trame avec la couleur de la lumière émise ou réfléchie par la surface à ce point. C’est connu sous le nom de rendu avant (forward rendering), et l’idée de base est illustrée par le Listing 10.2.
// Effacer les tampons de trame et de profondeur
fillFrameBuffer(backgroundColor);
fillDepthBuffer(infinity);
// La boucle externe itère sur toutes les primitives (généralement des triangles)
for (each geometric primitive) {
// Rastériser la primitive
for (each pixel x,y in the projection of the primitive) {
// Tester le tampon de profondeur, pour voir si un pixel plus
// proche a déjà été écrit.
float primDepth = getDepthOfPrimitiveAtPixel(x,y);
if (primDepth > readDepthBuffer(x,y)) {
// Le pixel de cette primitive est caché, l'ignorer
continue;
}
// Déterminer la couleur de la primitive à ce pixel.
Color c = getColorOfPrimitiveAtPixel(x,y);
// Mettre à jour les tampons de couleur et de profondeur
writeFrameBuffer(x,y, c);
writeDepthBuffer(x,y, primDepth);
}
}À l’opposé du rendu avant se trouve le rendu différé (deferred rendering), une ancienne technique qui redevient populaire en raison de l’emplacement actuel des goulots d’étranglement dans les types d’images que nous produisons et le matériel que nous utilisons pour les produire. Un moteur de rendu différé utilise, en plus du tampon de trame et du tampon de profondeur, des tampons supplémentaires, collectivement connus sous le nom de G-buffer (abréviation de tampon de géométrie), qui contient des informations supplémentaires sur la surface la plus proche de l’œil à cet emplacement, comme la position 3D de la surface, la normale de surface, et les propriétés de matériau nécessaires pour les calculs d’éclairage, comme la « couleur » de l’objet et son niveau de « brillance » à cet emplacement particulier. (Plus tard, nous verrons comment ces termes intuitifs entre guillemets sont un peu trop vagues pour le rendu.) Par rapport à un moteur de rendu avant, un moteur de rendu différé suit notre algorithme de rendu en deux étapes un peu plus littéralement. D’abord, nous « rendons » la scène dans le G-buffer, effectuant essentiellement uniquement la détermination de la visibilité — récupérant les propriétés de matériau du point « vu » par chaque pixel mais n’effectuant pas encore les calculs d’éclairage. La seconde passe effectue réellement les calculs d’éclairage. Le Listing 10.3 explique le rendu différé en pseudocode.
// Effacer les tampons de géométrie et de profondeur
clearGeometryBuffer();
fillDepthBuffer(infinity);
// Rastériser toutes les primitives dans le G-buffer
for (each geometric primitive) {
for (each pixel x,y in the projection of the primitive) {
// Tester le tampon de profondeur, pour voir si un pixel plus
// proche a déjà été écrit.
float primDepth = getDepthOfPrimitiveAtPixel(x,y);
if (primDepth > readDepthBuffer(x,y)) {
// Le pixel de cette primitive est caché, l'ignorer
continue;
}
// Récupérer les informations nécessaires pour l'ombrage dans
// la passe suivante.
MaterialInfo mtlInfo;
Vector3 pos, normal;
getPrimitiveShadingInfo(mtlInfo, pos, normal);
// Les sauvegarder dans le G-buffer et le tampon de profondeur
writeGeometryBuffer(x,y, mtlInfo, pos, normal);
writeDepthBuffer(x,y, primDepth);
}
}
// Effectuer maintenant l'ombrage dans une 2e passe, en espace écran
for (each x,y screen pixel) {
if (readDepthBuffer(x,y) == infinity) {
// Pas de géométrie ici. Écrire simplement une couleur de fond
writeFrameBuffer(x,y, backgroundColor);
} else {
// Récupérer les informations d'ombrage depuis le tampon de géométrie
MaterialInfo mtlInfo;
Vector3 pos, normal;
readGeometryBuffer(x,y, mtlInfo, pos, normal);
// Ombrer le point
Color c = shadePoint(pos, normal, mtlInfo);
// Le mettre dans le tampon de trame
writeFrameBuffer(x,y, c);
}
}Pseudocode pour le rendu différé utilisant le tampon de profondeur
Avant de continuer, nous devons mentionner un point important sur les raisons pour lesquelles le rendu différé est populaire. Lorsque plusieurs sources lumineuses éclairent le même point de surface, les limitations matérielles ou les facteurs de performance peuvent nous empêcher de calculer la couleur finale d’un pixel en un seul calcul, comme le montrent les listes de pseudocode pour les rendus avant et différé. Au lieu de cela, nous devons utiliser plusieurs passes, une passe pour chaque lumière, et accumuler la lumière réfléchie de chaque source lumineuse dans le tampon de trame. Dans le rendu avant, ces passes supplémentaires impliquent de rendre à nouveau les primitives. Avec le rendu différé, cependant, les passes supplémentaires sont en espace image, et dépendent donc de la taille 2D de la lumière en espace écran, pas de la complexité de la scène ! C’est dans cette situation que le rendu différé commence vraiment à avoir de grands avantages de performance par rapport au rendu avant.
10.1.2Description des propriétés de surface : la BRDF
Parlons maintenant de la deuxième étape de l’algorithme de rendu : l’éclairage. Une fois que nous avons localisé la surface la plus proche de l’œil, nous devons déterminer la quantité de lumière émise directement par cette surface, ou émise depuis une autre source et réfléchie par la surface dans la direction de l’œil. La lumière transmise directement d’une surface à l’œil — par exemple, lorsqu’on regarde directement une ampoule ou le soleil — est le cas le plus simple. Ces surfaces émissives sont une petite minorité dans la plupart des scènes ; la plupart des surfaces n’émettent pas leur propre lumière, mais réfléchissent plutôt la lumière émise depuis ailleurs. Nous concentrerons l’essentiel de notre attention sur les surfaces non-émissives.
Bien que nous parlions souvent informellement de la « couleur » d’un objet, nous savons que la couleur perçue d’un objet est en réalité la lumière qui entre dans notre œil, et peut donc dépendre de nombreux facteurs différents. Les questions importantes à poser sont : Quelles couleurs de lumière sont incidentes sur la surface, et depuis quelles directions ? Depuis quelle direction regardons-nous la surface ? Comment l’objet est-il « brillant » ?4 Donc une description d’une surface adaptée au rendu ne répond pas à la question « De quelle couleur est cette surface ? » Cette question est parfois dénuée de sens — de quelle couleur est un miroir, par exemple ? Au lieu de cela, la question pertinente est un peu plus compliquée, et elle ressemble à ceci : « Lorsque la lumière d’une couleur donnée frappe la surface depuis une direction incidente donnée, quelle fraction de cette lumière est réfléchie dans une autre direction particulière ? » La réponse à cette question est donnée par la fonction de distribution de réflectance bidirectionnelle, ou BRDF en abrégé. Donc plutôt que « De quelle couleur est l’objet ? » nous demandons « Quelle est la distribution de la lumière réfléchie ? »
Symboliquement, nous écrivons la BRDF comme la fonction .5 La valeur de cette fonction est un scalaire qui décrit la probabilité relative que la lumière incidente au point depuis la direction soit réfléchie dans la direction sortante plutôt que dans une autre direction sortante. Comme indiqué par le type en gras et le chapeau, peut être un vecteur unitaire, mais plus généralement, il peut s’agir de n’importe quelle façon de spécifier une direction ; les angles polaires sont un autre choix évident et sont couramment utilisés. Différentes couleurs de lumière sont généralement réfléchies différemment ; d’où la dépendance à , qui est la couleur (en réalité, la longueur d’onde) de la lumière.
Bien que nous nous intéressions particulièrement aux directions incidentes qui proviennent de surfaces émissives et aux directions sortantes qui pointent vers notre œil, en général, toute la distribution est pertinente. Premièrement, les lumières, les yeux et les surfaces peuvent se déplacer, donc dans le contexte de la création d’une description de surface (par exemple, « cuir rouge »), nous ne savons pas quelles directions seront importantes. Mais même dans une scène particulière avec toutes les surfaces, lumières et yeux fixes, la lumière peut rebondir plusieurs fois, nous devons donc mesurer les réflexions lumineuses pour des paires arbitraires de directions.
Avant de continuer, il est très instructif de voir comment les deux propriétés intuitives de matériau qui ont été décriées précédemment, la couleur et la brillance, peuvent être exprimées précisément dans le cadre d’une BRDF. Considérons une balle verte. Un objet vert est vert et non bleu car il réfléchit la lumière incidente verte plus fortement que la lumière incidente de toute autre couleur.6 Par exemple, peut-être que la lumière verte est presque entièrement réfléchie, avec seulement une petite fraction absorbée, tandis que 95% de la lumière bleue et rouge est absorbée et seulement 5% de la lumière à ces longueurs d’onde est réfléchie dans diverses directions. La lumière blanche consiste en réalité en toutes les différentes couleurs de lumière, donc un objet vert filtre essentiellement les couleurs autres que le vert. Si un autre objet répondait à la lumière verte et rouge de la même manière que notre balle verte, mais absorbait 50% de la lumière bleue et réfléchissait les autres 50%, nous pourrions percevoir l’objet comme bleu-vert (teal). Ou si la plupart de la lumière à toutes les longueurs d’onde était absorbée, sauf une petite quantité de lumière verte, nous la percevrions comme une teinte foncée de vert. En résumé, une BRDF rend compte de la différence de couleur entre deux objets à travers la dépendance à : toute longueur d’onde de lumière donnée a sa propre distribution de réflectance.
Ensuite, considérons la différence entre du plastique rouge brillant et du papier de construction rouge mat. Une surface brillante réfléchit la lumière incidente beaucoup plus fortement dans une direction particulière par rapport aux autres, alors qu’une surface diffuse disperse la lumière plus uniformément dans toutes les directions sortantes. Un réflecteur parfait, comme un miroir, réfléchirait toute la lumière d’une direction entrante dans une seule direction sortante, tandis qu’une surface parfaitement diffuse réfléchirait la lumière également dans toutes les directions sortantes, quelle que soit la direction d’incidence. En En résumé, une BRDF rend compte de la différence de « brillance » entre deux objets à travers sa dépendance à et .
Des phénomènes plus complexes peuvent être exprimés en généralisant la BRDF. La translucidité et la réfraction de la lumière peuvent être facilement incorporées en permettant aux vecteurs de direction de pointer vers l’intérieur de la surface. Nous pourrions appeler cette généralisation mathématique une fonction de distribution de dispersion de surface bidirectionnelle (BSSDF). Parfois, la lumière frappe un objet, rebondit à l’intérieur de celui-ci, puis en ressort à un point différent. Ce phénomène est connu sous le nom de diffusion sous-surface et est un aspect important de l’apparence de nombreuses substances communes, comme la peau et le lait. Cela nécessite de diviser le point de réflexion unique en et , ce qui est utilisé par la fonction de distribution de dispersion de surface bidirectionnelle (BSSDF). Même les effets volumétriques, comme le brouillard et la diffusion sous-surface, peuvent être exprimés, en supprimant le mot « surface » et en définissant une fonction de distribution de dispersion bidirectionnelle (BSDF) en tout point de l’espace, pas seulement sur les « surfaces ». Au premier abord, cela peut sembler être des abstractions impratiques, mais elles peuvent être utiles pour comprendre comment concevoir des outils pratiques.
Au passage, certains critères doivent être satisfaits par une BRDF pour être physiquement plausible. Premièrement, il n’est pas logique qu’une quantité négative de lumière soit réfléchie dans une direction quelconque. Deuxièmement, il n’est pas possible que la lumière totale réfléchie soit supérieure à la lumière incidente, bien que la surface puisse absorber une certaine énergie, de sorte que la lumière réfléchie peut être inférieure à la lumière incidente. Cette règle est généralement appelée la contrainte de normalisation. Un dernier principe, moins évident, respecté par les surfaces physiques est la réciprocité de Helmholtz : si nous choisissons deux directions arbitraires, la même fraction de lumière doit être réfléchie, quelle que soit la direction incidente et quelle que soit la direction sortante. En d’autres termes,
Réciprocité de Helmholtz
En raison de la réciprocité de Helmholtz, certains auteurs n’étiquettent pas les deux directions de la BRDF comme « entrante » et « sortante » car pour être physiquement plausible, le calcul doit être symétrique.
La BRDF contient la description complète de l’apparence d’un objet à un point donné, car elle décrit comment la surface réfléchira la lumière à ce point. Il est clair qu’une réflexion approfondie doit être consacrée à la conception de cette fonction. De nombreux modèles d’éclairage ont été proposés au cours des dernières décennies, et ce qui est surprenant est que l’un des premiers modèles, Blinn-Phong, est encore largement utilisé dans les graphismes temps réel aujourd’hui. Bien qu’il ne soit pas physiquement précis (ni plausible : il viole la contrainte de normalisation), nous l’étudions parce que c’est une bonne étape pédagogique et un élément important de l’histoire de l’infographie. En fait, qualifier Blinn-Phong d’« histoire » est du wishful thinking — peut-être la raison la plus importante d’étudier ce modèle est qu’il est encore si largement utilisé ! En fait, c’est le meilleur exemple du phénomène que nous avons mentionné au début de ce chapitre : des méthodes particulières présentées comme si elles étaient « la façon dont l’infographie fonctionne ».
Différents modèles d’éclairage ont différents objectifs. Certains sont meilleurs pour simuler des surfaces rugueuses, d’autres des surfaces avec plusieurs strates. Certains se concentrent sur la fourniture de « curseurs » intuitifs pour les artistes à contrôler, sans se préoccuper de savoir si ces curseurs ont une signification physique. D’autres sont basés sur la prise de surfaces réelles et leur mesure avec des caméras spéciales appelées goniophotomètres, en échantillonnant essentiellement la BRDF puis en utilisant l’interpolation pour reconstruire la fonction à partir des données tabulées. Le notable modèle Blinn-Phong discuté à la Section 10.6 est utile car il est simple, peu coûteux et bien compris des artistes. Consultez les sources dans la lecture suggérée pour un aperçu des modèles d’éclairage.
10.1.3Brève introduction à la colorimétrie et à la radiométrie
L’infographie consiste à mesurer la lumière, et vous devriez être conscient de certaines subtilités importantes, même si nous n’aurons pas le temps d’entrer dans tous les détails ici. La première concerne la façon de mesurer la couleur de la lumière, et la seconde la façon de mesurer sa luminosité.
Dans vos cours de sciences au collège, vous avez peut-être appris que chaque couleur de lumière est un mélange de lumière rouge, verte et bleue (RVB). C’est la conception populaire de la lumière, mais ce n’est pas tout à fait correct. La lumière peut prendre n’importe quelle fréquence unique dans la bande visible, ou elle peut être une combinaison de n’importe quel nombre de fréquences. La couleur est un phénomène de perception humaine et n’est pas tout à fait la même chose que la fréquence. En effet, différentes combinaisons de fréquences de lumière peuvent être perçues comme la même couleur — celles-ci sont connues sous le nom de métamères. Les combinaisons infinies de fréquences de lumière ressemblent un peu à tous les différents accords pouvant être joués sur un piano (et aussi les tons entre les touches). Dans cette métaphore, notre perception des couleurs est incapable de distinguer toutes les différentes notes individuelles, mais au lieu de cela, tout accord donné nous semble être une combinaison d’un do médian, d’un fa et d’un sol. Trois canaux de couleur n’est pas un nombre magique en ce qui concerne la physique ; c’est particulier à la vision humaine. La plupart des autres mammifères n’ont que deux types différents de récepteurs (nous les appellerions « daltoniens »), et les poissons, les reptiles et les oiseaux ont quatre types de récepteurs de couleur (ils nous appelleraient daltoniens).
Cependant, même les systèmes de rendu les plus avancés projettent le spectre continu de la lumière visible sur une base discrète, le plus souvent la base RVB. C’est une simplification omniprésente, mais nous voulions tout de même vous faire savoir que c’est une simplification, car elle ne rend pas compte de certains phénomènes. La base RVB n’est pas le seul espace colorimétrique, ni nécessairement le meilleur pour de nombreux objectifs, mais c’est une base très commode car c’est celle utilisée par la plupart des dispositifs d’affichage. À son tour, la raison pour laquelle cette base est utilisée par tant de dispositifs d’affichage est due à la similarité avec notre propre système visuel. Hall [11] décrit bien les lacunes du système RVB.
Étant donné que la partie visible du spectre électromagnétique est continue, une expression telle que est continue en termes de . Du moins, elle devrait l’être en théorie. En pratique, parce que nous produisons des images pour la consommation humaine, nous réduisons le nombre infini de différents à trois longueurs d’onde particulières. Habituellement, nous choisissons les trois longueurs d’onde comme celles perçues comme les couleurs rouge, verte et bleue. En pratique, vous pouvez considérer la présence de dans une équation comme un entier qui sélectionne lequel des trois « canaux de couleur » discrets est en cours de traitement.
Points clés sur la couleur
Décrire la distribution spectrale de la lumière nécessite une fonction continue, pas seulement trois nombres. Cependant, pour décrire la perception humaine de cette lumière, trois nombres sont essentiellement suffisants.
Le système RVB est un espace colorimétrique pratique, mais ce n’est pas le seul, et pas même le meilleur pour de nombreux objectifs pratiques. En pratique, nous traitons généralement la lumière comme étant une combinaison de rouge, vert et bleu car nous créons des images pour la consommation humaine.
Vous devriez également être conscient des différentes façons dont nous pouvons mesurer l’intensité de la lumière. Si nous adoptons un point de vue de la physique, nous considérons la lumière comme de l’énergie sous forme de rayonnement électromagnétique, et nous utilisons des unités de mesure du domaine de la radiométrie. La quantité la plus élémentaire est l’énergie rayonnante, qui dans le système SI est mesurée dans l’unité standard d’énergie, le joule (J). Tout comme tout autre type d’énergie, nous nous intéressons souvent au taux de flux d’énergie par unité de temps, qui est connu sous le nom de puissance. Dans le système SI, la puissance est mesurée en watts (W), ce qui est un joule par seconde (1 W = 1 J/s). La puissance sous forme de rayonnement électromagnétique est appelée puissance rayonnante ou flux radiant. Le terme « flux », qui vient du latin fluxus pour « écoulement », désigne une certaine quantité qui s’écoule à travers une certaine surface transversale. Ainsi, le flux radiant mesure la quantité totale d’énergie qui arrive, quitte ou traverse une certaine surface par unité de temps.
Imaginez qu’une certaine quantité de flux radiant soit émise par une surface de , tandis que cette même quantité de puissance est émise par une surface différente de . Clairement, la plus petite surface est « plus lumineuse » que la grande ; plus précisément, elle a un flux plus grand par unité de surface, également connu sous le nom de densité de flux. Le terme radiométrique pour la densité de flux, le flux radiant par unité de surface, est appelé radiosité, et dans le système SI il est mesuré en watts par mètre. La relation entre flux et radiosité est analogue à la relation entre force et pression ; confondre les deux mènera à des erreurs conceptuelles similaires.
Plusieurs termes équivalents existent pour la radiosité. Premièrement, notez que nous pouvons mesurer la densité de flux (ou le flux total, d’ailleurs) à travers n’importe quelle surface transversale. Nous pourrions mesurer la puissance rayonnante émise par une surface d’aire finie, ou la surface à travers laquelle la lumière s’écoule pourrait être une frontière imaginaire qui n’existe que mathématiquement (par exemple, la surface d’une sphère imaginaire qui entoure une source lumineuse). Bien que dans tous les cas nous mesurions la densité de flux, et donc le terme « radiosité » est tout à fait valide, nous pourrions également utiliser des termes plus spécifiques, selon que la lumière mesurée arrive ou part. Si la surface est une surface et que la lumière arrive sur la surface, le terme irradiance est utilisé. Si la lumière est émise par une surface, le terme exitance rayonnante ou émittance rayonnante est utilisé. Dans la synthèse d’images numériques, le mot « radiosité » est le plus souvent utilisé pour désigner la lumière qui quitte une surface, ayant été réfléchie ou émise.
Lorsque nous parlons de la luminosité en un point particulier, nous ne pouvons pas utiliser simplement la puissance rayonnante ordinaire car l’aire de ce point est infinitésimale (essentiellement nulle). Nous pouvons parler de la densité de flux en un seul point, mais pour mesurer le flux, nous avons besoin d’une aire finie sur laquelle mesurer. Pour une surface d’aire finie, si nous avons un seul nombre qui caractérise le total pour toute la surface, il sera mesuré en flux, mais pour capturer le fait que différents emplacements au sein de cette aire peuvent être plus lumineux que d’autres, nous utilisons une fonction qui varie sur la surface et qui mesurera la densité de flux.
Nous sommes maintenant prêts à considérer ce qui est peut-être la quantité la plus centrale que nous devons mesurer en infographie : l’intensité d’un « rayon » de lumière. Nous pouvons voir pourquoi la radiosité n’est pas l’unité appropriée en étendant les idées du paragraphe précédent. Imaginez un point de surface entouré d’un dôme émissif recevant une certaine quantité d’irradiance provenant de toutes les directions dans l’hémisphère centré sur la normale de surface locale. Imaginez maintenant un deuxième point de surface subissant la même quantité d’irradiance, mais toute l’illumination provient d’une seule direction, dans un faisceau très mince. Intuitivement, nous pouvons voir qu’un rayon le long de ce faisceau est d’une certaine façon « plus lumineux » que n’importe quel rayon illuminant le premier point de surface. L’irradiance est d’une certaine façon « plus dense ». Elle est plus dense par unité d’angle solide.
L’idée d’un angle solide est probablement nouvelle pour certains lecteurs, mais nous pouvons facilement comprendre l’idée en la comparant aux angles dans le plan. Un angle « ordinaire » est mesuré (en radians) sur la base de la longueur de sa projection sur le cercle unitaire. De la même manière, un angle solide mesure l’aire projetée sur la sphère unitaire entourant le point. L’unité SI de l’angle solide est le stéradian, abrégé « sr ». La sphère complète a sr ; un hémisphère englobe sr.
Figure 10.1 Les deux surfaces reçoivent des faisceaux de lumière identiques, mais la surface du bas a une plus grande aire, et a donc une irradiance plus faible.
En mesurant la radiance par unité d’angle solide, nous pouvons exprimer l’intensité de la lumière en un certain point comme une fonction qui varie en fonction de la direction d’incidence. Nous sommes très proches d’avoir l’unité de mesure qui décrit l’intensité d’un rayon. Il y a juste un léger problème, illustré par la Figure 10.1, qui est un gros plan d’un très mince pinceau de rayons lumineux frappant une surface. En haut, les rayons frappent la surface perpendiculairement, et en bas, des rayons lumineux de même intensité frappent une surface différente à un angle. Le point clé est que l’aire de la surface supérieure est plus petite que l’aire de la surface inférieure ; par conséquent, l’irradiance sur la surface supérieure est plus grande que l’irradiance sur la surface inférieure, malgré le fait que les deux surfaces sont éclairées par le « même nombre » de rayons lumineux identiques. Ce phénomène de base, selon lequel l’angle de la surface fait que les rayons lumineux incidents se dispersent et contribuent ainsi moins à l’irradiance, est connu sous le nom de loi de Lambert. Nous avons plus à dire sur la loi de Lambert à la Section 10.6.3, mais pour l’instant, l’idée clé est que la contribution d’un faisceau de lumière à l’irradiance sur une surface dépend de l’angle de cette surface.
En raison de la loi de Lambert, l’unité que nous utilisons en infographie pour mesurer l’intensité d’un rayon, la radiance, est définie comme le flux radiant par unité d’aire projetée, par unité d’angle solide. Pour mesurer une aire projetée, nous prenons l’aire de surface réelle et la projetons sur le plan perpendiculaire au rayon. (Dans la Figure 10.1, imaginez prendre la surface du bas et la projeter vers le haut sur la surface du haut). Cela contrebalance essentiellement la loi de Lambert.
La Table 10.1 résume les termes radiométriques les plus importants.
| Grandeur | Unités | Unité SI | Traduction approximative |
| Énergie rayonnante | Énergie | Illumination totale pendant un intervalle de temps | |
| Flux radiant | Puissance | Luminosité d’une aire finie dans toutes les directions | |
| Densité de flux radiant | Puissance par unité de surface | Luminosité d’un point unique dans toutes les directions | |
| Irradiance | Puissance par unité de surface | Densité de flux radiant de la lumière incidente | |
| Exitance rayonnante | Puissance par unité de surface | Densité de flux radiant de la lumière émise | |
| Radiosité | Puissance par unité de surface | Densité de flux radiant de la lumière émise ou réfléchie | |
| Radiance | Puissance par unité d’aire projetée, par unité d’angle solide | Luminosité d’un rayon |
Table 10.1Termes radiométriques courants
Alors que la radiométrie adopte le point de vue de la physique en mesurant l’énergie brute de la lumière, le domaine de la photométrie pondère cette même lumière en utilisant l’œil humain. Pour chacun des termes radiométriques correspondants, il existe un terme similaire en photométrie (Table 10.2). La seule vraie différence est une conversion non linéaire de l’énergie brute à la luminosité perçue.
| Terme radiométrique | Terme photométrique | Unité SI photométrique |
| Énergie rayonnante | Énergie lumineuse | talbot, ou lumen-seconde ( ) |
| Flux radiant | Flux lumineux, puissance lumineuse | lumen ( ) |
| Irradiance | Éclairement | lux ( ) |
| Exitance rayonnante | Exitance lumineuse | lux ( ) |
| Radiance | Luminance |
Table 10.2Unités de mesure de la radiométrie et de la photométrie
Tout au long du reste de ce chapitre, nous essayons d’utiliser les unités radiométriques appropriées quand c’est possible. Cependant, les réalités pratiques de l’infographie rendent l’utilisation d’unités appropriées confuse, pour deux raisons particulières. Il est courant en infographie d’avoir besoin d’effectuer une intégrale sur un « signal » — par exemple, la couleur d’une surface. En pratique, nous ne pouvons pas effectuer l’intégrale analytiquement, et nous devons donc l’intégrer numériquement, ce qui revient à prendre une moyenne pondérée de nombreux échantillons. Bien que mathématiquement nous prenons une moyenne pondérée (ce qui normalement ne causerait pas de changement d’unités), en fait ce que nous faisons c’est intégrer, et cela signifie que chaque échantillon est réellement multiplié par une quantité différentielle, comme une aire différentielle ou un angle solide différentiel, ce qui provoque un changement des unités physiques. Une deuxième source de confusion est que, bien que de nombreux signaux aient un domaine non nul fini dans le monde réel, ils sont représentés dans un ordinateur par des signaux qui sont non nuls en un seul point. (Mathématiquement, nous disons que le signal est un multiple d’un delta de Dirac ; voir la Section 12.4.3.) Par exemple, une source lumineuse du monde réel a une aire finie, et nous nous intéresserions à la radiance de la lumière en un point donné sur la surface émissive, dans une direction donnée. En pratique, nous imaginons réduire l’aire de cette lumière à zéro tout en maintenant le flux radiant constant. La densité de flux devient infinie en théorie. Ainsi, pour une lumière de surface réelle, nous aurions besoin d’un signal pour décrire la densité de flux, tandis que pour une lumière ponctuelle, la densité de flux devient infinie et nous décrivons à la place la luminosité de la lumière par son flux total. Nous répéterons ces informations lorsque nous parlerons des lumières ponctuelles.
Points clés sur la radiométrie
Les mots vagues tels que « intensité » et « luminosité » sont mieux évités lorsque les termes radiométriques plus spécifiques peuvent être utilisés. L’échelle de nos nombres n’est pas si importante et nous n’avons pas besoin d’utiliser des unités SI du monde réel, mais il est utile de comprendre ce que mesurent les différentes grandeurs radiométriques pour éviter de mélanger des grandeurs de façon inappropriée.
Utiliser le flux radiant pour mesurer la luminosité totale d’une aire finie, dans toutes les directions.
Utiliser la densité de flux radiant pour mesurer la luminosité en un seul point, dans toutes les directions. L’irradiance et l’exitance rayonnante désignent la densité de flux radiant de la lumière incidente et émise, respectivement. La radiosité est la densité de flux radiant de la lumière qui quitte une surface, qu’elle soit réfléchie ou émise.
En raison de la loi de Lambert, un rayon donné contribue davantage à l’irradiance différentielle lorsqu’il frappe une surface à un angle perpendiculaire par rapport à un angle rasant.
Utiliser la radiance pour mesurer la luminosité d’un rayon. Plus précisément, la radiance est le flux par unité d’angle projeté, par angle solide. Nous utilisons l’aire projetée de sorte que la valeur pour un rayon donné soit une propriété du rayon seul et ne dépende pas de l’orientation de la surface utilisée pour mesurer la densité de flux.
Les réalités pratiques contrecarrent nos meilleures intentions de faire les choses « correctement » en ce qui concerne l’utilisation d’unités appropriées. L’intégration numérique ressemble beaucoup à une prise de moyenne pondérée, ce qui cache le changement d’unités qui se produit réellement. Les lumières ponctuelles et autres deltas de Dirac ajoutent une confusion supplémentaire.
10.1.4L’équation de rendu
Adaptons maintenant la BRDF à l’algorithme de rendu. À l’étape 2 de notre algorithme de rendu (Section 10.1), nous essayons de déterminer la radiance quittant une surface particulière dans la direction de notre œil. La seule façon pour que cela se produise est que la lumière arrive depuis une certaine direction sur la surface et soit réfléchie dans notre direction. Avec la BRDF, nous avons maintenant un moyen de mesurer cela. Considérons toutes les directions potentielles depuis lesquelles la lumière pourrait être incidente sur la surface, qui forment un hémisphère centré en , orienté selon la normale de surface locale . Pour chaque direction potentielle , nous mesurons la couleur de la lumière incidente depuis cette direction. La BRDF nous indique quelle fraction de la radiance provenant de est réfléchie dans la direction vers notre œil (par opposition à dispersée dans une autre direction ou absorbée). En sommant la radiance réfléchie vers sur toutes les directions incidentes possibles, nous obtenons la radiance totale réfléchie le long de dans notre œil. Nous ajoutons la lumière réfléchie à toute lumière qui est émise par la surface dans notre direction (qui est nulle pour la plupart des surfaces), et voilà, nous avons la radiance totale. En notation mathématique, nous avons l’équation de rendu.
L’équation de rendu
Bien que l’Équation (10.1) soit aussi fondamentale qu’elle puisse l’être, son développement est relativement récent, ayant été publié au SIGGRAPH en 1986 par Kajiya [13]. De plus, c’était le résultat de, plutôt que la cause de, nombreuses stratégies pour produire des images réalistes. Les chercheurs en infographie ont poursuivi la création d’images par différentes techniques qui leur semblaient logiques avant d’avoir un cadre pour décrire le problème qu’ils essayaient de résoudre. Et pendant de nombreuses années après cela, la plupart d’entre nous dans l’industrie des jeux vidéo ignoraient que le problème que nous essayions de résoudre avait finalement été clairement défini. (Beaucoup le sont encore.)
Maintenant, traduisons cette équation en langage courant et voyons ce qu’elle signifie. Premièrement, remarquez que et apparaissent dans chaque fonction. Toute l’équation régit un équilibre de radiance en un seul point de surface pour une seule longueur d’onde (« canal de couleur ») . Donc cette équation d’équilibre s’applique à chaque canal de couleur individuellement, en tous les points de surface simultanément.
Le terme du côté gauche du signe d’égalité est simplement « la radiance quittant le point dans la direction ». Bien sûr, si est la surface visible à un pixel donné, et est la direction de vers l’œil, alors cette grandeur est exactement ce dont nous avons besoin pour déterminer la couleur du pixel. Mais notez que l’équation est plus générale, nous permettant de calculer la radiance sortante dans toute direction arbitraire et pour tout point donné , que pointe ou non vers notre œil.
Du côté droit, nous avons une somme. Le premier terme de la somme est « la radiance émise par dans la direction » et sera non nulle uniquement pour les surfaces émissives spéciales. Le deuxième terme, l’intégrale, est « la lumière réfléchie par dans la direction de ». Ainsi, d’un point de vue général, l’équation de rendu semblerait énoncer la relation plutôt évidente
Maintenant, disséquons cette intégrale intimidante. (Au fait, si vous n’avez pas eu de calcul et n’avez pas encore lu le Chapitre 11, remplacez simplement le mot « intégrale » par « somme », et vous ne manquerez pas l’essentiel de cette section.) Nous avons en fait déjà discuté de son fonctionnement lorsque nous avons parlé de la BRDF, mais répétons-le avec des mots différents. Nous pourrions réécrire l’intégrale comme
Notez que le symbole (oméga grec majuscule) apparaît là où nous écririons normalement les bornes d’intégration. Il est censé signifier « sommer sur l’hémisphère des directions entrantes possibles ». Pour chaque direction entrante , nous déterminons quelle radiance était incidente dans cette direction entrante et a été dispersée dans la direction sortante . La somme de toutes ces contributions provenant de toutes les différentes directions incidentes donne la radiance totale réfléchie dans la direction . Bien sûr, il y a un nombre infini de directions incidentes, c’est pourquoi il s’agit d’une intégrale. En pratique, nous ne pouvons pas évaluer l’intégrale analytiquement, et nous devons échantillonner un nombre discret de directions, transformant le « » en « ».
Il nous reste maintenant à disséquer l’intégrande. C’est un produit de trois facteurs :
Le premier facteur désigne la radiance incidente depuis la direction de . Le facteur suivant est simplement la BRDF, qui nous indique quelle fraction de la radiance incidente depuis cette direction particulière sera réfléchie dans la direction sortante qui nous intéresse. Finalement, nous avons le facteur de Lambert. Comme discuté à la Section 10.1.2, cela rend compte du fait que davantage de lumière incidente est disponible pour être réfléchie, par unité de surface, lorsque est perpendiculaire à la surface que lorsqu’il est à un angle rasant. Le vecteur est la normale de surface dirigée vers l’extérieur ; le produit scalaire atteint son maximum de 1 dans la direction perpendiculaire et diminue jusqu’à zéro à mesure que l’angle d’incidence devient plus rasant. Nous rediscutons du facteur de Lambert à la Section 10.6.3.
En termes purement mathématiques, l’équation de rendu est une équation intégrale : elle énonce une relation entre une fonction inconnue , la distribution de la lumière sur les surfaces de la scène, en termes de sa propre intégrale. Il peut ne pas être évident que l’équation de rendu soit récursive, mais apparaît en fait des deux côtés du signe d’égalité. Il apparaît dans l’évaluation de , qui est précisément l’expression que nous cherchons à résoudre pour chaque pixel : quelle est la radiance incidente sur un point depuis une direction donnée ? Ainsi, pour trouver la radiance quittant un point , nous devons connaître toute la radiance incidente en depuis toutes les directions. Mais la radiance incidente sur est la même que la radiance quittant toutes les autres surfaces visibles depuis , dans la direction pointant de l’autre surface vers .
Pour rendre une scène de manière réaliste, nous devons résoudre l’équation de rendu, ce qui nous oblige à connaître (en théorie) non seulement la radiance arrivant à la caméra, mais aussi toute la distribution de la radiance dans la scène dans chaque direction en chaque point. Clairement, c’est trop demander à un ordinateur digital fini, car l’ensemble des emplacements de surface et l’ensemble des directions incidentes/sortantes potentielles sont infinis. Le véritable art dans la création de logiciels pour la synthèse d’images numériques consiste à allouer le temps de traitement et la mémoire limités de la façon la plus efficace possible, pour faire la meilleure approximation possible.
Le pipeline de rendu simple que nous présentons à la Section 10.10 ne tient compte que de la lumière directe. Il ne tient pas compte de la lumière indirecte qui a rebondi sur une surface et est arrivée sur une autre. En d’autres termes, il ne fait qu’un « niveau de récursion » dans l’équation de rendu. Une composante immense des images réalistes est de tenir compte de la lumière indirecte — résoudre l’équation de rendu plus complètement. Les diverses méthodes pour accomplir cela sont connues sous le nom de techniques d’illumination globale.
Ceci conclut notre présentation de haut niveau du fonctionnement de l’infographie. Bien que nous admettions ne pas encore avoir présenté une seule idée pratique, nous pensons qu’il est très important de comprendre ce que vous essayez d’approximer avant de commencer à l’approximer. Même si les compromis que nous sommes forcés de faire pour le temps réel sont assez sévères, la puissance de calcul disponible augmente. Un programmeur de jeux vidéo dont la seule exposition à l’infographie a été des tutoriels OpenGL ou des démos faites par des fabricants de cartes graphiques ou des livres axés exclusivement sur le rendu en temps réel aura beaucoup plus de difficultés à comprendre même les techniques d’illumination globale d’aujourd’hui, et encore moins celles de demain.
10.2Visualisation en 3D
Avant de rendre une scène, nous devons choisir une caméra et une fenêtre. C’est-à-dire que nous devons décider depuis où la rendre (la position, l’orientation et le zoom de la vue) et vers où la rendre (le rectangle sur l’écran). La fenêtre de sortie est la plus simple des deux, et nous la discuterons donc en premier.
La Section 10.2.1 décrit comment spécifier la fenêtre de sortie. La Section 10.2.2 discute du rapport d’aspect des pixels. La Section 10.2.3 introduit le tronc de vue (view frustum). La Section 10.2.4 décrit les angles de champ de vision et le zoom.
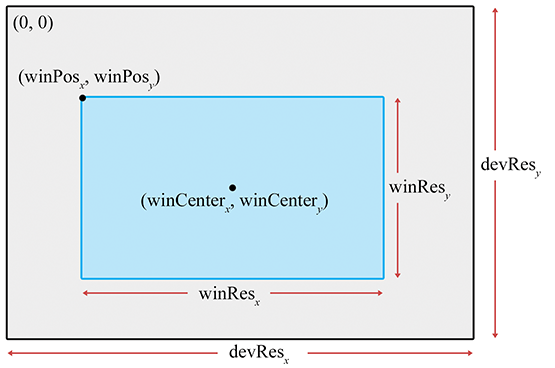
Figure 10.2Spécification de la fenêtre de sortie
10.2.1Spécification de la fenêtre de sortie
Nous n’avons pas à rendre notre image sur tout l’écran. Par exemple, dans les jeux multijoueurs en écran partagé, chaque joueur reçoit une portion de l’écran. La fenêtre de sortie désigne la portion du dispositif de sortie où notre image sera rendue. C’est illustré dans la Figure 10.2.
La position de la fenêtre est spécifiée par les coordonnées du pixel en haut à gauche . Les entiers et sont les dimensions de la fenêtre en pixels. La définir de cette façon, en utilisant la taille de la fenêtre plutôt que les coordonnées du coin inférieur droit, évite certaines questions épineuses causées par les coordonnées de pixels entières. Nous faisons également attention à distinguer entre la taille de la fenêtre en pixels et la taille physique de la fenêtre. Cette distinction deviendra importante à la Section 10.2.2.
Cela dit, il est important de réaliser que nous n’avons pas nécessairement besoin de rendre sur l’écran du tout. Nous pourrions rendre dans un tampon à sauvegarder dans un fichier .TGA ou en tant que trame dans un .AVI, ou nous pourrions rendre dans une texture comme sous-processus du rendu « principal », pour produire une carte d’ombres, un reflet, ou l’image sur un moniteur dans le monde virtuel. Pour ces raisons, le terme cible de rendu (render target) est souvent utilisé pour désigner la destination actuelle de la sortie de rendu.
10.2.2Rapport d’aspect des pixels
Que nous rendions sur l’écran ou dans un tampon hors-écran, nous devons connaître le rapport d’aspect des pixels, qui est le rapport de la hauteur d’un pixel à sa largeur. Ce rapport est souvent 1:1 — c’est- à-dire, nous avons des pixels « carrés » — mais ce n’est pas toujours le cas ! Nous donnons quelques exemples ci-dessous, mais il est courant que cette hypothèse passe sans être remise en question et devienne la source de correctifs compliqués appliqués au mauvais endroit, pour corriger des images étirées ou écrasées.
La formule pour calculer le rapport d’aspect est
Calcul du rapport d’aspect des pixels
La notation désigne la taille physique d’un pixel, et est la hauteur et la largeur physiques du dispositif sur lequel l’image est affichée. Pour les deux grandeurs, les mesures individuelles peuvent être inconnues, mais ce n’est pas grave car le rapport est tout ce dont nous avons besoin, et celui-ci est généralement connu. Par exemple, les moniteurs de bureau standards sont de toutes sortes de tailles, mais la zone visible de nombreux anciens moniteurs a un rapport de 4:3, ce qui signifie qu’elle est 33% plus large que haute. Un autre rapport courant est 16:9 ou plus large7 sur les téléviseurs haute définition. Les entiers et sont le nombre de pixels dans les dimensions et . Par exemple, une résolution de signifie que et .
Mais, comme déjà mentionné, nous traitons souvent des pixels carrés avec un rapport d’aspect de 1:1. Par exemple, sur un moniteur de bureau avec un rapport largeur:hauteur physique de 4:3, certaines résolutions courantes donnant des rapports de pixels carrés sont , , et . Sur les moniteurs 16:9, les résolutions courantes sont , , . Le rapport d’aspect 8:5 (plus communément connu sous le nom de 16:10) est aussi très courant, pour les tailles de moniteurs de bureau et de téléviseurs. Certaines résolutions d’affichage courantes en 16:10 sont , , , et . En fait, sur PC, il est courant d’assumer simplement un rapport de pixels de 1:1, car il peut être impossible d’obtenir les dimensions du dispositif d’affichage. Les jeux sur console ont la tâche plus facile à cet égard.
Notez que nulle part dans ces calculs la taille ou l’emplacement de la fenêtre n’est utilisé ; l’emplacement et la taille de la fenêtre de rendu n’ont aucune incidence sur les proportions physiques d’un pixel. Cependant, la taille de la fenêtre deviendra importante lorsque nous discuterons du champ de vision à la Section 10.2.4, et la position est importante lorsque nous passons de l’espace caméra à l’espace écran à la Section 10.3.5.
À ce stade, certains lecteurs pourraient se demander en quoi cette discussion a du sens dans le contexte du rendu sur un bitmap, où le mot « physique » impliqué par les noms de variables et ne s’applique pas. Dans la plupart de ces situations, il est approprié d’agir simplement comme si le rapport d’aspect des pixels était de 1:1. Dans certaines circonstances particulières, cependant, vous pourriez vouloir rendre anamorphiquement, produisant une image écrasée dans le bitmap qui sera ensuite étirée lorsque le bitmap est utilisé.
10.2.3Le tronc de vue
Le tronc de vue (view frustum) est le volume de l’espace potentiellement visible pour la caméra. Il a la forme d’une pyramide avec la pointe coupée. Un exemple de tronc de vue est montré dans la Figure 10.3.
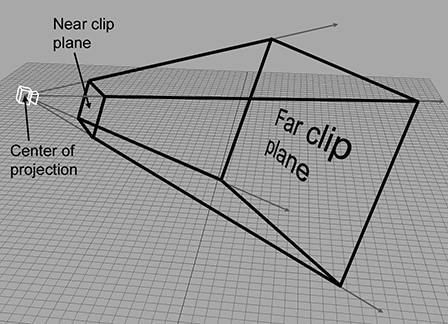
Figure 10.3Le tronc de vue 3D
Le tronc de vue est délimité par six plans, connus sous le nom de plans de découpe (clip planes). Les quatre premiers plans forment les côtés de la pyramide et sont appelés les plans supérieur, gauche, inférieur et droit, pour des raisons évidentes. Ils correspondent aux côtés de la fenêtre de sortie. Les plans de découpe proche et lointain, qui correspondent à certaines valeurs de l’espace caméra, nécessitent un peu plus d’explication.
La raison du plan de découpe lointain est peut-être plus facile à comprendre. Il empêche le rendu des objets au-delà d’une certaine distance. Il y a deux raisons pratiques pour lesquelles un plan de découpe lointain est nécessaire. La première est relativement facile à comprendre : un plan de découpe lointain peut limiter le nombre d’objets à rendre dans un environnement extérieur. La deuxième raison est légèrement plus compliquée, mais essentiellement elle a à voir avec la façon dont les valeurs du tampon de profondeur sont attribuées. Par exemple, si les entrées du tampon de profondeur sont en virgule fixe sur 16 bits, alors la valeur de profondeur maximale pouvant être stockée est 65 535. La découpe lointaine établit quelle valeur (en virgule flottante) de dans l’espace caméra correspondra à la valeur maximale pouvant être stockée dans le tampon de profondeur. La motivation pour le plan de découpe proche devra attendre jusqu’à ce que nous discutions de l’espace de découpe (clip space) à la Section 10.3.2.
Notez que chacun des plans de découpe sont des plans, en insistant sur le fait qu’ils s’étendent à l’infini. Le volume de vue est l’intersection des six demi-espaces définis par les plans de découpe.
10.2.4Champ de vision et zoom
Une caméra a une position et une orientation, tout comme tout autre objet dans le monde. Cependant, elle a également une propriété supplémentaire connue sous le nom de champ de vision (field of view). Un autre terme que vous connaissez probablement est le zoom. Intuitivement, vous savez déjà ce que signifie « zoomer en avant » et « zoomer en arrière ». Lorsque vous zoomez en avant, l’objet que vous regardez semble plus grand à l’écran, et lorsque vous zoomez en arrière, la taille apparente de l’objet est plus petite. Voyons si nous pouvons développer cette intuition en une définition plus précise.
Le champ de vision (CDV ou FOV) est l’angle intercepté par le tronc de vue. Nous avons en réalité besoin de deux angles : un champ de vision horizontal et un champ de vision vertical. Revenons brièvement en 2D et considérons seulement l’un de ces angles. La Figure 10.4 montre le tronc de vue vu de dessus, illustrant précisément l’angle que mesure le champ de vision horizontal. L’étiquetage des axes illustre l’espace caméra, discuté à la Section 10.3.
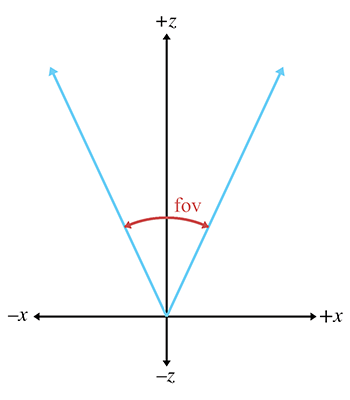
Figure 10.4Champ de vision horizontal
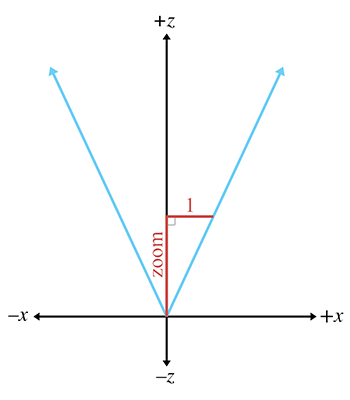
Figure 10.5Interprétation géométrique du zoom
Le zoom mesure le rapport de la taille apparente de l’objet par rapport à un champ de vision de . Par exemple, un zoom de 2,0 signifie que l’objet apparaîtra deux fois plus grand à l’écran qu’avec un champ de vision de . Donc des valeurs de zoom plus grandes font que l’image à l’écran devient plus grande (« zoom avant »), et des valeurs de zoom plus petites font que les images à l’écran deviennent plus petites (« zoom arrière »).
Le zoom peut être interprété géométriquement comme le montre la Figure 10.5. En utilisant quelques trigonométries de base, nous pouvons dériver la conversion entre zoom et champ de vision :
Conversion entre zoom et champ de vision
Notez la relation inverse entre zoom et champ de vision. À mesure que le zoom augmente, le champ de vision diminue, faisant se rétrécir le tronc de vue. Cela peut ne pas sembler intuitif au premier abord, mais lorsque le tronc de vue se rétrécit, la taille perçue des objets visibles augmente.
Le champ de vision est une mesure commode pour les humains, mais comme nous le découvrons à la Section 10.3.4, le zoom est la mesure dont nous avons besoin pour alimenter le pipeline graphique.
Nous avons besoin de deux angles de champ de vision différents (ou valeurs de zoom), un horizontal et un vertical. Nous sommes certainement libres de choisir deux valeurs arbitraires, mais si nous ne maintenons pas une relation appropriée entre ces valeurs, l’image rendue semblera étirée. Si vous avez déjà regardé un film destiné à l’écran large qui a simplement été écrasé anamorphiquement pour tenir sur un téléviseur normal, ou regardé du contenu 4:3 sur un téléviseur 16:9 en mode « plein »8, alors vous avez vu cet effet.
Pour maintenir des proportions correctes, les valeurs de zoom doivent être inversement proportionnelles aux dimensions physiques de la fenêtre de sortie :
La relation habituelle entre le zoom vertical et horizontal
La variable désigne la taille physique de la fenêtre de sortie. Comme indiqué dans l’Équation (10.4), même si nous ne connaissons généralement pas la taille réelle de la fenêtre de rendu, nous pouvons déterminer son rapport d’aspect. Mais comment faire ? En général, tout ce que nous connaissons est la résolution (nombre de pixels) de la fenêtre de sortie. C’est là que les calculs de rapport d’aspect des pixels de la Section 10.2.2 entrent en jeu :
Dans cette formule,
désigne les valeurs de zoom de la caméra,
désigne la taille physique de la fenêtre,
désigne la résolution de la fenêtre, en pixels,
désigne les dimensions physiques d’un pixel,
désigne les dimensions physiques du dispositif de sortie. Rappelons que nous ne connaissons généralement pas les tailles individuelles, mais nous connaissons le rapport,
désigne la résolution du dispositif de sortie.
De nombreux packages de rendu vous permettent de spécifier seulement un angle de champ de vision (ou une valeur de zoom). Lorsque vous faites cela, ils calculent automatiquement l’autre valeur pour vous, en supposant que vous voulez des proportions d’affichage uniformes. Par exemple, vous pouvez spécifier le champ de vision horizontal, et ils calculent le champ de vision vertical pour vous.
Maintenant que nous savons comment décrire le zoom d’une manière adaptée à un ordinateur, que faisons-nous de ces valeurs de zoom ? Elles entrent dans la matrice de découpe (clip matrix), décrite à la Section 10.3.4.
10.2.5Projection orthographique
La discussion jusqu’à présent a porté sur la projection en perspective, qui est le type de projection le plus couramment utilisé, car c’est ainsi que nos yeux perçoivent le monde. Cependant, dans de nombreuses situations, la projection orthographique est également utile. Nous avons introduit la projection orthographique à la Section 5.3 ; pour rappeler brièvement, en projection orthographique, les lignes de projection (les lignes qui relient tous les points de l’espace qui se projettent sur les mêmes coordonnées d’écran) sont parallèles, plutôt que de se croiser en un seul point. Il n’y a pas de raccourcissement de perspective en projection orthographique ; un objet apparaîtra à la même taille à l’écran quelle que soit sa distance, et déplacer la caméra en avant ou en arrière selon la direction de visualisation n’a aucun effet apparent tant que les objets restent devant le plan de découpe proche.
La Figure 10.6 montre une scène rendue depuis la même position et orientation, en comparant la projection en perspective et la projection orthographique. À gauche, notez qu’avec la projection en perspective, les lignes parallèles ne restent pas parallèles, et les carrés de la grille plus proches sont plus grands que ceux dans le fond. Avec la projection orthographique, les carrés de la grille ont tous la même taille et les lignes de la grille restent parallèles.
 |
 |
| Projection en perspective | Projection orthographique |
Figure 10.6Projection en perspective versus orthographique
Les vues orthographiques sont très utiles pour les vues « schématiques » et d’autres situations où les distances et les angles doivent être mesurés avec précision. Tout outil de modélisation supportera ce type de vue. Dans un jeu vidéo, vous pourriez utiliser une vue orthographique pour rendre une carte ou un autre élément HUD.
Pour une projection orthographique, il n’est pas logique de parler du « champ de vision » comme d’un angle, car le tronc de vue a la forme d’une boîte, pas d’une pyramide. Plutôt que de définir les dimensions et du tronc de vue en termes de deux angles, nous donnons deux tailles : la largeur et la hauteur physiques de la boîte.
La valeur de zoom a une signification différente en projection orthographique par rapport à la perspective. Elle est liée à la taille physique de la boîte du tronc :
Conversion entre zoom et taille du tronc en projection orthographique
Comme pour les projections en perspective, il y a deux valeurs de zoom différentes, une pour et une pour , et leur rapport doit être coordonné avec le rapport d’aspect de la fenêtre de rendu pour éviter de produire une image « écrasée ». Nous avons développé l’Équation (10.5) avec la projection en perspective en tête, mais cette formule régit également la relation appropriée pour la projection orthographique.
10.3Espaces de coordonnées
Cette section passe en revue plusieurs espaces de coordonnées importants liés à la visualisation 3D. Malheureusement, la terminologie n’est pas cohérente dans la littérature sur le sujet, même si les concepts le sont. Ici, nous discutons des espaces de coordonnées dans l’ordre dans lequel ils sont rencontrés au fur et à mesure que la géométrie circule dans le pipeline graphique.
10.3.1Espace modèle, monde et caméra
La géométrie d’un objet est initialement décrite dans l’espace objet, qui est un espace de coordonnées local à l’objet décrit (voir la Section 3.2.2). L’information décrite consiste généralement en des positions de sommets et des normales de surface. L’espace objet est également connu sous le nom d’espace local et, surtout dans le contexte de l’infographie, d’espace modèle.
Depuis l’espace modèle, les sommets sont transformés dans l’espace monde (voir la Section 3.2.1). La transformation de l’espace de modélisation vers l’espace monde est souvent appelée la transformation modèle. Typiquement, l’éclairage de la scène est spécifié dans l’espace monde, bien que, comme nous le voyons à la Section 10.11, cela n’ait pas vraiment d’importance quel espace de coordonnées est utilisé pour effectuer les calculs d’éclairage, à condition que la géométrie et les lumières puissent être exprimées dans le même espace.
Depuis l’espace monde, les sommets sont transformés par la transformation vue dans l’espace caméra (voir la Section 3.2.3), également connu sous le nom d’espace œil et d’espace vue (à ne pas confondre avec l’espace volume de vue canonique, discuté plus loin). L’espace caméra est un espace de coordonnées 3D dans lequel l’origine est au centre de projection, un axe est parallèle à la direction vers laquelle la caméra pointe (perpendiculaire au plan de projection), un axe est l’intersection des plans de découpe supérieur et inférieur, et l’autre axe est l’intersection des plans de découpe gauche et droit. Si nous adoptons la perspective de la caméra, alors un axe sera « horizontal » et un sera « vertical ».
Dans un monde à main gauche, la convention la plus courante est que pointe dans la direction vers laquelle la caméra fait face, avec et pointant vers la « droite » et vers le « haut » (toujours depuis la perspective de la caméra). C’est assez intuitif, comme le montre la Figure 10.7. La convention typique à main droite est que pointe dans la direction vers laquelle la caméra fait face. Nous supposons les conventions à main gauche pour le reste de ce chapitre.
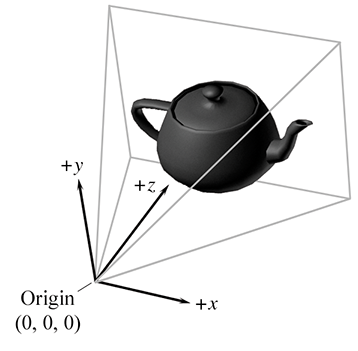
Figure 10.7Conventions typiques de l’espace caméra pour les systèmes de coordonnées à main gauche
10.3.2Espace de découpe et matrice de découpe
Depuis l’espace caméra, les sommets sont transformés à nouveau dans l’espace de découpe (clip space), également connu sous le nom d’espace volume de vue canonique. La matrice qui transforme les sommets de l’espace caméra en espace de découpe est appelée la matrice de découpe (clip matrix), également connue sous le nom de matrice de projection.
Jusqu’à présent, nos positions de sommets étaient des vecteurs 3D « purs » — c’est-à-dire qu’ils n’avaient que trois coordonnées, ou s’ils avaient une quatrième coordonnée, alors était toujours égal à 1 pour les vecteurs de position et 0 pour les vecteurs de direction tels que les normales de surface. (Dans certaines situations particulières, nous pourrions utiliser des transformations plus exotiques, mais la plupart des transformations de base sont des transformations affines 3D.) La matrice de découpe, cependant, met des informations significatives dans . La matrice de découpe remplit deux fonctions principales :
Préparer la projection. Nous mettons la valeur appropriée dans de sorte que la division homogène produise la projection souhaitée. Pour la projection en perspective typique, cela signifie que nous copions dans . Nous en parlons à la Section 10.3.3.
Appliquer le zoom et préparer le découpage. Nous mettons à l’échelle , et de sorte qu’ils puissent être comparés à pour le découpage. Cette mise à l’échelle tient compte des valeurs de zoom de la caméra, car ces valeurs de zoom affectent la forme du tronc de vue contre lequel le découpage se produit. Ceci est discuté à la Section 10.3.4.
10.3.3La matrice de découpe : préparer la projection
Rappelons d’après la Section 6.4.1 qu’un vecteur homogène 4D est mappé sur le vecteur physique 3D correspondant en divisant par :
Conversion de coordonnées homogènes 4D en 3D
Le premier objectif de la matrice de découpe est d’obtenir la valeur correcte dans de sorte que cette division provoque la projection souhaitée (perspective ou orthographique). C’est la raison pour laquelle cette matrice est parfois appelée matrice de projection, bien que ce terme soit un peu trompeur — la projection n’a pas lieu lors de la multiplication par cette matrice, elle se produit lorsque nous divisons , et par .
Si c’était le seul but de la matrice de découpe, de placer la valeur correcte dans , la matrice de découpe pour la projection en perspective serait simplement
Une matrice triviale pour définir , pour la projection en perspective
En multipliant un vecteur de la forme par cette matrice, puis en effectuant la division homogène par , on obtient
À ce stade, de nombreux lecteurs pourraient raisonnablement poser deux questions. La première question pourrait être : « Pourquoi est-ce si compliqué ? Cela semble beaucoup de travail pour accomplir ce qui revient essentiellement à diviser par . » Vous avez raison. Dans de nombreux anciens rastériseurs logiciels, où les mathématiques de projection étaient codées à la main, n’apparaissait nulle part, et il y avait juste une division explicite par . Alors pourquoi tolérons-nous toute cette complication ? L’une des raisons pour les coordonnées homogènes est qu’elles peuvent représenter une gamme plus large de spécifications de caméra naturellement. À la fin de cette section, nous verrons comment les projections orthographiques peuvent être gérées facilement, sans l’« instruction if » qui était nécessaire dans les anciens systèmes codés à la main. Mais il existe d’autres types de projections qui sont également utiles et sont gérées naturellement dans ce cadre. Par exemple, les plans du tronc n’ont pas besoin d’être symétriques par rapport à la direction de visualisation, ce qui correspond à la situation où votre direction de vue ne passe pas par le centre de la fenêtre. Ceci est utile, par exemple, lors du rendu d’une image haute résolution en blocs plus petits, ou pour la division et la fusion dynamique sans rupture des vues en écran partagé. Un autre avantage de l’utilisation des coordonnées homogènes est qu’elles rendent le découpage en (contre les plans de découpe proche et lointain) identique au découpage en et en . Cette similitude rend les choses nettes et ordonnées, mais, plus important, sur certains matériels, l’unité vectorielle peut être exploitée pour effectuer des tests de comparaison de découpage en parallèle. En général, l’utilisation des coordonnées homogènes et des matrices rend les choses plus compactes et polyvalentes, et (dans l’esprit de certains) plus élégantes. Mais indépendamment de savoir si l’utilisation de matrices améliore le processus, c’est la façon dont la plupart des API veulent que les choses soient livrées, alors c’est ainsi que ça fonctionne, pour le meilleur ou pour le pire.
La deuxième question qu’un lecteur pourrait avoir est : « Qu’est-il arrivé à ? » Rappelons que est la distance focale, la distance du plan de projection au centre de projection (le « point focal »). Notre discussion de la projection en perspective via la division homogène à la Section 6.5 décrivait comment projeter sur un plan perpendiculaire à l’axe et à unités de l’origine. (Le plan est de la forme .) Mais nous n’avons pas utilisé dans la discussion ci-dessus. Il s’avère que la valeur que nous utilisons pour n’est pas importante, et donc nous choisissons la valeur la plus pratique possible pour , qui est 1.
Pour comprendre pourquoi n’a pas d’importance, comparons la projection qui se produit dans un ordinateur avec la projection qui se produit dans une caméra physique. À l’intérieur d’une vraie caméra, augmenter cette distance fait zoomer la caméra en avant (les objets apparaissent plus grands), et la diminuer fait zoomer en arrière (les objets apparaissent plus petits). C’est montré dans la Figure 10.8.

Figure 10.8 Dans une caméra physique, augmenter la distance focale tout en gardant la taille du « film » identique a pour effet de zoomer en avant.
La ligne verticale à gauche de chaque diagramme représente le film (ou, pour les appareils photo modernes, l’élément de détection), qui se trouve dans le plan de projection infini. Notamment, remarquez que le film a la même hauteur dans chaque diagramme. À mesure que nous augmentons , le film s’éloigne davantage du plan focal, et l’angle du champ de vision intercepté par le tronc de vue diminue. À mesure que le tronc de vue se rétrécit, un objet à l’intérieur de ce tronc occupe une plus grande proportion du volume visible, et apparaît donc plus grand dans l’image projetée. Le résultat perçu est que nous zoomons en avant. Le point clé ici est que changer la longueur focale fait apparaître un objet plus grand parce que l’image projetée est plus grande par rapport à la taille du film.
Voyons maintenant ce qui se passe à l’intérieur d’un ordinateur. Le « film » à l’intérieur d’un ordinateur est la portion rectangulaire du plan de projection qui intersecte le tronc de vue.9 Remarquez que si nous augmentons la distance focale, la taille de l’image projetée augmente, tout comme dans une vraie caméra. Cependant, à l’intérieur d’un ordinateur, le film augmente réellement dans cette même proportion, plutôt que de changer la taille du tronc de vue. Parce que l’image projetée et le film augmentent dans la même proportion, il n’y a pas de changement dans l’image rendue ou la taille apparente des objets dans cette image.
En résumé, le zoom est toujours accompli en changeant la forme du tronc de vue, que nous parlions d’une vraie caméra ou d’un ordinateur. Dans une vraie caméra, changer la longueur focale modifie la forme du tronc de vue parce que le film reste de la même taille. Cependant, dans un ordinateur, ajuster la distance focale n’affecte pas l’image rendue, car le « film » augmente de taille et la forme du tronc de vue ne change pas.
Certains logiciels permettent à l’utilisateur de spécifier le champ de vision en donnant une longueur focale mesurée en millimètres. Ces chiffres sont en référence à une taille de film standard, presque toujours du film 35 mm.
Qu’en est-il de la projection orthographique ? Dans ce cas, nous ne voulons pas diviser par , donc notre matrice de découpe aura une colonne de droite de , identique à la matrice identité. Lorsque multipliée par un vecteur de la forme , cela donnera un vecteur avec , plutôt que . La division homogène se produit toujours, mais cette fois nous divisons par 1 :
La section suivante complète le reste de la matrice de découpe. Mais pour l’instant, le point clé est qu’une matrice de projection en perspective aura toujours une colonne de droite de , et une matrice de projection orthographique aura toujours une colonne de droite de . Ici, le mot « toujours » signifie « nous n’avons jamais rien vu d’autre ». Vous pourriez rencontrer un cas obscur sur un matériel particulier pour lequel d’autres valeurs sont nécessaires, et il est important de comprendre que 1 n’est pas un nombre magique ici, c’est juste le nombre le plus simple. Puisque la conversion homogène est une division, ce qui est important c’est le rapport des coordonnées, pas leur magnitude.
Notez que multiplier toute la matrice par un facteur constant n’a aucun effet sur les valeurs projetées , et , mais cela ajustera la valeur de , qui est utilisée pour la rastérisation avec correction de perspective. Une valeur différente pourrait donc être nécessaire pour une raison quelconque. Cela dit, certains matériels (comme la Wii) supposent que ce sont les deux seuls cas, et aucune autre colonne de droite n’est autorisée.
10.3.4La matrice de découpe : appliquer le zoom et préparer le découpage
Le deuxième objectif de la matrice de découpe est de mettre à l’échelle les composantes , et de sorte que les six plans de découpe aient une forme triviale. Les points sont en dehors du tronc de vue s’ils satisfont au moins l’une des inégalités :
Les six plans du tronc de vue en espace de découpe
Donc les points à l’intérieur du volume de vue satisfont
Toute géométrie qui ne satisfait pas ces égalités doit être découpée (clipped) au tronc de vue. Le découpage est discuté à la Section 10.10.4.
Pour étirer les choses afin de placer les plans de découpe supérieur, gauche, droit et inférieur, nous mettons à l’échelle les valeurs et par les valeurs de zoom de la caméra. Nous avons discuté de la façon de calculer ces valeurs à la Section 10.2.4. Pour les plans de découpe proche et lointain, la coordonnée est décalée et mise à l’échelle de sorte qu’au plan de découpe proche, , et au plan de découpe lointain, .
Soit et les valeurs de zoom horizontal et vertical, et soit et les distances aux plans de découpe proche et lointain. Alors la matrice qui met à l’échelle , et de façon appropriée, tout en copiant simultanément la coordonnée dans , est
Matrice de découpe pour la projection en perspective avec au plan de découpe proche
Cette matrice de découpe suppose un système de coordonnées avec pointant vers l’écran (la convention habituelle à main gauche), des vecteurs-ligne à gauche, et des valeurs dans l’intervalle du plan de découpe proche au lointain. Ce dernier détail est encore un autre endroit où les conventions peuvent varier. D’autres API (notamment DirectX) veulent la matrice de projection telle que soit dans l’intervalle . En d’autres termes, un point en espace de découpe est en dehors du plan de découpe si
Plans de découpe proche et lointain en espace de découpe style DirectX
Sous ces conventions style DirectX, les points à l’intérieur du tronc de vue satisfont l’inégalité . Une matrice de découpe légèrement différente est utilisée dans ce cas :
Matrice de découpe pour la projection en perspective avec au plan de découpe proche
Nous pouvons facilement dire que les deux matrices dans les Équations (10.6) et (10.7) sont des matrices de projection en perspective parce que la colonne de droite est . (D’accord, la légende dans la marge est aussi un indice.)
Qu’en est-il de la projection orthographique ? Les première et deuxième colonnes de la matrice de projection ne changent pas, et nous savons que la quatrième colonne deviendra . La troisième colonne, qui contrôle la valeur de sortie, doit changer. Nous commençons par supposer le premier ensemble de conventions pour , c’est-à-dire que la valeur de sortie sera mise à l’échelle de sorte que prenne les valeurs et aux plans de découpe proche et lointain, respectivement. La matrice qui fait cela est
Matrice de découpe pour la projection orthographique avec au plan de découpe proche
Alternativement, si nous utilisons un intervalle style DirectX pour les valeurs de l’espace de découpe, alors la matrice que nous utilisons est
Matrice de découpe pour la projection orthographique avec au plan de découpe proche
Dans ce livre, nous préférons une convention à main gauche et des vecteurs-ligne à gauche, et toutes les matrices de projection jusqu’à présent supposent ces conventions. Cependant, ces deux choix diffèrent de la convention OpenGL, et nous savons que de nombreux lecteurs pourraient travailler dans des environnements similaires à OpenGL. Comme cela peut être très déroutant, répétons ces matrices, mais avec les conventions OpenGL à main droite et vecteurs-colonne. Nous ne discuterons que de l’intervalle pour les valeurs de l’espace de découpe, car c’est ce qu’OpenGL utilise.
Il est instructif de considérer comment convertir ces matrices d’un ensemble de conventions à l’autre. Parce qu’OpenGL utilise des vecteurs-colonne, la première chose que nous devons faire est de transposer notre matrice. Deuxièmement, les conventions à main droite ont pointant vers l’écran dans l’espace caméra (« espace œil » dans le vocabulaire OpenGL), mais l’axe de l’espace de découpe pointe vers l’écran comme dans les conventions à main gauche supposées précédemment. (Dans OpenGL, l’espace de découpe est en fait un espace de coordonnées à main gauche !) Cela signifie que nous devons nier nos valeurs entrantes, ou alternativement, nier la troisième colonne (après avoir transposé la matrice), qui est la colonne multipliée par .
La procédure ci-dessus donne la matrice de projection en perspective suivante
Matrice de découpe pour la projection en perspective avec les conventions OpenGL
et la matrice de projection orthographique est
Matrice de découpe pour la projection orthographique avec les conventions OpenGL
Ainsi, pour les conventions OpenGL, on peut distinguer si une matrice de projection est en perspective ou orthographique d’après la rangée inférieure. Elle sera pour la perspective, et pour l’orthographique.
Maintenant que nous en savons un peu plus sur l’espace de découpe, nous pouvons comprendre la nécessité du plan de découpe proche. Évidemment, il y a une singularité précisément à l’origine, où une projection en perspective n’est pas définie. (Cela correspond à une division de perspective par zéro.) En pratique, cette singularité serait extrêmement rare, et quelle que soit la façon dont nous voulions la gérer — disons, en projetant arbitrairement le point au centre de l’écran — ce serait acceptable, car placer la caméra directement dans un polygone n’est pas souvent nécessaire en pratique.
Mais projeter des polygones sur des pixels n’est pas le seul problème. Permettre des valeurs arbitrairement petites (mais positives) de entraînera des valeurs arbitrairement grandes pour . Selon le matériel, cela peut causer des problèmes avec la rastérisation avec correction de perspective. Un autre problème potentiel est la mise en tampon de profondeur. Il suffit de dire que pour des raisons pratiques, il est souvent nécessaire de restreindre la plage des valeurs de sorte qu’il y ait une valeur minimale connue, et nous devons accepter la nécessité plutôt déplaisante d’un plan de découpe proche. Nous disons « déplaisant » car le plan de découpe proche est un artefact d’implémentation, pas une partie inhérente d’un monde 3D. (Les lanceurs de rayons n’ont pas nécessairement ce problème.) Il coupe les objets quand on s’en approche trop, alors qu’en réalité on devrait pouvoir s’en approcher indéfiniment. De nombreux lecteurs sont probablement familiers avec le phénomène où une caméra est placée au milieu d’un grand polygone de sol, juste un peu au-dessus de celui-ci, et un espace s’ouvre en bas de l’écran, permettant à la caméra de voir à travers le sol. Une situation similaire existe si vous vous approchez très près de pratiquement n’importe quel objet autre qu’un mur. Un trou apparaîtra au milieu de l’objet, et ce trou s’élargira à mesure que vous vous rapprocherez.
10.3.5L’espace écran
Une fois que nous avons découpé la géométrie au tronc de vue, elle est projetée dans l’espace écran, qui correspond aux pixels réels dans le tampon de trame. Rappelons que nous rendons dans une fenêtre de sortie qui n’occupe pas nécessairement tout le dispositif d’affichage. Cependant, nous voulons généralement que nos coordonnées d’espace écran soient spécifiées en utilisant des coordonnées absolues par rapport au dispositif de rendu (Figure 10.9).
Figure 10.9La fenêtre de sortie en espace écran
L’espace écran est bien sûr un espace 2D. Ainsi, nous devons projeter les points de l’espace de découpe vers l’espace écran pour générer les coordonnées 2D correctes. La première chose qui se produit est la division homogène standard par . (OpenGL appelle le résultat de cette division les coordonnées de dispositif normalisées.) Ensuite, les coordonnées et doivent être mises à l’échelle pour correspondre à la fenêtre de sortie. Ceci est résumé par
Projection et mapping vers l’espace écran
Un bref commentaire est justifié concernant la négation de la composante dans les mathématiques ci-dessus. Cela reflète les conventions de coordonnées style DirectX où (0,0) est dans le coin supérieur gauche. Sous ces conventions, pointe vers le haut en espace de découpe, mais vers le bas en espace écran. En fait, si nous continuons à penser que pointe vers l’écran, alors l’espace écran devient effectivement un espace de coordonnées à main droite, même si c’est à main gauche partout ailleurs dans DirectX. Dans OpenGL, l’origine est dans le coin inférieur gauche, et la négation de la coordonnée ne se produit pas. (Comme déjà discuté, dans OpenGL, ils choisissent un endroit différent pour introduire la confusion, en inversant l’axe entre l’espace œil, où pointe vers l’écran, et l’espace de découpe, où pointe vers l’écran.)
En parlant de , qu’arrive-t-il à ? En général, il est utilisé d’une certaine façon pour la mise en tampon de profondeur. Une méthode traditionnelle consiste à prendre la valeur de profondeur normalisée et à stocker cette valeur dans le tampon de profondeur. Les détails précis dépendent exactement de quels types de valeurs de découpe sont utilisés pour le découpage, et quels types de valeurs de profondeur entrent dans le tampon de profondeur. Par exemple, dans OpenGL, la convention conceptuelle est que le tronc de vue contient , mais cela peut ne pas être optimal pour la mise en tampon de profondeur. Les fournisseurs de pilotes doivent convertir des conventions conceptuelles de l’API vers ce qui est optimal pour le matériel.
Une stratégie alternative, connue sous le nom de tampon en w (-buffering), consiste à utiliser comme valeur de profondeur. Dans la plupart des situations, est simplement une version mise à l’échelle de la valeur de l’espace caméra ; ainsi, en utilisant dans le tampon de profondeur, chaque valeur a une relation linéaire avec la profondeur de visualisation du pixel correspondant. Cette méthode peut être attractive, surtout si le tampon de profondeur est en virgule fixe avec une précision limitée, car elle répartit la précision disponible de façon plus uniforme. La méthode traditionnelle de stockage de dans le tampon de profondeur entraîne une précision considérablement accrue de près, mais au détriment d’une précision (parfois drastiquement) réduite près du plan de découpe lointain. Si les valeurs du tampon de profondeur sont stockées en virgule flottante, ce problème est beaucoup moins important. Notez également que le tampon en ne fonctionne pas pour la projection orthographique, car une matrice de projection orthographique donne toujours .
La valeur n’est pas non plus abandonnée. Comme nous l’avons dit, elle sert le but important de dénominateur dans la division homogène vers les coordonnées de dispositif normalisées. Mais cette valeur est aussi généralement nécessaire pour l’interpolation correcte avec perspective des coordonnées de texture, des couleurs, et d’autres valeurs au niveau des sommets pendant la rastérisation.
Sur les API graphiques modernes au moment de la rédaction de ce texte, la conversion des coordonnées de vertex de l’espace de découpe à l’espace écran est faite automatiquement. Votre vertex shader génère des coordonnées en espace de découpe. L’API découpe les triangles au tronc de vue puis projette les coordonnées vers l’espace écran. Mais cela ne signifie pas que vous n’utiliserez jamais les équations de cette section dans votre code. Assez souvent, nous devons effectuer ces calculs en logiciel pour les tests de visibilité, la sélection du niveau de détail, etc.
10.3.6Résumé des espaces de coordonnées
La Figure 10.10 résume les espaces de coordonnées et les matrices discutés dans cette section, montrant le flux de données de l’espace objet à l’espace écran.
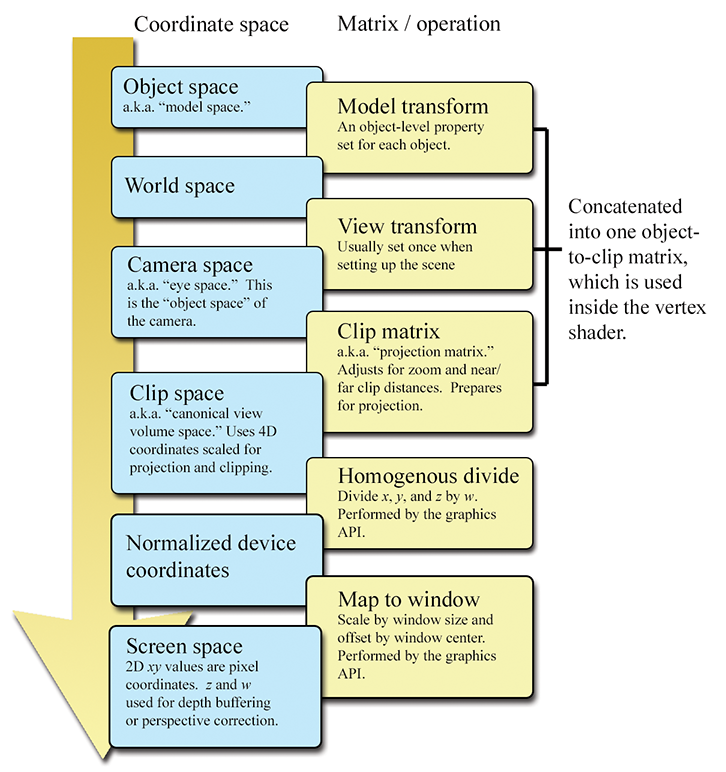
Figure 10.10Conversion des coordonnées de sommets à travers le pipeline graphique
Les espaces de coordonnées que nous avons mentionnés sont les plus importants et les plus courants, mais d’autres espaces de coordonnées sont utilisés en infographie. Par exemple, une lumière projetée pourrait avoir son propre espace, qui est essentiellement le même que l’espace caméra, sauf qu’il est du point de vue de ce que la lumière « voit » dans la scène. Cet espace est important lorsque la lumière projette une image (parfois appelée un gobo) et aussi pour la carte d’ombres pour déterminer si une lumière peut « voir » un point donné.
Un autre espace devenu très important est l’espace tangent, qui est un espace local sur la surface d’un objet. Un vecteur de base est la normale de surface et les deux autres vecteurs de base sont localement tangents à la surface, établissant essentiellement un espace de coordonnées 2D qui est « plat » sur la surface à cet endroit. Il existe de nombreuses façons différentes de déterminer ces vecteurs de base, mais de loin la raison la plus courante d’établir un tel espace de coordonnées est pour le bump mapping et les techniques associées. Une discussion plus complète de l’espace tangent devra attendre que nous discutions du texture mapping à la Section 10.5, donc nous reviendrons sur ce sujet à la Section 10.9.1. L’espace tangent est aussi parfois appelé espace local à la surface.
10.4Maillages polygonaux
Pour rendre une scène, nous avons besoin d’une description mathématique de la géométrie dans cette scène. Plusieurs méthodes différentes sont disponibles. Cette section se concentre sur celle qui est la plus importante pour le rendu en temps réel : le maillage de triangles (triangle mesh). Mais d’abord, mentionnons quelques alternatives pour avoir un certain contexte. La géométrie solide constructive (CSG) est un système pour décrire la forme d’un objet en utilisant des opérateurs booléens (union, intersection, soustraction) sur des primitives. Dans les jeux vidéo, la CSG peut être particulièrement utile pour les outils de prototypage rapide, le moteur Unreal étant un exemple notable. Une autre technique qui fonctionne en modélisant des volumes plutôt que leurs surfaces est celle des metaballs, parfois utilisée pour modéliser des formes organiques et des fluides, comme discuté à la Section 9.1. La CSG, les metaballs et d’autres descriptions volumétriques sont très utiles dans des domaines particuliers, mais pour le rendu (surtout le rendu en temps réel), nous nous intéressons à une description de la surface de l’objet, et nous avons rarement besoin de déterminer si un point donné est à l’intérieur ou à l’extérieur de cette surface. En effet, la surface n’a pas besoin d’être fermée ni même de définir un volume cohérent.
La description de surface la plus courante est le maillage polygonal (polygon mesh), dont vous êtes probablement déjà conscient. Dans certaines circonstances, il est utile de permettre aux polygones qui forment la surface de l’objet d’avoir un nombre arbitraire de sommets ; c’est souvent le cas dans les outils d’importation et d’édition. Pour le rendu en temps réel, cependant, le matériel moderne est optimisé pour les maillages de triangles (triangle meshes), qui sont des maillages polygonaux dans lesquels chaque polygone est un triangle. Tout maillage polygonal donné peut être converti en un maillage de triangles équivalent en décomposant chaque polygone en triangles individuellement, comme discuté brièvement à la Section 9.7.3. Veuillez noter que de nombreux concepts importants introduits dans le contexte d’un seul triangle ou polygone ont été couverts aux Section 9.6 et Section 9.7, respectivement. Ici, notre focus est sur la façon dont plusieurs triangles peuvent être connectés dans un maillage.
Une façon très simple de stocker un maillage de triangles serait d’utiliser un tableau de triangles, comme le montre le Listing 10.4.
struct Triangle {
Vector3 vertPos[3]; // positions des sommets
};
struct TriangleMesh {
int triCount; // nombre de triangles
Triangle *triList; // tableau de triangles
};Pour certaines applications, cette représentation triviale pourrait être adéquate. Cependant, le terme « maillage » implique un degré de connectivité entre les triangles adjacents, et cette connectivité n’est pas exprimée dans notre représentation triviale. Il y a trois types d’informations de base dans un maillage de triangles :
Sommets. Chaque triangle a exactement trois sommets. Chaque sommet peut être partagé par plusieurs triangles. La valence d’un sommet désigne le nombre de faces connectées au sommet.
Arêtes. Une arête relie deux sommets. Chaque triangle a trois arêtes. Dans de nombreux cas, chaque arête est partagée par exactement deux faces, mais il y a certainement des exceptions. Si l’objet n’est pas fermé, une arête ouverte avec seulement une face voisine peut exister.
Faces. Ce sont les surfaces des triangles. Nous pouvons stocker une face soit comme une liste de trois sommets, soit comme une liste de trois arêtes.
Diverses méthodes existent pour représenter ces informations efficacement, selon les opérations à effectuer le plus souvent sur le maillage. Nous nous concentrerons ici sur un format de stockage standard connu sous le nom de maillage de triangles indexé.
10.4.1Maillage de triangles indexé
Un maillage de triangles indexé se compose de deux listes : une liste de sommets et une liste de triangles.
Chaque sommet contient une position en 3D. Nous pouvons également stocker d’autres informations au niveau du sommet, comme les coordonnées de texture, les normales de surface, ou les valeurs d’éclairage.
Un triangle est représenté par trois entiers qui indexent dans la liste de sommets. Habituellement, l’ordre dans lequel ces sommets sont listés est significatif, car nous pouvons considérer que les faces ont des côtés « avant » et « arrière ». Nous adoptons la convention à main gauche selon laquelle les sommets sont listés dans le sens horaire lorsqu’on les voit depuis le côté avant. D’autres informations peuvent également être stockées au niveau du triangle, comme une normale précalculée du plan contenant le triangle, des propriétés de surface (comme une carte de texture), etc.
Le Listing 10.5 montre un exemple très simplifié de la façon dont un maillage de triangles indexé pourrait être stocké en C.
// struct Vertex stocke les informations au niveau des sommets
struct Vertex {
// Position 3D du sommet
Vector3 pos;
// D'autres informations pourraient inclure
// les coordonnées de texture, une
// normale de surface, des valeurs d'éclairage, etc.
};
// struct Triangle stocke les informations au niveau des triangles
struct Triangle {
// Indices dans la liste de sommets. En pratique, on utilise presque
// toujours des indices 16 bits plutôt que 32 bits, pour économiser
// la mémoire et la bande passante.
int vertexIndex[3];
// D'autres informations pourraient inclure
// une normale, des informations de matériau, etc.
};
// struct TriangleMesh stocke un maillage de triangles indexé
struct TriangleMesh {
// Les sommets
int vertexCount;
Vertex *vertexList;
// Les triangles
int triangleCount;
Triangle *triangleList;
};La Figure 10.11 montre comment un cube et une pyramide pourraient être représentés comme un maillage polygonal ou un maillage de triangles. Notez que les deux objets font partie d’un seul maillage avec 13 sommets. Les fils plus clairs et plus épais montrent les contours des polygones, et les fils plus fins et vert foncé montrent une façon d’ajouter des arêtes pour trianguler le maillage polygonal.
Figure 10.11Un maillage simple contenant un cube et une pyramide
En supposant que l’origine est sur le « sol » directement entre les deux objets, les coordonnées de sommets pourraient être comme indiqué dans la Table 10.3.
| 0 | 4 | 8 | 12 | ||||
| 1 | 5 | 9 | |||||
| 2 | 6 | 10 | |||||
| 3 | 7 | 11 |
Table 10.3Positions des sommets dans notre maillage exemple
La Table 10.4 montre les indices de sommets qui formeraient les faces de ce maillage, soit comme maillage polygonal soit comme maillage de triangles. Rappelons que l’ordre des sommets est significatif ; ils sont listés dans le sens horaire lorsqu’on les voit depuis l’extérieur. Vous devriez étudier ces figures jusqu’à ce que vous soyez sûr de les comprendre.
| Indices de sommets | Indices de sommets | |
| Description | (Maillage polygonal) | (Maillage de triangles) |
| Dessus du cube | , | |
| Face avant du cube | , | |
| Face droite du cube | , | |
| Face gauche du cube | , | |
| Face arrière du cube | , | |
| Dessous du cube | , | |
| Face avant de la pyramide | ||
| Face gauche de la pyramide | ||
| Face droite de la pyramide | ||
| Face arrière de la pyramide | ||
| Base de la pyramide | , |
Table 10.4 Les indices de sommets qui forment les faces de notre maillage exemple, soit comme maillage polygonal soit comme maillage de triangles
Les sommets doivent être listés dans le sens horaire autour d’une face, mais peu importe lequel est considéré comme le « premier » sommet ; ils peuvent être cyclés sans changer la structure logique du maillage. Par exemple, le quadrilatère formant le dessus du cube aurait pu être donné également comme , , ou .
Comme indiqué par les commentaires dans le Listing 10.5, des données supplémentaires sont presque toujours stockées par sommet, comme les coordonnées de texture, les normales de surface, les vecteurs de base, les couleurs, les données de skinning, etc. Chacune est discutée dans des sections ultérieures dans le contexte des techniques qui utilisent ces données. Des données supplémentaires peuvent également être stockées au niveau des triangles, comme un indice qui indique quel matériau utiliser pour cette face, ou l’équation du plan (dont une partie est la normale de surface — voir la Section 9.5) pour la face. C’est très utile à des fins d’édition ou dans d’autres outils qui effectuent des manipulations de maillage en logiciel. Pour le rendu en temps réel, cependant, nous ne stockons rarement des données au niveau du triangle au-delà des trois indices de sommets. En fait, la méthode la plus courante est de ne pas avoir de struct Triangle du tout, et de représenter toute la liste des triangles simplement comme un tableau (par ex. unsigned short triList[] ), où la longueur du tableau est le nombre de triangles multiplié par 3. Les triangles avec des propriétés identiques sont regroupés en lots de sorte qu’un lot entier peut être envoyé au GPU dans ce format optimal. Après avoir passé en revue de nombreux concepts qui donnent naissance au besoin de stocker des données supplémentaires par sommet, la Section 10.10.2 examine plusieurs exemples plus spécifiques de la façon dont nous pourrions transmettre ces données à l’API graphique. Au fait, en règle générale, les choses sont beaucoup plus faciles si vous n’essayez pas d’utiliser la même classe de maillage pour le rendu et l’édition. Les exigences sont très différentes, et une structure de données plus volumineuse avec plus de flexibilité est préférable pour les outils, les importateurs, etc.
Notez que dans un maillage de triangles indexé, les arêtes ne sont pas stockées explicitement, mais plutôt les informations d’adjacence contenues dans une liste de triangles indexés sont stockées implicitement : pour localiser les arêtes partagées entre les triangles, nous devons rechercher dans la liste de triangles. Notre format trivial original d’« array de triangles » dans le Listing 10.4 n’avait aucune information logique de connectivité (bien que nous aurions pu tenter de détecter si les sommets sur une arête étaient identiques en comparant les positions des sommets ou d’autres propriétés). Ce qui est surprenant, c’est que les informations de connectivité « supplémentaires » contenues dans la représentation indexée entraînent en réalité une réduction de l’utilisation de la mémoire dans la plupart des cas, par rapport à la méthode plate. La raison en est que les informations stockées au niveau du sommet, qui sont dupliquées dans le format plat trivial, sont relativement importantes par rapport à un seul indice entier. (Au minimum, nous devons stocker une position de vecteur 3D.) Dans les maillages qui se présentent en pratique, un sommet typique a une valence d’environ 3 à 6, ce qui signifie que le format plat duplique pas mal de données.
Le schéma simple de maillage de triangles indexé est approprié pour de nombreuses applications, y compris celui très important du rendu. Cependant, certaines opérations sur les maillages de triangles nécessitent une structure de données plus avancée pour être mises en œuvre plus efficacement. Le problème de base est que l’adjacence entre les triangles n’est pas exprimée explicitement et doit être extraite en cherchant dans la liste de triangles. D’autres techniques de représentation existent qui rendent cette information disponible en temps constant. Une idée est de maintenir une liste d’arêtes explicitement. Chaque arête est définie en listant les deux sommets à ses extrémités. Nous maintenons également une liste des triangles qui partagent l’arête. Ensuite, les triangles peuvent être vus comme une liste de trois arêtes plutôt qu’une liste de trois sommets, ils sont donc stockés comme trois indices dans la liste d’arêtes plutôt que dans la liste de sommets. Une extension de cette idée est connue sous le nom de modèle winged-edge [7], qui stocke également, pour chaque sommet, une référence à une arête qui utilise le sommet. Les arêtes et les triangles peuvent être parcourus intelligemment pour localiser rapidement toutes les arêtes et les triangles qui utilisent le sommet.
10.4.2Normales de surface
Les normales de surface sont utilisées à plusieurs fins différentes en infographie ; par exemple, pour calculer un éclairage correct (Section 10.6), et pour l’élimination des faces arrière (backface culling) (Section 10.10.5). En général, une normale de surface est un vecteur unitaire10 perpendiculaire à une surface. Nous pourrions nous intéresser à la normale d’une face donnée, auquel cas la surface d’intérêt est le plan qui contient la face. Les normales de surface pour les polygones peuvent être calculées facilement en utilisant les techniques de la Section 9.5.
Les normales au niveau des sommets sont un peu plus délicates. Premièrement, il convient de noter que, strictement parlant, il n’y a pas de vraie normale de surface en un sommet (ni en une arête d’ailleurs), car ces emplacements marquent des discontinuités dans la surface du maillage polygonal. Plutôt que cela, pour les besoins du rendu, nous interprétons généralement un maillage polygonal comme une approximation d’une surface lisse. Donc nous ne voulons pas une normale à la surface linéaire par morceaux définie par le maillage polygonal ; nous voulons plutôt (une approximation de) la normale de surface de la surface lisse.
Le but principal des normales de sommet est l’éclairage. Pratiquement tout modèle d’éclairage prend une normale de surface en l’endroit éclairé comme entrée. En fait, la normale de surface fait partie de l’équation de rendu elle-même (dans le facteur de Lambert), donc c’est toujours une entrée, même si la BRDF n’en dépend pas. Nous n’avons des normales disponibles qu’aux sommets, mais nous devons calculer les valeurs d’éclairage sur toute la surface. Que faire ? Si les ressources matérielles le permettent (comme c’est généralement le cas de nos jours), alors nous pouvons approximer la normale de la surface continue correspondant à n’importe quel point d’une face donnée en interpolant les normales de sommet et en renormalisant le résultat. Cette technique est illustrée dans la Figure 10.12, qui montre une section transversale d’un cylindre (cercle noir) qui est approximé par un prisme hexagonal (contour bleu). Les normales noires aux sommets sont les vraies normales de surface, tandis que les normales intérieures sont approximées par interpolation. (Les normales réellement utilisées seraient le résultat de l’étirement de celles-ci à longueur unitaire.)
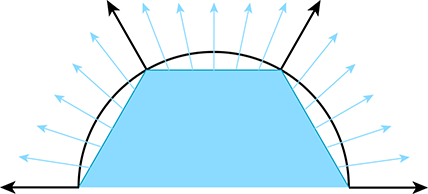
Figure 10.12 Un cylindre approximé avec un prisme hexagonal.
Une fois que nous avons une normale en un point donné, nous pouvons effectuer l’équation d’éclairage complète par pixel. C’est ce qu’on appelle l’ombrage par pixel.11 Une stratégie alternative à l’ombrage par pixel, connue sous le nom d’ombrage de Gouraud12 [9], consiste à effectuer les calculs d’éclairage uniquement au niveau des sommets, puis à interpoler les résultats eux-mêmes, plutôt que la normale, sur la face. Cela nécessite moins de calcul, et est encore fait sur certains systèmes, comme la Nintendo Wii.

Figure 10.13 Approximation de cylindres avec des prismes d’un nombre de côtés variable.
La Figure 10.13 montre l’éclairage par pixel de cylindres avec un nombre de côtés différent. Bien que l’illusion se rompe aux extrémités du cylindre, où l’arête de silhouette révèle la nature low-poly de la géométrie, cette méthode d’approximation d’une surface lisse peut effectivement faire paraître « lisse » même un maillage très basse résolution. Couvrez les extrémités du cylindre, et même le cylindre à 5 côtés est remarquablement convaincant.
Maintenant que nous comprenons comment les normales sont interpolées pour reconstruire approximativement une surface courbée, parlons de la façon d’obtenir les normales de sommet. Ces informations peuvent ne pas être facilement disponibles, selon la façon dont le maillage de triangles a été généré. Si le maillage est généré de façon procédurale, par exemple à partir d’une surface courbe paramétrique, alors les normales de sommet peuvent être fournies à ce moment-là. Ou vous pourriez simplement recevoir les normales de sommet du package de modélisation dans le cadre du maillage. Cependant, parfois les normales de surface ne sont pas fournies, et nous devons les approximer en interprétant les seules informations disponibles : les positions des sommets et les triangles. Une astuce qui fonctionne est de calculer la moyenne des normales des triangles adjacents, puis de renormaliser le résultat. Cette technique classique est démontrée dans le Listing 10.6.
struct Vertex {
Vector3 pos;
Vector3 normal;
};
struct Triangle {
int vertexIndex[3];
Vector3 normal;
};
struct TriangleMesh {
int vertexCount;
Vertex *vertexList;
int triangleCount;
Triangle *triangleList;
void computeVertexNormals() {
// D'abord, effacer les normales de sommet
for (int i = 0 ; i < vertexCount ; ++i) {
vertexList[i].normal.zero();
}
// Maintenant, ajouter les normales de face dans les
// normales des sommets adjacents
for (int i = 0 ; i < triangleCount ; ++i) {
// Obtenir un raccourci
Triangle &tri = triangleList[i];
// Calculer la normale du triangle.
Vector3 v0 = vertexList[tri.vertexIndex[0]].pos;
Vector3 v1 = vertexList[tri.vertexIndex[1]].pos;
Vector3 v2 = vertexList[tri.vertexIndex[2]].pos;
tri.normal = cross(v1-v0, v2-v1);
tri.normal.normalize();
// La sommer dans les sommets adjacents
for (int j = 0 ; j < 3 ; ++j) {
vertexList[tri.vertexIndex[j]].normal += tri.normal;
}
}
// Enfin, calculer la moyenne et normaliser les résultats.
// Notez que cela peut planter si un sommet est isolé
// (non utilisé par aucun triangle), et dans d'autres cas.
for (int i = 0 ; i < vertexCount ; ++i) {
vertexList[i].normal.normalize();
}
}
};La moyenne des normales de face pour calculer les normales de sommet est une technique éprouvée qui fonctionne bien dans la plupart des cas. Cependant, il y a quelques points à surveiller. Le premier est que parfois le maillage est censé avoir une discontinuité, et si nous ne faisons pas attention, cette discontinuité sera « lissée ». Prenons l’exemple très simple d’une boîte. Il devrait y avoir une discontinuité nette d’éclairage à ses arêtes. Cependant, si nous utilisons des normales de sommet calculées à partir de la moyenne des normales de surface, il n’y a pas de discontinuité d’éclairage, comme le montre la Figure 10.14.

Figure 10.14 Sur la droite, les arêtes de la boîte ne sont pas visibles car il n’y a qu’une seule normale à chaque coin
Sommets
#
Position
Normale
0
1
2
3
4
5
6
7
Faces
Description
Indices
Dessus
Avant
Droite
Gauche
Arrière
Dessous
Table 10.5Maillage polygonal d’une boîte avec sommets soudés et arêtes lissées
Le problème de base est que la discontinuité de surface aux arêtes de la boîte ne peut pas être correctement représentée car il n’y a qu’une seule normale stockée par sommet. La solution à ce problème est de « détacher » les faces ; en d’autres termes, dupliquer les sommets le long de l’arête où il y a une vraie discontinuité géométrique, créant une discontinuité topologique pour empêcher les normales de sommet d’être moyennées. Après cela, les faces ne sont plus logiquement connectées, mais cette couture dans la topologie du maillage ne pose pas de problème pour de nombreuses tâches importantes, comme le rendu et le lancer de rayons. La Table 10.5 montre un maillage de boîte lissé avec huit sommets. Comparez ce maillage avec celui de la Table 10.6, dans lequel les faces ont été détachées, résultant en 24 sommets.
Sommets
#
Position
Normale
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Faces
Description
Indices
Dessus
Avant
Droite
Gauche
Arrière
Dessous
Table 10.6Maillage polygonal d’une boîte avec faces détachées et discontinuités d’éclairage aux arêtes
Une version extrême de cette situation se produit lorsque deux faces sont placées dos à dos. Une telle géométrie infiniment mince double-face peut apparaître avec le feuillage, le tissu, les panneaux d’affichage (billboards) et autres. Dans ce cas, puisque les normales sont exactement opposées, leur moyenne donne le vecteur nul, qui ne peut pas être normalisé. La solution la plus simple est de détacher les faces de sorte que les normales de sommet ne soient pas moyennées ensemble. Ou si le devant et le derrière sont des images miroir, les deux polygones « unilatéraux » peuvent être remplacés par un seul « bilatéral ». Cela nécessite un traitement spécial lors du rendu pour désactiver l’élimination des faces arrière (backface culling) (Section 10.10.5) et traiter intelligemment la normale dans l’équation d’éclairage.
Un problème plus subtil est que la moyenne est biaisée vers un grand nombre de triangles avec la même normale. Par exemple, considérons le sommet à l’indice 1 dans la Figure 10.11. Ce sommet est adjacent à deux triangles sur le dessus du cube, mais seulement un triangle sur le côté droit et un triangle sur le côté arrière. La normale de sommet calculée en faisant la moyenne des normales de triangle est biaisée parce que la normale de la face supérieure obtient essentiellement deux fois plus de « votes » que chacune des normales de face latérale. Mais cette topologie est le résultat d’une décision arbitraire concernant la façon de tracer les arêtes pour trianguler les faces du cube. Par exemple, si nous triangulions la face supérieure en traçant une arête entre les sommets 0 et 2 (ceci est connu sous le nom de « retournement » de l’arête), toutes les normales de la face supérieure changeraient.
Des techniques existent pour traiter ce problème, comme pondérer la contribution de chaque face adjacente selon l’angle intérieur adjacent au sommet, mais c’est souvent ignoré en pratique. La plupart des exemples vraiment terribles sont des cas artificieux comme celui-ci, où les faces devraient de toute façon être détachées. De plus, les normales sont une approximation dès le départ, et avoir une normale légèrement perturbée est souvent difficile à distinguer visuellement.
Bien que certains packages de modélisation puissent fournir des normales de sommet pour vous, moins nombreux fournissent les vecteurs de base nécessaires pour le bump mapping. Comme nous le voyons à la Section 10.9, les techniques utilisées pour synthétiser les vecteurs de base de sommet sont similaires à celles décrites ici.
Avant de continuer, il y a un fait très important sur les normales de surface que nous devons mentionner. Dans certaines circonstances, elles ne peuvent pas être transformées par la même matrice que celle utilisée pour transformer les positions. (Il s’agit d’une question entièrement distincte du fait que les normales ne doivent pas être translatées comme les positions.) La raison en est que les normales sont des vecteurs covariants. Les vecteurs « ordinaires », tels que la position et la vitesse, sont dits contravariants : si nous mettons à l’échelle l’espace de coordonnées utilisé pour décrire le vecteur, les coordonnées réagiront dans la direction opposée. Si nous utilisons un espace de coordonnées avec une plus grande échelle (par exemple, en utilisant des mètres au lieu des pieds), les coordonnées d’un vecteur contravariant réagissent de façon contraire, en devenant plus petites. Notez que tout cela concerne l’échelle ; la translation et la rotation ne font pas partie de la discussion. Les normales et autres types de gradients, connus sous le nom de vecteurs duaux, ne se comportent pas ainsi.
Imaginez que nous étirions un objet 2D, comme un cercle, horizontalement, comme le montre la Figure 10.15. Remarquez que les normales (montrées en bleu clair dans la figure de droite) commencent à tourner pour pointer davantage verticalement — les coordonnées horizontales des normales diminuent en valeur absolue tandis que les coordonnées horizontales des positions augmentent. Un étirement de l’objet (l’objet devient plus grand tandis que l’espace de coordonnées reste le même) a le même effet que réduire l’espace de coordonnées tout en maintenant l’objet à la même taille. Les coordonnées de la normale changent dans la même direction que l’échelle de l’espace de coordonnées, c’est pourquoi elles sont appelées vecteurs covariants.
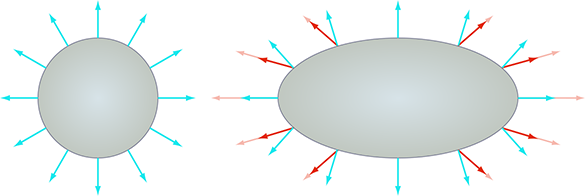
Figure 10.15 Transformation des normales avec une échelle non uniforme. Les vecteurs rouge clair montrent les normales multipliées par la même matrice de transformation utilisée pour transformer l’objet ; les vecteurs rouge foncé sont leurs versions normalisées. Les vecteurs bleu clair montrent les normales correctes.
Pour transformer correctement les normales de surface, nous devons utiliser la transposée inverse de la matrice utilisée pour transformer les positions ; c’est-à-dire le résultat de la transposition et de l’inversion de la matrice. Cela est parfois noté , car peu importe si nous transposons d’abord ou inversons d’abord : . Si la matrice de transformation ne contient pas d’échelle (ni de cisaillement), alors la matrice est orthonormale, et donc la transposée inverse est simplement la même que la matrice originale, et nous pouvons transformer les normales en toute sécurité avec cette transformation. Si la matrice contient une échelle uniforme, alors nous pouvons encore ignorer cela, mais nous devons renormaliser les normales après les avoir transformées. Si la matrice contient une échelle non uniforme (ou un cisaillement, qui est indiscernable d’une échelle non uniforme combinée avec une rotation), alors pour transformer correctement les normales, nous devons utiliser la matrice de transformation transposée inverse, puis renormaliser les normales transformées résultantes.
En général, les normales doivent être transformées avec la transposée inverse de la matrice utilisée pour transformer les positions. Cela peut être ignoré en toute sécurité si la matrice de transformation est sans échelle. Si la matrice contient une échelle uniforme, il suffit de renormaliser les normales après transformation. Si la matrice contient une échelle non uniforme, nous devons utiliser la transformation transposée inverse et renormaliser après transformation.
10.5Texture mapping
Il y a bien plus que la forme dans l’apparence d’un objet. Différents objets ont différentes couleurs et différents motifs sur leur surface. Une façon simple mais puissante de capturer ces qualités est le texture mapping. Une carte de texture est une image bitmap « collée » sur la surface d’un objet. Plutôt que de contrôler la couleur d’un objet par triangle ou par sommet, avec le texture mapping nous pouvons contrôler la couleur à un niveau beaucoup plus fin — par texel. (Un texel est un seul pixel dans une carte de texture. C’est un mot pratique à connaître, car dans les contextes infographiques, il y a beaucoup de bitmaps différents auxquels on accède, et il est agréable d’avoir un moyen court de différencier un pixel dans le tampon de trame d’un pixel dans une texture.)
Donc une carte de texture est juste un bitmap normal appliqué sur la surface d’un modèle. Comment cela fonctionne-t-il exactement ? En fait, il existe de nombreuses façons différentes d’appliquer une carte de texture sur un maillage. Le mapping planaire projette la texture orthographiquement sur le maillage. Les mappings sphérique, cylindrique et cubique sont diverses méthodes d’« enrouler » la texture autour de l’objet. Les détails de chacune de ces techniques ne nous importent pas pour l’instant, car des packages de modélisation tels que 3DS Max traitent de ces questions d’interface utilisateur. L’idée clé est qu’à chaque point sur la surface du maillage, nous pouvons obtenir des coordonnées de texture (texture-mapping coordinates), qui définissent la position 2D dans la carte de texture correspondant à cette position 3D. Traditionnellement, ces coordonnées se voient attribuer les variables , où est la coordonnée horizontale et est la coordonnée verticale ; ainsi, les coordonnées de texture sont souvent appelées coordonnées UV ou simplement UVs.
Bien que les bitmaps existent en différentes tailles, les coordonnées UV sont normalisées de sorte que l’espace de mapping varie de 0 à 1 sur toute la largeur ( ) ou hauteur ( ) de l’image, plutôt que de dépendre des dimensions de l’image. L’origine de cet espace se trouve soit dans le coin supérieur gauche de l’image, qui est la convention style DirectX, soit dans le coin inférieur gauche, les conventions OpenGL. Nous utilisons les conventions DirectX dans ce livre. La Figure 10.16 montre la carte de texture que nous utilisons dans plusieurs exemples et les conventions de coordonnées style DirectX.

Figure 10.16 Un exemple de carte de texture, avec des coordonnées UV étiquetées selon la convention DirectX, qui place l’origine dans le coin supérieur gauche.
En principe, peu importe comment nous déterminons les coordonnées UV pour un point donné sur la surface. Cependant, même lorsque les coordonnées UV sont calculées dynamiquement, plutôt qu’éditées par un artiste, nous calculons ou attribuons généralement des coordonnées UV uniquement au niveau du sommet, et les coordonnées UV à une position intérieure arbitraire sur une face sont obtenues par interpolation. Si vous imaginez la carte de texture comme un tissu élastique, alors lorsque nous attribuons des coordonnées de texture à un sommet, c’est comme enfoncer une épingle dans le tissu à ces coordonnées UV, puis épingler le tissu sur la surface à ce sommet. Il y a une épingle par sommet, de sorte que toute la surface est couverte.
Regardons quelques exemples. La Figure 10.17 montre un quad à texture unique, avec différentes valeurs UV attribuées aux sommets. Le bas de chaque diagramme montre l’espace UV de la texture. Vous devriez étudier ces exemples jusqu’à ce que vous soyez sûr de les comprendre.
 |
 |
 |
 |
 |
 |
Figure 10.17Un quad avec texture, avec différentes coordonnées UV attribuées aux sommets
Les coordonnées UV en dehors de l’intervalle sont autorisées et sont même très utiles. Ces coordonnées sont interprétées de plusieurs façons. Les modes d’adressage les plus courants sont répétition (repeat, aussi connu sous le nom de tile ou wrap) et serrage (clamp). Avec la répétition, la partie entière est ignorée et seule la partie fractionnaire est utilisée, provoquant la répétition de la texture, comme le montre la partie gauche de la Figure 10.18. Avec le serrage, lorsqu’une coordonnée en dehors de l’intervalle est utilisée pour accéder à un bitmap, elle est ramenée dans l’intervalle. Cela a pour effet d’étirer les pixels de bord du bitmap vers l’extérieur, comme représenté sur la partie droite de la Figure 10.18. Le maillage dans les deux cas est identique : un seul polygone avec quatre sommets. Et les maillages ont des coordonnées UV identiques. La seule différence est la façon dont les coordonnées en dehors de l’intervalle sont interprétées.
| Répétition | Serrage |
 |
 |
Figure 10.18Comparaison des modes d’adressage de texture répétition et serrage
Il existe d’autres options supportées sur certains matériels, comme le miroir, qui est similaire à la répétition sauf que chaque tuile alternative est mise en miroir. (Cela peut être bénéfique car cela garantit qu’il n’y aura pas de « couture » entre les tuiles adjacentes.) Sur la plupart des matériels, le mode d’adressage peut être défini indépendamment pour les coordonnées et . Il est important de comprendre que ces règles sont appliquées au dernier moment, lorsque les coordonnées sont utilisées pour indexer dans la texture. Les coordonnées aux sommets ne sont pas limitées ni traitées de quelque façon que ce soit ; sinon, elles ne pourraient pas être interpolées correctement sur la face.
La Figure 10.19 montre un dernier exemple instructif : le même maillage est mappé en texture de deux façons différentes.
 |
 |
 |
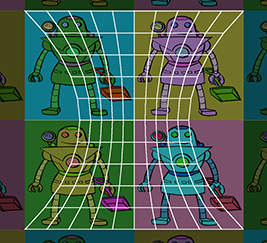 |
Figure 10.19Le placage de texture fonctionne sur des objets qui ne sont pas de simples quadrilatères
10.6Le modèle d’éclairage local standard
Dans l’équation de rendu, la BRDF décrit la distribution de diffusion pour la lumière d’une fréquence et d’une direction d’incidence données. Les différences de distributions entre différentes surfaces sont précisément ce qui fait que ces surfaces (ou même différents points de surface sur le même objet) semblent différentes les unes des autres. La plupart des BRDF sont exprimées dans un ordinateur par une formule, où certains nombres de la formule sont ajustés pour correspondre aux propriétés matérielles souhaitées. La formule elle-même est souvent appelée modèle d’éclairage, et les valeurs particulières entrant dans la formule proviennent du matériau assigné à la surface. Il est courant pour un moteur de jeu d’utiliser seulement quelques modèles d’éclairage, même si les matériaux de la scène peuvent être très divers et qu’il peut y avoir des milliers de BRDF différentes. En effet, il y a seulement quelques années, presque tout le rendu en temps réel était effectué avec un seul modèle d’éclairage. En fait, cette pratique n’est pas rare aujourd’hui.
Ce modèle d’éclairage était si omniprésent qu’il était câblé dans les API de rendu mêmes d’OpenGL et DirectX. Bien que ces parties plus anciennes de l’API soient effectivement devenues des fonctionnalités héritées sur le matériel avec des shaders programmables, le modèle standard est encore couramment utilisé dans le cadre plus général des shaders, des constantes génériques et des interpolants. La grande diversité et la flexibilité disponibles sont généralement utilisées pour déterminer la meilleure façon d’alimenter les paramètres du modèle (par exemple, en effectuant plusieurs éclairages à la fois, ou en effectuant tout l’éclairage à la fin avec le rendu différé), plutôt qu’en utilisant différents modèles. Mais même en ignorant les shaders programmables, au moment de la rédaction de cet ouvrage, la console de jeux vidéo la plus populaire est la Nintendo Wii,13 qui dispose d’un support câblé pour ce modèle standard.
Le vénérable modèle d’éclairage standard fait l’objet de cette section. Puisque son développement précède d’au moins une décennie le cadre de la BRDF et de l’équation de rendu, nous présentons d’abord ce modèle dans le contexte simplifié qui entourait sa création. Cette notation et cette perspective sont encore prédominantes dans la littérature aujourd’hui, c’est pourquoi nous pensons devoir présenter l’idée dans ses propres termes. Au fil du parcours, nous montrons comment une composante du modèle (la composante diffuse) est modélisée comme une BRDF. Le modèle standard est important dans le présent, mais vous devez comprendre l’équation de rendu si vous voulez être préparé pour l’avenir.
10.6.1L’équation d’éclairage standard : vue d’ensemble
Bui Tuong Phong [21] a introduit les concepts de base du modèle d’éclairage standard en 1975. À l’époque, l’accent était mis sur un moyen rapide de modéliser la réflexion directe. Alors que les chercheurs comprenaient certainement l’importance de la lumière indirecte, c’était un luxe qu’on ne pouvait pas encore se permettre. Ainsi, alors que l’équation de rendu (qui, comme nous l’avons noté précédemment, est entrée en focus une décennie environ après la proposition du modèle standard) est une équation pour la radiance sortant d’un point dans une direction particulière, la seule direction sortante qui importait à l’époque était les directions pointant vers l’œil. De même, alors que l’équation de rendu considère la lumière incidente de l’hémisphère entier entourant la normale de surface, si nous ignorons la lumière indirecte, nous n’avons pas besoin de chercher dans toutes les directions incidentes. Nous devons seulement considérer les directions qui visent une source lumineuse. Nous examinons certaines façons différentes dont les sources lumineuses sont modélisées dans les graphismes en temps réel plus en détail dans la Section 10.7, mais pour l’instant un point important est que les sources lumineuses ne sont pas des surfaces émissives dans la scène, comme elles le sont dans l’équation de rendu et dans le monde réel. Au lieu de cela, les lumières sont des entités spéciales sans aucune géométrie correspondante, et sont simulées comme si la lumière émettait depuis un seul point. Ainsi, plutôt que d’inclure un angle solide de directions correspondant à la projection de la surface émissive de chaque source lumineuse sur l’hémisphère entourant , nous ne nous soucions que d’une seule direction incidente pour la lumière. En résumé, l’objectif original du modèle standard était de déterminer la lumière réfléchie dans la direction de la caméra, en ne considérant que les réflexions directes, incidentes depuis un nombre fini de directions, une direction pour chaque source lumineuse.
Voici maintenant le modèle. L’idée de base est de classer la lumière entrant dans l’œil en quatre catégories distinctes, chacune ayant une méthode unique pour calculer sa contribution. Les quatre catégories sont
La contribution émissive, notée , est la même que dans l’équation de rendu. Elle indique la quantité de radiance émise directement par la surface dans la direction donnée. Notez que sans techniques d’illumination globale, ces surfaces n’éclairent réellement rien (sauf elles-mêmes).
La contribution spéculaire, notée , représente la lumière incidente directement d’une source lumineuse qui est dispersée préférentiellement dans la direction d’un « rebond miroir parfait ».
La contribution diffuse, notée , représente la lumière incidente directement d’une source lumineuse qui est dispersée uniformément dans toutes les directions.
La contribution ambiante, notée , est un facteur de correction pour tenir compte de toute la lumière indirecte.
La lettre est destinée à être abrégée pour « contribution ». Notez la police grasse, indiquant que ces contributions ne sont pas des quantités scalaires représentant la quantité de lumière d’une longueur d’onde particulière, mais plutôt des vecteurs représentant des couleurs dans une base avec un nombre discret de composantes (« canaux »). Comme indiqué précédemment, en raison du système de vision humaine tri-stimulus, le nombre de canaux est presque toujours choisi pour être trois. Un choix moins fondamental est celui des trois fonctions de base à utiliser, mais dans les graphismes en temps réel, le choix de loin le plus courant est de faire un canal pour le rouge, un canal pour le bleu et un canal pour le vert. Ces détails sont étonnamment non pertinents dans une discussion de haut niveau (ils n’apparaîtront nulle part dans les équations), mais, bien sûr, ce sont des considérations pratiques importantes.
Le terme émissif est le même que dans l’équation de rendu, donc il n’y a pas grand-chose à dire à son sujet. En pratique, la contribution émissive est simplement une couleur constante en tout point de surface donné . Les termes spéculaire, diffus et ambiant sont plus complexes, nous les discutons donc chacun en détail dans les trois prochaines sections.
10.6.2La composante spéculaire
La composante spéculaire du modèle d’éclairage standard représente la lumière qui est réfléchie (principalement) dans un « rebond miroir parfait » sur la surface. La composante spéculaire est ce qui donne aux surfaces un aspect « brillant ». Les surfaces plus rugueuses ont tendance à disperser la lumière dans un motif de directions beaucoup plus large, ce qui est modélisé par la composante diffuse décrite dans la Section 10.6.3.
Voyons maintenant comment le modèle standard calcule la contribution spéculaire. Les vecteurs importants sont étiquetés dans la Figure 10.20.
est la normale de surface locale pointant vers l’extérieur.
pointe vers l’observateur. (Le symbole , pour « œil », est aussi parfois utilisé pour nommer ce vecteur.)
pointe vers la source lumineuse.
est le vecteur de réflexion, qui est la direction d’un « rebond miroir parfait ». C’est le résultat de la réflexion de autour de .
est l’angle entre et .
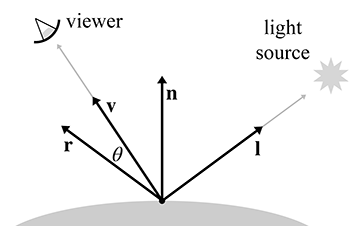
Figure 10.20Modèle de Phong pour la réflexion spéculaire
Par commodité, nous supposons que tous ces vecteurs sont des vecteurs unitaires. Notre convention dans ce livre est de noter les vecteurs unitaires avec des chapeaux, mais nous laisserons tomber les chapeaux pour éviter de décorer les équations excessivement. De nombreux textes sur le sujet utilisent ces noms de variables standard et, surtout dans la communauté des jeux vidéo, ils font effectivement partie du vocabulaire courant. Il n’est pas rare que des questions d’entretien d’embauche soient posées de manière à supposer que le candidat est familier avec ce cadre.
Une remarque sur le vecteur avant de continuer. Puisque les lumières sont des entités abstraites, elles n’ont pas nécessairement besoin d’une « position ». Les lumières directionnelles et les lumières volumétriques de style Doom (voir Section 10.7) sont des exemples pour lesquels la position de la lumière peut ne pas être évidente. Le point clé est que la position de la lumière n’est pas importante, mais l’abstraction utilisée pour la lumière doit faciliter le calcul d’une direction d’incidence en tout point d’ombrage donné. (Elle doit également fournir la couleur et l’intensité de la lumière incidente.)
Parmi les quatre vecteurs, les trois premiers sont des degrés de liberté inhérents au problème, et le vecteur de réflexion est une quantité dérivée qui doit être calculée. La géométrie est montrée dans la Figure 10.21.
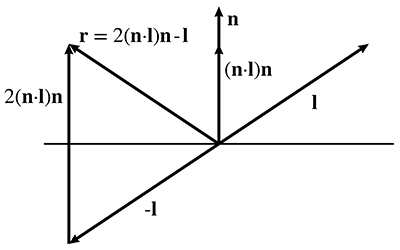
Figure 10.21Construction du vecteur de réflexion
Comme vous pouvez le voir, le vecteur de réflexion peut être calculé par
Le calcul du vecteur de réflexion est une question d’entretien d’embauche populaire
Il y a de nombreux intervieweurs pour qui cette équation est un sujet favori, c’est pourquoi nous l’avons affichée sur une ligne par elle-même, malgré le fait qu’elle aurait très bien pu tenir dans le paragraphe. Un lecteur cherchant un emploi dans l’industrie du jeu vidéo est conseillé de bien digérer la Figure 10.21, pour être capable de produire l’Équation (10.10) sous pression. Notez que si nous supposons que et sont des vecteurs unitaires, alors le sera aussi.
Maintenant que nous connaissons , nous pouvons calculer la contribution spéculaire en utilisant le modèle de Phong pour la réflexion spéculaire (Équation (10.11)).
Le modèle de Phong pour la réflexion spéculaire
Dans cette formule et ailleurs dans ce livre, le symbole désigne la multiplication composante par composante des couleurs. Examinons les entrées de cette formule plus en détail.
Tout d’abord, examinons , qui est la brillance du matériau, également connue sous le nom d’exposant de Phong, d’exposant spéculaire, ou simplement de brillance du matériau. Cela contrôle la largeur du « point chaud » — un plus petit produit une décroissance plus large et plus progressive depuis le point chaud, et un plus grand produit un point chaud très serré avec une décroissance nette. (Nous parlons ici du point chaud d’une réflexion, à ne pas confondre avec le point chaud d’une lumière directionnelle.) Les surfaces parfaitement réfléchissantes, comme le chrome, auraient une valeur extrêmement élevée pour . Quand les rayons lumineux frappent la surface depuis la direction incidente , il y a très peu de variation dans les directions réfléchies. Ils sont réfléchis dans un angle solide très étroit (« cône ») entourant la direction décrite par , avec très peu de dispersion. Les surfaces brillantes qui ne sont pas des réflecteurs parfaits — par exemple, la surface d’une pomme — ont des exposants spéculaires plus faibles, résultant en un point chaud plus grand. Des exposants spéculaires plus faibles modélisent une réflexion moins parfaite des rayons lumineux. Quand les rayons lumineux frappent la surface à la même direction incidente donnée par , il y a plus de variation dans les directions réfléchies. La distribution se regroupe autour de la direction de rebond , mais la décroissance en intensité à mesure que l’on s’éloigne de est plus progressive. Nous montrerons cette différence visuellement dans un moment.
Comme toutes les propriétés matérielles qui sont entrées dans l’équation d’éclairage, la valeur de peut varier sur la surface, et la valeur spécifique pour tout emplacement donné sur cette surface peut être déterminée de n’importe quelle façon, par exemple avec une carte de texture (voir Section 10.5). Cependant, comparé aux autres propriétés matérielles, cela est relativement rare ; en fait, il est assez courant dans les graphismes en temps réel que la valeur de brillance soit une constante pour un matériau entier et ne varie pas sur la surface.
Une autre valeur dans l’Équation (10.11) liée à la « brillance » est la couleur spéculaire du matériau, notée . Alors que contrôle la taille du point chaud, contrôle son intensité et sa couleur. Les surfaces très réfléchissantes auront une valeur plus élevée pour , et les surfaces plus mates auront une valeur plus faible. Si désiré, une carte spéculaire14 peut être utilisée pour contrôler la couleur du point chaud à l’aide d’un bitmap, tout comme une carte de texture contrôle la couleur d’un objet.
La couleur spéculaire de la lumière, notée , est essentiellement la « couleur » de la lumière, qui contient à la fois sa couleur et son intensité. Bien que de nombreuses lumières aient une couleur constante unique, la force de cette couleur s’atténuera avec la distance (Section 10.7.2), et cette atténuation est contenue dans dans notre formulation. De plus, même en ignorant l’atténuation, la même source lumineuse peut émettre de la lumière de différentes couleurs dans différentes directions. Pour les lumières de spot rectangulaires, nous pourrions déterminer la couleur à partir d’un gobo, qui est une image bitmap projetée. Un gobo coloré pourrait être utilisé pour simuler une lumière passant à travers un vitrail, ou un gobo animé pourrait être utilisé pour falsifier les ombres de ventilateurs de plafond tournants ou d’arbres agités par le vent. Nous utilisons la lettre pour représenter « source ». L’indice « » indique que cette couleur est utilisée pour les calculs spéculaires. Une couleur de lumière différente peut être utilisée pour les calculs diffus — c’est une caractéristique du modèle d’éclairage utilisée pour obtenir des effets spéciaux dans certaines circonstances, mais cela n’a aucune signification dans le monde réel. En pratique, est presque toujours égal à la couleur de lumière utilisée pour l’éclairage diffus, qui, sans surprise, est notée dans ce livre comme .

Figure 10.22 Différentes valeurs pour et
La Figure 10.22 montre comment différentes valeurs de et affectent l’apparence d’un objet avec réflexion spéculaire. La couleur spéculaire du matériau va du noir dans la colonne la plus à gauche au blanc dans la colonne la plus à droite. L’exposant spéculaire est grand dans la rangée du haut et diminue à chaque rangée suivante. Notez que les têtes dans la colonne la plus à gauche ont toutes le même aspect ; puisque la force spéculaire est nulle, l’exposant spéculaire est sans importance et il n’y a dans tous les cas aucune contribution spéculaire. (L’éclairage provient des composantes diffuse et ambiante, qui sont discutées dans les Sections 10.6.3 et 10.6.4, respectivement.)
Blinn [4] a popularisé une légère modification du modèle de Phong qui produit des résultats visuels très similaires, mais qui à l’époque représentait une optimisation significative. Dans de nombreux cas, il est encore plus rapide à calculer aujourd’hui, mais sachez que les opérations vectorielles (qui sont réduites avec ce modèle) ne sont pas toujours le goulot d’étranglement des performances. L’idée de base est la suivante : si la distance jusqu’à l’observateur est grande par rapport à la taille d’un objet, alors peut être calculé une fois et ensuite considéré constant pour un objet entier. De même pour une source lumineuse et le vecteur . (En fait, pour les lumières directionnelles, est toujours constant.) Cependant, puisque la normale de surface n’est pas constante, nous devons quand même calculer le vecteur de réflexion , un calcul que nous aimerions éviter, si possible. Le modèle de Blinn introduit un nouveau vecteur , qui représente le vecteur « à mi-chemin » et est le résultat de la moyenne de et puis de la normalisation du résultat :
Le vecteur à mi-chemin , utilisé dans le modèle spéculaire de Blinn
Ensuite, plutôt que d’utiliser l’angle entre et , comme le fait le modèle de Phong, on utilise le cosinus de l’angle entre et . La situation est montrée dans la Figure 10.23.
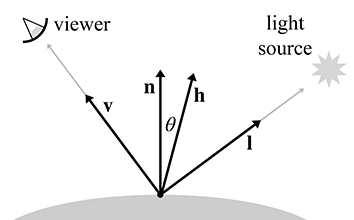
Figure 10.23Modèle de Blinn pour la réflexion spéculaire
La formule pour le modèle de Blinn est très similaire au modèle de Phong original. Seule la partie du produit scalaire est modifiée.
Le modèle de Blinn pour la réflexion spéculaire
Le modèle de Blinn peut être plus rapide à implémenter dans le matériel que le modèle de Phong, si l’observateur et la source lumineuse sont suffisamment éloignés de l’objet pour être considérés constants, puisque alors est une constante et n’a besoin d’être calculé qu’une seule fois. Mais quand ou ne peuvent pas être considérés constants, le calcul de Phong peut être plus rapide. Comme nous l’avons dit, les deux modèles produisent des résultats similaires, mais pas identiques (voir Fisher et Woo [6] pour une comparaison). Les deux sont des modèles empiriques, et le modèle de Blinn ne doit pas être considéré comme une « approximation » du « correct » modèle de Phong. En fait, Ngan et al. [17] ont démontré que le modèle de Blinn présente certains avantages objectifs et correspond plus étroitement aux données expérimentales pour certaines surfaces.
Un détail que nous avons omis est que dans l’un ou l’autre modèle, peut être inférieur à zéro. Dans ce cas, nous ramenons généralement la contribution spéculaire à zéro.
10.6.3La composante diffuse
La prochaine composante dans le modèle d’éclairage standard est la composante diffuse. Comme la composante spéculaire, la composante diffuse modélise également la lumière qui a voyagé directement de la source lumineuse au point d’ombrage. Cependant, alors que la lumière spéculaire représente la lumière qui se réfléchit préférentiellement dans une direction particulière, la lumière diffuse modélise la lumière qui est réfléchie de façon aléatoire dans toutes les directions en raison de la nature rugueuse du matériau de surface. La Figure 10.24 compare comment les rayons lumineux se réfléchissent sur une surface parfaitement réfléchissante et sur une surface rugueuse.
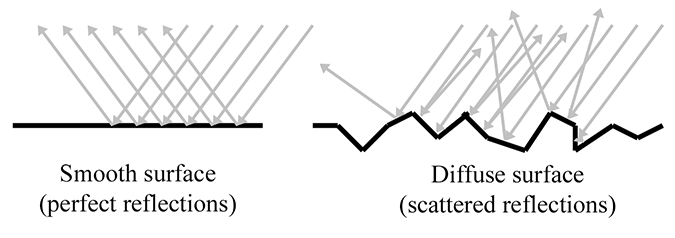
Figure 10.24L’éclairage diffus modélise les réflexions dispersées
Pour calculer l’éclairage spéculaire, nous avions besoin de connaître la position de l’observateur, pour voir à quel point l’œil est proche de la direction du rebond miroir parfait. Pour l’éclairage diffus, en revanche, la position de l’observateur n’est pas pertinente, puisque les réflexions sont dispersées de façon aléatoire, et peu importe où nous positionnons la caméra, il est également probable qu’un rayon nous soit envoyé. Cependant, la direction d’incidence , qui est dictée par la position de la source lumineuse par rapport à la surface, est importante. Nous avons mentionné la loi de Lambert précédemment, mais revoyons-la ici, puisque la partie diffuse de Blinn-Phong est l’endroit le plus important dans les graphismes en temps réel où elle entre en jeu. Si nous imaginons compter les photons qui frappent la surface de l’objet et ont une chance de se réfléchir vers l’œil, une surface perpendiculaire aux rayons lumineux reçoit plus de photons par unité de surface qu’une surface orientée à un angle plus rasant, comme le montre la Figure 10.25.
Figure 10.25 Les surfaces plus perpendiculaires aux rayons lumineux reçoivent plus de lumière par unité de surface
Notez que, dans les deux cas, la distance perpendiculaire entre les rayons est la même. (En raison d’une illusion d’optique dans le diagramme, les rayons à droite peuvent sembler plus éloignés, mais ce n’est pas le cas.) Ainsi, la distance perpendiculaire entre les rayons est la même, mais notez que sur le côté droit de la Figure 10.25, ils frappent l’objet en des points plus éloignés les uns des autres. La surface de gauche reçoit neuf rayons lumineux, et la surface de droite n’en reçoit que six, même si l’« aire » des deux surfaces est la même. Ainsi, le nombre de photons par unité de surface15 est plus élevé à gauche, et elle apparaîtra plus lumineuse, tous les autres facteurs étant égaux. Ce même phénomène est responsable du fait que le climat près de l’équateur est plus chaud que près des pôles. Puisque la Terre est ronde, la lumière du soleil frappe la Terre à un angle plus perpendiculaire près de l’équateur.
L’éclairage diffus obéit à la loi de Lambert : l’intensité de la lumière réfléchie est proportionnelle au cosinus de l’angle entre la normale de surface et les rayons lumineux. Nous calculerons ce cosinus avec le produit scalaire.
Calcul de la composante diffuse selon la loi de Lambert
Comme précédemment, est la normale de surface et est un vecteur unitaire qui pointe vers la source lumineuse. Le facteur est la couleur diffuse du matériau, qui est la valeur à laquelle la plupart des gens pensent quand ils pensent à la « couleur » d’un objet. La couleur diffuse du matériau provient souvent d’une carte de texture. La couleur diffuse de la source lumineuse est ; elle est généralement égale à la couleur spéculaire de la lumière, .
Tout comme avec l’éclairage spéculaire, nous devons empêcher le produit scalaire de devenir négatif en le ramenant à zéro. Cela empêche les objets d’être éclairés par derrière.
Il est très instructif de voir comment les surfaces diffuses sont implémentées dans le cadre de l’équation de rendu.
La réflexion diffuse modélise la lumière qui est dispersée de façon complètement aléatoire, et toute direction sortante donnée est également probable, peu importe la direction de la lumière entrante. Ainsi, la BRDF pour une surface parfaitement diffuse est une constante.
Notez la similitude de l’ Équation (10.12) avec le contenu de l’intégrale de l’équation de rendu,
Le premier facteur est la couleur de la lumière incidente. La couleur du matériau est la valeur constante de la BRDF, qui vient ensuite. Enfin, nous avons le facteur de Lambert.
10.6.4Les composantes ambiante et émissive
L’éclairage spéculaire et diffus représentent tous deux les rayons lumineux qui voyagent directement de la source lumineuse à la surface de l’objet, « rebondissent » une fois, puis arrivent dans l’œil. Cependant, dans le monde réel, la lumière rebondit souvent sur un ou plusieurs objets intermédiaires avant de frapper un objet et de se réfléchir vers l’œil. Quand vous ouvrez la porte du réfrigérateur au milieu de la nuit, toute la cuisine devient un peu plus lumineuse, même si la porte du réfrigérateur bloque la plupart de la lumière directe.
Pour modéliser la lumière qui est réfléchie plus d’une fois avant d’entrer dans l’œil, nous pouvons utiliser une approximation très grossière connue sous le nom de « lumière ambiante ». La partie ambiante de l’équation d’éclairage dépend uniquement des propriétés du matériau et d’une valeur d’éclairage ambiant, qui est souvent une valeur globale utilisée pour toute la scène. Aucune des sources lumineuses ne sont impliquées dans le calcul. (En fait, une source lumineuse n’est même pas nécessaire.) L’Équation (10.13) est utilisée pour calculer la composante ambiante :
Contribution ambiante à l’équation d’éclairage
Le facteur est la « couleur ambiante » du matériau. C’est presque toujours la même que la couleur diffuse (qui est souvent définie à l’aide d’une carte de texture). L’autre facteur, , est la valeur de lumière ambiante. Nous utilisons la notation pour « global », car souvent une valeur ambiante globale unique est utilisée pour toute la scène. Cependant, certaines techniques, comme les sondes d’éclairage, tentent de fournir un éclairage indirect plus localisé et dépendant de la direction.
Parfois, un rayon lumineux voyage directement de la source lumineuse vers l’œil, sans frapper aucune surface entre les deux. L’équation d’éclairage standard prend en compte ces rayons en attribuant à un matériau une couleur émissive. Par exemple, lorsque nous rendons la surface d’une ampoule, cette surface apparaîtra probablement très lumineuse, même s’il n’y a pas d’autres sources lumineuses dans la scène, parce que l’ampoule émet de la lumière.
Dans de nombreuses situations, la contribution émissive ne dépend pas de facteurs environnementaux ; c’est simplement la couleur émissive du matériau :
La contribution émissive dépend uniquement du matériau
La plupart des surfaces n’émettent pas de lumière, donc leur composante émissive est . Les surfaces qui ont une composante émissive non nulle sont appelées « auto-illuminées ».
Il est important de comprendre que dans les graphismes en temps réel, une surface auto-illuminée n’éclaire pas les autres surfaces — vous avez besoin d’une source lumineuse pour cela. En d’autres termes, nous ne rendons pas réellement les sources lumineuses, nous ne rendons que les effets que ces sources lumineuses ont sur les surfaces de la scène. Nous rendons bien les surfaces auto-illuminées, mais ces surfaces n’interagissent pas avec les autres surfaces de la scène. Lorsqu’on utilise l’équation de rendu correctement, cependant, les surfaces émissives éclairent effectivement leur environnement.
Nous pouvons choisir d’atténuer la contribution émissive en raison de conditions atmosphériques, comme le brouillard, et bien sûr il peut y avoir des raisons de performance pour faire disparaître des objets dans la distance. Cependant, comme expliqué dans la Section 10.7.2, en général la contribution émissive ne devrait pas être atténuée en raison de la distance de la même façon que les sources lumineuses.
10.6.5L’équation d’éclairage : tout assembler
Nous avons discuté en détail les composantes individuelles de l’équation d’éclairage. Il est maintenant temps de donner l’équation complète pour le modèle d’éclairage standard.
L’équation d’éclairage standard pour une source lumineuse

Figure \caption@xref {fig:graphics_lighting_equation_head}{ on input line 3591} La contribution visuelle de chacune des composantes de l’équation d’éclairage
La Figure \caption@xref fig:graphics_lighting_equation_head on input line 3591 montre à quoi ressemblent réellement les composantes d’éclairage ambiant, diffus et spéculaire isolément des autres. (Nous ignorons la composante émissive, en supposant que cette tête flottante particulière n’émet pas de lumière.) Il y a plusieurs points intéressants à noter :
L’oreille est éclairée tout aussi brillamment que le nez, même si elle est en fait dans l’ombre de la tête. Pour les ombres, nous devons déterminer si la lumière peut réellement « voir » le point en cours d’ombrage, en utilisant des techniques telles que le placage d’ombres (shadow mapping).
Dans les deux premières images, sans lumière ambiante, le côté de la tête qui fait face à l’opposé de la lumière est complètement noir. Pour éclairer le « côté arrière » des objets, vous devez utiliser la lumière ambiante. Placer suffisamment de lumières dans votre scène afin que chaque surface soit éclairée directement est la meilleure situation, mais ce n’est pas toujours possible. Un hack courant, que Mitchell et al. [16] ont appelé éclairage « Half Lambert », consiste à biaiser le terme de Lambert, permettant à l’éclairage diffus de « s’enrouler » vers le côté arrière du modèle pour éviter qu’il soit jamais aplati et éclairé uniquement par la lumière ambiante. Cela peut facilement être fait en remplaçant le terme standard par , où est un paramètre ajustable qui spécifie l’effet d’enroulement supplémentaire. (Mitchell et al. suggèrent d’utiliser , et ils mettent également le résultat au carré.) Bien que cet ajustement ait peu de base physique, il a un très grand bénéfice perceptuel, surtout compte tenu du faible coût de calcul.
Avec seulement l’éclairage ambiant, seule la silhouette est visible. L’éclairage est un indice visuel extrêmement puissant qui fait apparaître l’objet en « 3D ». La solution à cet effet « dessin animé » est de placer un nombre suffisant de lumières dans la scène afin que chaque surface soit éclairée directement.
En parlant de plusieurs lumières, comment fonctionnent plusieurs sources lumineuses avec l’équation d’éclairage ? Nous devons additionner les valeurs d’éclairage pour toutes les lumières. Pour simplifier la notation, nous allons faire l’hypothèse quasi universelle que . Ensuite, nous pouvons laisser désigner la couleur de la -ième source lumineuse, incluant le facteur d’atténuation. L’indice va de à , où est le nombre de lumières. L’équation d’éclairage devient alors
L’équation d’éclairage standard pour plusieurs sources lumineuses
Puisqu’il n’y a qu’une seule valeur de lumière ambiante et une seule composante émissive pour toute surface donnée, ces composantes ne sont pas sommées par source lumineuse.
10.6.6Limitations du modèle standard
De nos jours, nous avons la liberté des shaders programmables et pouvons choisir n’importe quel modèle d’éclairage que nous souhaitons. Puisque le modèle standard présente des lacunes assez sérieuses, vous pourriez très bien demander : « Pourquoi apprendre cette ancienne histoire ? » Premièrement, ce n’est pas exactement de l’ancienne histoire ; elle est vivante et bien présente. Les raisons qui en ont fait un bon compromis entre réalisme, utilisabilité et vitesse de calcul s’appliquent toujours. Oui, nous avons plus de puissance de traitement ; mais nous voulons aussi rendre plus de pixels et plus de lumières, et il est actuellement très courant que le modèle d’éclairage standard soit le gagnant lorsque les programmeurs décident de dépenser des cycles sur plus de pixels (résolution plus élevée) ou des pixels plus précis (un modèle d’éclairage plus précis). Deuxièmement, le modèle d’éclairage local actuel est celui que les créateurs de contenu peuvent comprendre et utiliser. Cet avantage ne doit pas être pris à la légère. Les artistes ont des décennies d’expérience avec les cartes diffuses et spéculaires. Passer à un modèle d’éclairage qui remplace ces entrées familières par des différentes telles que la « métallicité » (du modèle de Strauss [26]) pour lesquelles les artistes n’ont pas une compréhension intuitive est un prix élevé à payer. Une dernière raison d’apprendre le modèle d’éclairage standard est que de nombreux modèles plus récents présentent des similitudes avec le modèle standard, et vous ne pouvez pas savoir quand utiliser des modèles d’éclairage plus avancés sans comprendre l’ancien standard.
Si vous avez lu la documentation OpenGL ou DirectX pour définir les paramètres des matériaux, on vous pardonne de penser que ambiant, diffus et spéculaire sont « comment fonctionne la lumière » (rappelez-vous notre avertissement au début de ce chapitre) par opposition à des constructs pratiques arbitraires particuliers à un modèle d’éclairage particulier. La dichotomie entre diffus et spéculaire n’est pas une réalité physique inhérente ; elle est plutôt apparue (et continue d’être utilisée) en raison de considérations pratiques. Ce sont des termes descriptifs pour deux modèles de dispersion extrêmes, et en prenant des combinaisons arbitraires de ces deux modèles, de nombreux phénomènes peuvent être approximés à un degré décent.
En raison de l’adoption quasi unanime de ce modèle, il est souvent utilisé sans lui donner de nom, et en fait il y a encore une certaine confusion quant à ce qu’il faut exactement l’appeler. Vous pourriez l’appeler le modèle d’éclairage Phong, parce que Phong a introduit l’idée de base de modéliser la réflexion comme la somme de contributions diffuses et spéculaires, et a également fourni un calcul empiriquement utile pour la réflexion spéculaire. (Le modèle de Lambert pour la réflexion diffuse était déjà connu.) Nous avons vu que le calcul de Blinn pour la réflexion spéculaire est similaire mais parfois plus rapide. Parce que c’est le calcul spécifique le plus souvent utilisé, devrions- nous peut-être l’appeler le modèle de Blinn ? Mais le nom de Blinn est également attaché à un modèle de microfacettes différent dans lequel diffus et spéculaire sont à des extrémités différentes d’un spectre continu, plutôt que des composantes « orthogonales » indépendantes qui se mélangent. Puisque la plupart des implémentations utilisent l’optimisation de Blinn pour l’idée de base de Phong, le nom Blinn-Phong est celui le plus souvent utilisé pour ce modèle, et c’est le nom que nous utilisons.
Une grande partie de l’éclairage réaliste est, bien sûr, les ombres réalistes. Bien que les techniques pour produire des ombres soient intéressantes et importantes, hélas nous n’aurons pas le temps de les discuter ici. Dans la théorie de l’équation de rendu, les ombres sont prises en compte lorsque nous déterminons la radiance incidente dans une direction donnée. Si une lumière (plus précisément, une surface émissive) existe dans une direction particulière, et que le point peut « voir » cette surface, alors sa lumière sera incidente sur le point. Si, cependant, il y a une autre surface qui obscurcit la source lumineuse en regardant dans cette direction, alors le point est dans l’ombre par rapport à cette source lumineuse. Plus généralement, les ombres ne sont pas seulement dues à la lumière des surfaces émissives ; la lumière rebondissant sur des surfaces réfléchissantes peut aussi causer des ombres. Dans tous les cas, les ombres sont une question de visibilité de la lumière, et non de modèle de réflectance.
Enfin, nous souhaitons mentionner plusieurs phénomènes physiques importants qui ne sont pas correctement capturés par le modèle de Blinn-Phong. Le premier est la réflectance de Fresnel16, qui prédit que la réflectance des non-métaux est plus forte lorsque la lumière est incidente à un angle rasant, et la plus faible lorsqu’elle est incidente depuis l’angle normal. Certaines surfaces, comme le velours, présentent une rétroréflexion ; vous pourriez deviner que cela signifie que la surface ressemble aux boucles d’oreilles de Madonna, mais cela signifie en fait que la direction principale de réflexion n’est pas le « rebond miroir » tel que prédit par Blinn-Phong, mais plutôt vers la source lumineuse. Enfin, Blinn-Phong est isotrope, ce qui signifie que si nous faisons tourner la surface tout en gardant l’observateur et la source lumineuse fixes, la réflectance ne changera pas. Certaines surfaces ont une réflexion anisotrope, due à des rainures ou d’autres motifs dans la surface. Cela signifie que la force de la réflexion varie, en fonction de la direction d’incidence par rapport à la direction des rainures, parfois appelée la direction de rayure. Les exemples classiques de matériaux anisotropes sont le métal brossé, les cheveux et ces petits ornements de Noël faits de fibres brillantes.
10.6.7L’ombrage plat et Gouraud
Sur le matériel moderne basé sur les shaders, les calculs d’éclairage sont généralement effectués par pixel. Par cela, nous entendons que pour chaque pixel, nous déterminons une normale de surface (que ce soit en interpolant la normale de vertex sur la face ou en la récupérant d’une carte de relief), puis nous effectuons l’équation d’éclairage complète en utilisant cette normale de surface. C’est l’éclairage par pixel, et la technique d’interpolation des normales de vertex sur la face est parfois appelée ombrage de Phong, à ne pas confondre avec le calcul de Phong pour la réflexion spéculaire. L’alternative à l’ombrage de Phong est d’effectuer l’équation d’éclairage moins fréquemment (par face, ou par vertex). Ces deux techniques sont connues respectivement sous le nom d’ombrage plat et d’ombrage de Gouraud. L’ombrage plat n’est presque jamais utilisé en pratique, sauf dans le rendu logiciel. En effet, la plupart des méthodes modernes d’envoi de géométrie efficacement au matériel ne fournissent aucune donnée au niveau de la face. L’ombrage de Gouraud, en revanche, a encore une utilisation limitée sur certaines plateformes. Certains principes généraux importants peuvent être tirés de l’étude de ces méthodes, donc examinons leurs résultats.

Figure 10.27Une théière avec ombrage plat
Lors de l’utilisation de l’ombrage plat, nous calculons une seule valeur d’éclairage pour l’ensemble du triangle. Généralement, la « position » utilisée dans les calculs d’éclairage est le centroïde du triangle, et la normale de surface est la normale du triangle. Comme vous pouvez le voir dans la Figure 10.27, lorsqu’un objet est éclairé en utilisant l’ombrage plat, la nature facettée de l’objet devient douloureusement apparente, et toute illusion de lissage est perdue.
L’ombrage de Gouraud, également connu sous le nom d’ombrage de vertex, d’éclairage de vertex ou d’ombrage interpolé, est une astuce par laquelle les valeurs pour l’éclairage, le brouillard, etc. sont calculées au niveau du vertex. Ces valeurs sont ensuite linéairement interpolées sur la face du polygone. La Figure 10.28 montre la même théière rendue avec l’ombrage de Gouraud.

Figure 10.28Une théière avec ombrage de Gouraud
Comme vous pouvez le voir, l’ombrage de Gouraud fait un travail relativement bon pour restaurer la nature lisse de l’objet. Lorsque les valeurs approximées sont essentiellement linéaires sur le triangle, bien sûr, l’interpolation linéaire utilisée par l’ombrage de Gouraud fonctionne bien. L’ombrage de Gouraud se dégrade lorsque les valeurs ne sont pas linéaires, comme dans le cas des reflets spéculaires.

Figure 10.29Une théière avec ombrage de Phong
Comparez les reflets spéculaires dans la théière avec ombrage de Gouraud avec les reflets dans une théière avec ombrage de Phong (par pixel), montrée dans la Figure 10.29. Remarquez combien les reflets sont plus lisses. À l’exception de la silhouette et des zones de discontinuités géométriques extrêmes, comme la poignée et le bec, l’illusion de lissage est très convaincante. Avec l’ombrage de Gouraud, les facettes individuelles sont détectables en raison des reflets spéculaires.
Le problème fondamental avec l’ombrage interpolé est qu’aucune valeur au milieu du triangle ne peut être plus grande que la plus grande valeur à un vertex ; les reflets ne peuvent se produire qu’à un vertex. Une tessellation suffisante peut surmonter ce problème. Malgré ses limites, l’ombrage de Gouraud est encore utilisé sur certains matériels limités, comme les plateformes portables et la Nintendo Wii.
Une question que vous devriez vous poser est de savoir dans quel espace de coordonnées les calculs d’éclairage devraient être effectués. Nous pourrions effectuer les calculs d’éclairage dans l’espace mondial. Les positions et normales de vertex seraient transformées en espace mondial, l’éclairage serait effectué, puis les positions de vertex seraient transformées en espace de découpe. Ou nous pourrions transformer les lumières en espace de modélisation, et effectuer les calculs d’éclairage en espace de modélisation. Puisqu’il y a généralement moins de lumières que de vertices, cela entraîne moins de multiplications vecteur-matrice globales. Une troisième possibilité est d’effectuer les calculs d’éclairage en espace caméra.
10.7Sources lumineuses
Dans l’équation de rendu, les sources lumineuses produisent leur effet lorsque nous tenons compte de la composante émissive d’une surface. Comme mentionné précédemment, dans les graphismes en temps réel, faire cela « correctement » avec des surfaces émissives est généralement un luxe qu’on ne peut pas se permettre. Même dans des situations hors-ligne où cela peut être fait, nous pourrions avoir des raisons d’émettre de la lumière de nulle part, pour faciliter le contrôle de l’apparence de la scène pour un éclairage dramatique, ou pour simuler la lumière qui se réfléchirait depuis une surface pour laquelle nous ne perdons pas de temps à modéliser la géométrie puisqu’elle est hors caméra. Ainsi, nous avons généralement des sources lumineuses qui sont des entités abstraites dans le cadre de rendu sans géométrie de surface propre. Cette section discute de certains des types de sources lumineuses les plus courants.
La Section 10.7.1 couvre les lumières ponctuelles, directionnelles et de spot classiques. La Section 10.7.2 considère comment la lumière s’atténue dans le monde réel et comment les écarts par rapport à cette réalité sont courants pour des raisons pratiques. Les deux sections suivantes s’éloignent du territoire théoriquement pur et entrent dans le domaine désordonné des techniques d’éclairage ad-hoc utilisées dans les graphismes en temps réel aujourd’hui. La Section 10.7.3 présente le sujet des lumières volumétriques de style Doom. Enfin, la Section 10.7.4 discute de la façon dont les calculs d’éclairage peuvent être effectués hors-ligne et ensuite utilisés à l’exécution, notamment dans le but d’incorporer des effets d’éclairage indirect.
10.7.1Types de lumières abstraites standard
Cette section liste certains des types de lumières les plus basiques qui sont supportés par la plupart des systèmes de rendu, même les plateformes plus anciennes ou limitées, comme les pipelines d’éclairage à fonction fixe d’OpenGL et DirectX ou la Nintendo Wii. Bien sûr, les systèmes avec des shaders programmables utilisent souvent aussi ces types de lumières. Même lorsque des méthodes complètement différentes, comme les harmoniques sphériques, sont utilisées à l’exécution, les types de lumières standards sont généralement utilisés comme interface d’édition hors-ligne.
Une source lumineuse ponctuelle représente la lumière qui émane depuis un seul point vers l’extérieur dans toutes les directions. Les lumières ponctuelles sont également appelées lumières omni (abrégé de « omnidirectionnel ») ou lumières sphériques. Une lumière ponctuelle a une position et une couleur, qui contrôle non seulement la teinte de la lumière, mais aussi son intensité. La Figure 10.30 montre comment 3DS Max représente les lumières ponctuelles visuellement.
Figure 10.30Une lumière ponctuelle
Comme la Figure 10.30 l’illustre, une lumière ponctuelle peut avoir un rayon de décroissance, qui contrôle la taille de la sphère éclairée par la lumière. L’intensité de la lumière diminue généralement plus on s’éloigne du centre de la lumière. Bien que non réaliste, il est souhaitable pour de nombreuses raisons que l’intensité tombe à zéro à la distance de décroissance, afin que le volume de l’effet de la lumière puisse être délimité. La Section 10.7.2 compare l’atténuation du monde réel avec les modèles simplifiés couramment utilisés. Les lumières ponctuelles peuvent être utilisées pour représenter de nombreuses sources lumineuses courantes, comme les ampoules, les lampes, les feux, etc.
Une lumière de spot est utilisée pour représenter la lumière depuis un emplacement spécifique dans une direction spécifique. Elles sont utilisées pour des lumières comme les torches, les phares et bien sûr, les projecteurs de scène ! Une lumière de spot a une position et une orientation, et optionnellement une distance de décroissance. La forme de la zone éclairée est soit un cône, soit une pyramide.
Un spot conique a un « fond » circulaire. La largeur du cône est définie par un angle de décroissance (à ne pas confondre avec la distance de décroissance). Il y a aussi un angle intérieur qui mesure la taille du point chaud. Un spot conique est montré dans la Figure 10.31.
Figure 10.31Un spot conique
Un spot rectangulaire forme une pyramide plutôt qu’un cône. Les spots rectangulaires sont particulièrement intéressants car ils sont utilisés pour projeter une image. Par exemple, imaginez marcher devant un écran de cinéma pendant qu’un film est diffusé. Cette image projetée porte de nombreux noms, notamment carte de lumière projetée, gobo, et même cookie.17 Le terme gobo vient du monde du théâtre, où il désigne un masque ou un filtre placé sur un spot utilisé pour créer une lumière colorée ou un effet spécial, et c’est le terme que nous utilisons dans ce livre. Les gobos sont très utiles pour falsifier des ombres et d’autres effets d’éclairage. Si les spots coniques ne sont pas directement supportés, ils peuvent être implémentés avec un gobo circulaire conçu de manière appropriée.
Une lumière directionnelle représente la lumière émanant d’un point dans l’espace suffisamment éloigné pour que tous les rayons lumineux impliqués dans l’éclairage de la scène (ou au moins l’objet que nous considérons actuellement) puissent être considérés comme parallèles. Le soleil et la lune sont les exemples les plus évidents de lumières directionnelles, et nous n’essaierions certainement pas de spécifier la position réelle du soleil dans l’espace mondial pour éclairer correctement la scène. Ainsi, les lumières directionnelles n’ont généralement pas de position, du moins en ce qui concerne les calculs d’éclairage, et elles ne s’atténuent généralement pas. Pour les besoins d’édition, cependant, il est souvent utile de créer une « boîte » de lumière directionnelle qui peut être déplacée et placée stratégiquement, et nous pourrions inclure des facteurs d’atténuation supplémentaires pour faire décroître la lumière au bord de la boîte. Les lumières directionnelles sont parfois appelées lumières parallèles. Nous pourrions également utiliser un gobo sur une lumière directionnelle, dans ce cas la projection de l’image est orthographique plutôt que perspective, comme c’est le cas avec les spots rectangulaires.
Comme nous l’avons dit, dans l’équation de rendu et dans le monde réel, les lumières sont des surfaces émissives avec des surfaces finies. Les types de lumières abstraites n’ont aucune surface, et nécessitent donc un traitement spécial pendant l’intégration. Typiquement dans un intégrateur de Monte Carlo, un échantillon est spécifiquement choisi pour être dans la direction de la source lumineuse, et la multiplication par est ignorée. Imaginez que, plutôt que la lumière venant d’un seul point, elle vient d’un disque d’une certaine surface non nulle faisant face au point éclairé. Imaginez maintenant que nous réduisons la surface du disque à zéro, tout en augmentant la radiosité (flux d’énergie par unité de surface) du disque de telle sorte que le flux radiant (flux d’énergie total) reste constant. Une lumière abstraite peut être considérée comme le résultat de ce processus limite d’une manière très similaire à un delta de Dirac (voir la Section 12.4.3). La radiosité est infinie, mais le flux est fini.
Bien que les types de lumières discutés jusqu’ici soient les types classiques supportés par les pipelines en temps réel à fonction fixe, nous sommes certainement libres de définir des volumes de lumière de toute façon que nous trouvons utile. Les lumières volumétriques discutées dans la Section 10.7.3 sont un système alternatif qui est flexible et également adapté au rendu en temps réel. Warn [27] et Barzel [3] discutent des systèmes plus flexibles pour façonner les lumières plus en détail.
10.7.2Atténuation de la lumière
La lumière s’atténue avec la distance. C’est-à-dire que les objets reçoivent moins d’éclairage d’une lumière à mesure que la distance entre la lumière et l’objet augmente. Dans le monde réel, l’intensité d’une lumière est inversement proportionnelle au carré de la distance entre la lumière et l’objet, comme
Atténuation de la lumière dans le monde réel
où est le flux radiant (la puissance radiante par unité de surface) et est la distance. Pour comprendre le carré dans l’atténuation du monde réel, considérez la sphère formée par tous les photons émis depuis une lumière ponctuelle au même instant. À mesure que ces photons se déplacent vers l’extérieur, une sphère de plus en plus grande est formée par le même nombre de photons. La densité de ce flux de photons par unité de surface (le flux radiant) est inversement proportionnelle à la surface de la sphère, qui est proportionnelle au carré du rayon (voir la Section 9.3).
Faisons une pause ici pour discuter d’un point plus subtil : la luminosité perçue d’un objet (ou d’une source lumineuse) ne diminue pas avec l’augmentation de la distance par rapport à l’observateur, en ignorant les effets atmosphériques. À mesure qu’une lumière ou un objet s’éloigne de l’observateur, l’éclairement sur notre œil diminue pour les raisons qui viennent d’être décrites. Cependant, la luminosité perçue est liée à la radiance, pas à l’éclairement. Rappelez-vous que la radiance mesure la puissance par unité de surface projetée par unité d’angle solide, et lorsque l’objet s’éloigne de la vue, la diminution de l’éclairement est compensée par la diminution de l’angle solide sous-tendu par l’objet. Il est particulièrement instructif de comprendre comment l’équation de rendu tient naturellement compte de l’atténuation de la lumière. À l’intérieur de l’intégrale, pour chaque direction sur l’hémisphère entourant le point d’ombrage , nous mesurons la radiance incidente depuis une surface émissive dans cette direction. Nous venons de dire que cette radiance ne s’atténue pas avec la distance. Cependant, à mesure que la source lumineuse s’éloigne de , elle occupe un angle solide plus petit sur cet hémisphère. Ainsi, l’atténuation se produit automatiquement dans l’équation de rendu si nos sources lumineuses ont une surface finie. Cependant, pour les sources lumineuses abstraites émanant d’un seul point (delta de Dirac), l’atténuation doit être manuellement prise en compte. Parce que cela est un peu déroutant, résumons la règle générale pour le rendu en temps réel. Les surfaces émissives, qui sont rendues et ont une surface finie, ne sont généralement pas atténuées en raison de la distance — mais elles peuvent être affectées par des effets atmosphériques comme le brouillard. Pour les besoins du calcul de la couleur effective de la lumière lors de l’ombrage d’un point particulier, les types de lumières abstraites standard sont atténués.
En pratique, l’Équation (10.16) peut être difficile à manier pour deux raisons. Premièrement, l’intensité de la lumière augmente théoriquement vers l’infini à . (C’est le résultat de la lumière étant un delta de Dirac, comme mentionné précédemment.) Barzel [3] décrit un ajustement simple pour passer en douceur de la courbe en carré inverse près de l’origine de la lumière, afin de limiter l’intensité maximale près du centre. Deuxièmement, l’intensité de la lumière ne tombe jamais complètement à zéro.
Au lieu du modèle du monde réel, un modèle plus simple basé sur la distance de décroissance est souvent utilisé. La Section 10.7 a mentionné que la distance de décroissance contrôle la distance au-delà de laquelle la lumière n’a aucun effet. Il est courant d’utiliser une formule d’interpolation linéaire simple telle que la lumière s’estompe progressivement avec la distance :
Modèle d’atténuation linéaire typique
Comme le montre l’Équation (10.17), il y a en fait deux distances utilisées pour contrôler l’atténuation. Dans , la lumière est à pleine intensité (100%). À mesure que la distance passe de à , l’intensité varie linéairement de 100% à 0%. À et au-delà, l’intensité de la lumière est de 0%. Donc fondamentalement, contrôle la distance à laquelle la lumière commence à décroître ; elle est souvent nulle, ce qui signifie que la lumière commence à décroître immédiatement. La quantité est la distance de décroissance réelle — la distance où la lumière a complètement décru et n’a plus aucun effet. La Figure 10.32 compare l’atténuation de la lumière du monde réel au modèle d’atténuation linéaire simple.
Figure 10.32Atténuation de la lumière dans le monde réel par rapport à l’atténuation linéaire simple
L’atténuation en fonction de la distance peut être appliquée aux lumières ponctuelles et aux spots ; les lumières directionnelles ne sont généralement pas atténuées. Un facteur d’atténuation supplémentaire est utilisé pour les spots. La décroissance du point chaud atténue la lumière à mesure que l’on se rapproche du bord du cône.
10.7.3Lumières volumétriques de style Doom
Dans le cadre théorique de l’équation de rendu ainsi que dans les shaders HLSL effectuant des équations d’éclairage en utilisant le modèle Blinn-Phong standard, tout ce qui est requis d’une source lumineuse pour être utilisée dans les calculs d’ombrage à un point particulier est une couleur de lumière (intensité) et une direction d’incidence. Cette section discute d’un type de lumière volumétrique, popularisé par le moteur Doom 3 (également connu sous le nom d’id Tech 4) vers 2003, qui spécifie ces valeurs d’une manière originale. Non seulement ces types de lumières sont-ils intéressants à comprendre d’un point de vue pratique (ils sont encore utiles aujourd’hui), mais ils sont intéressants d’un point de vue théorique car ils illustrent une approximation élégante et rapide. De telles approximations sont l’essence de l’art du rendu en temps réel.
L’aspect le plus créatif des lumières volumétriques de style Doom est la façon dont elles déterminent l’intensité en un point donné. Elle est contrôlée à travers deux cartes de texture. Une carte est essentiellement un gobo, qui peut être projeté par projection orthographique ou perspective, similaire à un spot ou une lumière directionnelle. L’autre carte est une carte unidimensionnelle, connue sous le nom de carte de décroissance, qui contrôle la décroissance. La procédure pour déterminer l’intensité de la lumière au point est la suivante : est multiplié par une matrice , et les coordonnées résultantes sont utilisées pour indexer dans les deux cartes. Le gobo 2D est indexé en utilisant , et la carte de décroissance 1D est indexée avec . Le produit de ces deux texels définit l’intensité de la lumière en .
| Omni | Spot | Faux spot | |
 |
 |
 |
|
| Exemple | |||
| [-12pt] |  |
 |
 |
| Gobo | |||
| [-12pt] Décroissance |  |
 |
 |
| Projection | Orthographique | Perspective | Orthographique |
 |
 |
 |
|
| Boîte englobante | |||
| [-12pt] |
Figure 10.33Exemples de lumières volumétriques de style Doom
Les exemples de la Figure 10.33 vont clarifier cela. Examinons chacun des exemples plus en détail. La lumière omni projette le gobo circulaire orthographiquement sur la boîte, et place la « position » de la lumière (qui est utilisée pour calculer le vecteur ) au centre de la boîte. La matrice utilisée pour générer les coordonnées de texture dans ce cas est
Matrice de génération de coordonnées de texture pour une lumière omni de style Doom
où , et sont les dimensions de la boîte sur chaque axe. Cette matrice opère sur des points dans l’espace objet de la lumière, où la position de la lumière est au centre de la boîte, donc pour la matrice qui opère sur des coordonnées en espace mondial, nous aurions besoin de multiplier cette matrice par une matrice monde-vers-objet à gauche. Notez que la colonne la plus à droite est , puisque nous utilisons une projection orthographique sur le gobo. La translation de 1/2 est pour ajuster les coordonnées de la plage dans la plage de la texture. Notez également le retournement de l’axe , car pointe vers le haut dans nos conventions 3D, mais pointe vers le bas dans la texture.
Ensuite, examinons le spot. Il utilise une projection perspective, où le centre de projection est à une extrémité de la boîte. La position de la lumière utilisée pour calculer le vecteur est au même emplacement, mais ce n’est pas toujours le cas ! Notez que le même gobo circulaire est utilisé que pour l’omni, mais en raison de la projection perspective, il forme une forme conique. La carte de décroissance est la plus lumineuse à l’extrémité de la boîte la plus proche du centre de projection et décroît linéairement le long de l’axe , qui est la direction de projection du gobo dans tous les cas. Notez que le tout premier pixel de la carte de décroissance du spot est noir, pour éviter que les objets « derrière » la lumière soient éclairés ; en fait, tous les gobos et cartes de décroissance ont des pixels noirs à leurs bords, car ces pixels seront utilisés pour toute géométrie en dehors de la boîte. (Le mode d’adressage doit être réglé sur clamp pour éviter que le gobo et la carte de décroissance ne se reproduisent dans l’espace 3D.) La matrice de génération de texture pour les spots perspective est
Matrice de génération de coordonnées de texture pour un spot de style Doom
Le « faux spot » à droite est peut-être le plus intéressant. Ici, la projection est orthographique, et elle est latérale. La nature conique de la lumière ainsi que sa décroissance (ce que nous pensons ordinairement comme la décroissance) sont toutes deux encodées dans le gobo. La carte de décroissance utilisée pour cette lumière est la même que pour la lumière omni : elle est la plus lumineuse au centre de la boîte, et fait s’estomper la lumière à mesure que l’on s’approche des faces et de la boîte. La matrice de coordonnées de texture dans ce cas est en fait la même que pour l’omni. Tout le changement vient de l’utilisation d’un gobo différent, et de l’orientation correcte de la lumière !
Vous devriez étudier ces exemples jusqu’à ce que vous soyez sûr de comprendre comment ils fonctionnent.
Les lumières volumétriques de style Doom peuvent être attrayantes pour les graphismes en temps réel pour plusieurs raisons :
Elles sont simples et efficaces, ne nécessitant que les fonctionnalités de base de génération de coordonnées de texture, et deux recherches de texture. Ce sont des opérations flexibles qui peuvent facilement être câblées dans du matériel à fonction fixe comme la Nintendo Wii.
De nombreux types de lumières et effets différents peuvent être représentés dans le même cadre. Cela peut être utile pour limiter le nombre de shaders différents nécessaires. Les modèles d’éclairage, les types de lumières, les propriétés des matériaux et les passes d’éclairage peuvent tous être des dimensions dans la matrice de shaders, et la taille de cette matrice peut croître assez rapidement. Il peut également être utile de réduire le nombre de changements d’états de rendu.
Des courbes de décroissance arbitraires peuvent être encodées dans les cartes de gobo et de décroissance. Nous ne sommes pas limités à l’atténuation linéaire ou en carré inverse du monde réel.
En raison de la capacité à contrôler la décroissance, la boîte englobante qui contient le volume d’éclairage peut généralement être relativement serrée par rapport aux spots et lumières omni traditionnels. En d’autres termes, un grand pourcentage du volume dans la boîte reçoit un éclairage significatif, et la lumière décroît plus rapidement que pour les modèles traditionnels, donc le volume est aussi petit et serré que possible. En regardant la rangée du bas de la Figure 10.33, comparez la taille de la boîte nécessaire pour contenir le vrai spot, par rapport au faux spot.
C’est peut-être la caractéristique la plus importante derrière l’introduction de ces types de lumières dans Doom 3, qui utilisait une technique de rendu accumulé sans lightmaps ni éclairage précalculé ; chaque objet était entièrement éclairé en temps réel. Chaque lumière était ajoutée dans la scène en re-rendant la géométrie dans le volume de la lumière et en ajoutant la contribution de la lumière dans le frame buffer. Limiter la quantité de géométrie qui devait être redessinée (ainsi que la géométrie qui devait être traitée pour les ombres stencil qui étaient utilisées) était un énorme gain de performances.
10.7.4Éclairage précalculé
L’une des plus grandes sources d’erreur dans les images produites en temps réel (ceux d’entre vous qui pensent positivement pourraient dire la plus grande opportunité d’amélioration) est l’éclairage indirect : la lumière qui a « rebondi » au moins une fois avant d’illuminer le pixel en cours de rendu. Il s’agit d’un problème extrêmement difficile. Une première étape importante pour le rendre tractable est de décomposer les surfaces de la scène en patches discrets ou points d’échantillonnage. Mais même avec un nombre relativement modeste de patches, nous devons encore déterminer quels patches peuvent « se voir » et ont un conduit de radiance, et lesquels ne peuvent pas se voir et n’échangent pas de radiance. Puis nous devons résoudre pour l’équilibre de la lumière dans l’équation de rendu. De plus, lorsqu’un objet quelconque se déplace, il peut potentiellement modifier quels patches peuvent voir lesquels. En d’autres termes, pratiquement tout changement modifiera la distribution de la lumière dans toute la scène.
Cependant, il est généralement le cas que certaines lumières et certaine géométrie dans la scène ne sont pas en mouvement. Dans ce cas, nous pouvons effectuer des calculs d’éclairage plus détaillés (résoudre l’équation de rendu plus complètement), puis utiliser ces résultats, en ignorant toute erreur qui résulte de la différence entre la configuration d’éclairage actuelle et celle qui a été utilisée lors des calculs hors- ligne. Considérons plusieurs exemples de ce principe de base.
Une technique est le lightmapping. Dans ce cas, un canal UV supplémentaire est utilisé pour arranger les polygones de la scène dans une carte de texture spéciale qui contient des informations d’éclairage précalculées. Ce processus de trouver un bon moyen d’arranger les polygones dans la carte de texture est souvent appelé atlasing. Dans ce cas, les « patches » discrets que nous avons mentionnés précédemment sont les texels de la lightmap. Le lightmapping fonctionne bien sur de grandes surfaces planes, comme les sols et les plafonds, qui sont relativement faciles à arranger efficacement dans la lightmap. Mais les maillages plus denses, comme les escaliers, les statues, les machines et les arbres, qui ont une topologie beaucoup plus complexe, ne sont pas aussi facilement mis en atlas. Heureusement, nous pouvons tout aussi facilement stocker des valeurs d’éclairage précalculées dans les vertices, ce qui fonctionne souvent mieux pour les maillages relativement denses.
Qu’est-ce exactement que l’information précalculée stockée dans les lightmaps (ou les vertices) ? Essentiellement, nous stockons l’illumination incidente, mais il y a beaucoup d’options. Une option est le nombre d’échantillons par patch. Si nous n’avons qu’une seule lightmap ou couleur de vertex, alors nous ne pouvons pas tenir compte de la distribution directionnelle de cette illumination incidente et devons simplement utiliser la somme sur tout l’hémisphère. (Comme nous l’avons montré dans la Section 10.1.3, cette quantité « sans direction », la puissance radiante incidente par unité de surface, est correctement connue sous le nom de radiosité, et pour des raisons historiques, les algorithmes pour calculer les lightmaps sont parfois confusément connus comme des techniques de radiosité, même si les lightmaps incluent une composante directionnelle.) Si nous pouvons nous permettre plus d’une lightmap ou couleur de vertex, alors nous pouvons capturer la distribution plus précisément. Cette information directionnelle est ensuite projetée sur une base particulière. Nous pourrions avoir chaque base correspondant à une seule direction. Une technique connue sous le nom d’harmoniques sphériques [24][15] utilise des fonctions de base sinusoïdales similaires aux techniques de Fourier 2D. Le point dans tous les cas est que la distribution directionnelle de la lumière incidente est importante, mais lors de la sauvegarde d’informations de lumière incidente précalculées, nous sommes généralement forcés de supprimer ou de compresser ces informations.
Une autre option est de savoir si l’illumination précalculée comprend l’éclairage direct, indirect ou les deux. Cette décision peut souvent être prise sur la base de chaque lumière. Les premiers exemples de lightmapping calculaient simplement la lumière directe de chaque lumière dans la scène pour chaque patch. L’avantage principal de cela était qu’il permettait des ombres, qui à l’époque étaient d’un coût prohibitif à produire en temps réel. (La même idée de base est encore utile aujourd’hui, seulement maintenant l’objectif est généralement de réduire le nombre total d’ombres en temps réel qui doivent être générées.) Ensuite, la vue pouvait être déplacée en temps réel, mais évidemment, toutes les lumières qui avaient été gravées dans les lightmaps ne pouvaient pas se déplacer, et si une géométrie se déplaçait, les ombres y seraient « collées » et l’illusion se briserait. Un système d’exécution identique peut être utilisé pour rendre des lightmaps qui incluent également l’éclairage indirect, bien que les calculs hors-ligne nécessitent beaucoup plus de finesse. Il est possible que certaines lumières aient à la fois leur éclairage direct et indirect cuits dans les lightmaps, tandis que d’autres lumières n’ont que la partie indirecte incluse dans l’éclairage précalculé et l’éclairage direct effectué à l’exécution. Cela pourrait offrir des avantages, comme des ombres avec une précision supérieure à la densité de texels de la lightmap, des reflets spéculaires améliorés en raison de la modélisation correcte de la direction d’incidence (qui est perdue lorsque la lumière est gravée dans les lightmaps), ou une capacité limitée à ajuster dynamiquement l’intensité de la lumière ou à l’éteindre ou à changer sa position. Bien sûr, la présence d’éclairage précalculé pour certaines lumières n’empêche pas l’utilisation de techniques entièrement dynamiques pour d’autres lumières.
Les techniques de lightmapping discutées ici fonctionnent bien pour la géométrie statique, mais qu’en est-il des objets dynamiques tels que les personnages, les véhicules, les plateformes et les éléments ? Ceux-ci doivent être éclairés dynamiquement, ce qui rend l’inclusion de l’éclairage indirect difficile. Une technique, popularisée par Half Life 2 de Valve [10][16], consiste à placer stratégiquement des sondes lumineuses à divers emplacements dans la scène. À chaque sonde, nous rendons une carte d’environnement cubique hors-ligne. Lors du rendu d’un objet dynamique, nous localisons la sonde voisine la plus proche et utilisons cette sonde pour obtenir un éclairage indirect localisé. Il existe de nombreuses variantes de cette technique — par exemple, nous pourrions utiliser une carte d’environnement pour la réflexion diffuse de la lumière indirecte, où chaque échantillon est pré-filtré pour contenir tout l’hémisphère pondéré par le cosinus entourant cette direction, et une carte cubique différente pour la réflexion spéculaire de la lumière indirecte, qui n’a pas ce filtrage.
10.8Animation squelettique
L’animation de créatures humaines est certainement d’une grande importance dans les jeux vidéo et dans les graphismes informatiques en général. L’une des techniques les plus importantes pour animer les personnages est l’animation squelettique, bien qu’elle ne soit certainement pas limitée à cet usage. La manière la plus facile d’apprécier l’animation squelettique est de la comparer aux autres alternatives, donc revoyons d’abord celles-ci.
Disons que nous avons créé un modèle d’une créature humanoïde comme un robot. Comment l’animons-nous ? Certainement, nous pourrions le traiter comme une pièce d’échecs et le déplacer comme une boîte de sandwichs au hareng réchauffable ou n’importe quel autre objet solide — ce n’est évidemment pas très convaincant. Les créatures sont articulées, ce qui signifie qu’elles sont composées de parties connectées et mobiles. La méthode la plus simple pour animer une créature articulée est de décomposer le modèle en une hiérarchie de parties connectées — avant-bras gauche, bras gauche supérieur, cuisse gauche, tibia gauche, pied gauche, torse, tête, etc. — et d’animer cette hiérarchie. Un premier exemple de cela était le clip vidéo Money for Nothing de Dire Straits. Les exemples plus récents incluent pratiquement tous les jeux PlayStation 2, comme le premier Tomb Raider. La caractéristique commune ici est que chaque partie est encore rigide ; elle ne se plie pas ni ne se fléchit. Ainsi, peu importe à quel point le personnage est habilement animé, il ressemble toujours à un robot.
L’idée derrière l’animation squelettique est de remplacer la hiérarchie de parties par une hiérarchie imaginaire d’os. Ensuite, chaque vertex du modèle est associé à un ou plusieurs os, dont chacun exerce une influence sur le vertex mais ne détermine pas totalement sa position. Si un vertex est associé à un seul os, il maintiendra un décalage fixe par rapport à cet os. Un tel vertex est connu sous le nom de vertex rigide, et ce vertex se comporte exactement comme n’importe quel vertex du premier modèle Laura Croft. Cependant, plus généralement, un vertex recevra une influence de plus d’un os. Un artiste doit spécifier quels os influencent quels vertices. Ce processus est connu sous le nom de skinning,18 et un modèle ainsi annoté est connu sous le nom de modèle skinné. Lorsque plus d’un os influence un vertex, l’animateur peut distribuer, par vertex, des quantités d’influence différentes à chaque os. Comme vous pouvez l’imaginer, cela peut être très laborieux. Des outils automatisés existent qui peuvent fournir un premier passage rapide sur les poids de peau, mais un personnage bien skinnéé nécessite expertise et temps.
Pour déterminer la position animée d’un vertex, nous itérons sur tous les os qui exercent une influence sur le vertex, et calculons la position que le vertex aurait s’il était rigide par rapport à cet os. La position finale du vertex est ensuite prise comme la moyenne pondérée de ces positions.
Regardons un exemple. La Figure 10.34 montre deux exemples de vertices skinnés près du coude d’un robot. Les points bleus et verts montrent à quoi ressemblerait un vertex s’il était rigide par rapport à l’os correspondant, et le point cyan est le vertex skinné ; remarquez qu’il reste attaché à la surface du maillage.
Figure 10.34Deux vertices skinnés
Le vertex à droite, plus proche de l’épaule, est influencé à approximativement 60% par l’os du bras supérieur et à 40% par l’os de l’avant-bras. Vous pouvez voir qu’à mesure que le bras se plie, ce vertex reste plus proche du vertex rigide bleu. En revanche, le vertex plus proche de la main semble être influencé à approximativement 80% par l’os de l’avant-bras et seulement à 20% par l’os du bras supérieur, et reste donc plus proche de son vertex rigide vert.
Donc une stratégie simple pour implémenter l’animation squelettique pourrait être la suivante. Pour chaque vertex, nous gardons une liste d’os qui influencent le vertex. Généralement, nous définissons une limite sur le nombre d’os qui peuvent influencer un seul vertex (quatre est un nombre courant). Pour chaque os, nous connaissons la position du vertex par rapport aux axes locaux de l’os, et nous avons un poids pour cet os. Pour calculer les positions de vertex skinnées pour un modèle dans une pose arbitraire, nous avons besoin d’une matrice de transformation pour chaque os qui indique comment convertir de l’espace de coordonnées de l’os en espace de coordonnées de modélisation. Faire varier ces matrices de transformation dans le temps est ce qui fait que le personnage semble s’animer.
Le Listing 10.7 illustre cette technique de base. Notez que nous prévoyons également en incluant les normales de vertex. Celles-ci sont gérées de la même façon que les positions de vertex, sauf que nous supprimons la partie de translation de la matrice. En théorie, la même matrice ne devrait pas être utilisée pour transformer les positions et les normales. Rappelez-vous que si une mise à l’échelle non uniforme ou un cisaillement est inclus dans la matrice, nous devrions vraiment utiliser la matrice transposée inverse, comme cela a été discuté dans la Section 10.4.2. En pratique, cependant, calculer et envoyer deux ensembles de matrices au GPU est trop coûteux, donc par souci d’efficacité cette erreur est ignorée, ou la mise à l’échelle non uniforme est simplement évitée. (La mise à l’échelle uniforme est généralement acceptable car les normales doivent de toute façon être renormalisées.) Les vecteurs de base pour le bump mapping font également couramment partie du processus, mais ils sont gérés d’une manière très similaire aux normales, donc nous les laisserons de côté pour l’instant.
// Limite du nombre max d'os pouvant influencer un vertex
const int kMaxBonesPerVertex = 4;
// Décrit un vertex dans un modèle squelettique
struct SkinnedVertex {
// Nombre d'os qui influencent ce vertex
int boneCount;
// Quels os influencent le vertex ? Ce sont des indices
// dans une liste d'os.
int boneIndex[kMaxBonesPerVertex];
// Poids des os. Leur somme doit valoir 1
float boneWeight[kMaxBonesPerVertex];
// Position et normale du vertex, dans l'espace de l'os
Vector3 posInBoneSpace[kMaxBonesPerVertex];
Vector3 normalInBoneSpace[kMaxBonesPerVertex];
};
// Décrit un vertex tel qu'on l'utilisera pour le rendu
struct Vertex {
Vector3 pos;
Vector3 normal;
};
// Calcule les positions et normales de vertices skinnés.
void computeSkinnedVertices(
int vertexCount, // nombre de verts à skinner
const SkinnedVertex *inSkinVertList, // liste de verts en entrée
const Matrix4x3 *boneToModelList, // Position/orientation de chaque os
Vertex *outVertList // sortie ici
) {
// Itérer sur tous les vertices
for (int i = 0 ; i < vertexCount ; ++i) {
const SkinnedVertex &s = inSkinVertList[i];
Vertex &d = outVertList[i];
// Boucler sur tous les os qui influencent ce vertex, et
// calculer la moyenne pondérée
d.pos.zero();
d.normal.zero();
for (int j = 0 ; j < s.boneCount ; ++j) {
// Localiser la matrice de transformation
const Matrix4x3 &boneToModel
= boneToModelList[s.boneIndex[j]];
// Transformer de l'espace os vers l'espace modèle (en utilisant
// l'opérateur vecteur * matrice surchargé qui fait la
// multiplication matricielle), et additionner la contribution
// de cet os
d.pos += s.posInBoneSpace[j] * boneToModel
* s.boneWeight[j];
// *Faire pivoter* le vertex dans l'espace corps, en ignorant
// la partie de translation de la transformation affine.
// La normale est un "vecteur" et non un "point", donc elle
// n'est pas translatée.
d.normal += boneToModel.rotate(s.normalInBoneSpace[j])
* s.boneWeight[j];
}
// S'assurer que la normale est normalisée
d.normal.normalize();
}
}Comme tous les extraits de code de ce livre, le but de ce code est d’expliquer les principes, pas de montrer comment les choses sont optimisées en pratique. En réalité, les calculs de skinning montrés ici sont généralement effectués dans le matériel dans un vertex shader ; nous montrerons comment cela est fait dans la Section 10.11.5. Mais il y a encore beaucoup plus de théorie dont on peut parler, alors restons à un niveau élevé. Il s’avère que la technique qui vient d’être présentée est facile à comprendre, mais il y a une optimisation importante de haut niveau. En pratique, une technique légèrement différente est utilisée.
Nous arriverons à l’optimisation dans un moment, mais d’abord, revenons en arrière et demandons-nous d’où viennent les coordonnées dans l’espace os (les variables membres nommées posInBoneSpace et normalInBoneSpace dans le Listing 10.7) en premier lieu. « C’est facile, » pourriez-vous dire, « nous les exportons directement depuis Maya ! » Mais comment Maya les a-t-il déterminées ? La réponse est qu’elles viennent de la pose de liaison. La pose de liaison (parfois appelée la pose de repos) décrit une orientation des os dans une position par défaut. Quand un artiste crée un maillage de personnage, il commence par construire un maillage sans aucun os ni données de skinning, comme n’importe quel autre modèle. Pendant ce processus, il construit le personnage posé dans la pose de liaison. La Figure 10.35 montre notre modèle skinné dans sa pose de liaison, ainsi que le squelette utilisé pour l’animer. Rappelez-vous que les os sont vraiment juste des espaces de coordonnées et n’ont aucune géométrie réelle. La géométrie que vous voyez existe uniquement comme aide à la visualisation.


Figure 10.35Le modèle robot dans la pose de liaison (gauche), et les os utilisés pour animer le modèle (droite)
Quand le maillage est terminé,19 il est rigué, ce qui signifie qu’une hiérarchie d’os (un squelette) est créée et que les données de skinning sont éditées pour associer les vertices aux os appropriés. Pendant ce processus, le truqueur va plier les os à diverses angles extrêmes pour prévisualiser comment le modèle réagit à ces contorsions. La pondération est-elle faite correctement pour que les articulations ne s’effondrent pas ? C’est là qu’entrent en jeu la compétence et l’expérience à la fois du modéliste de personnage et du truqueur. Pour nous, le point est que bien que Maya calcule constamment de nouvelles positions de vertex en réponse à la manipulation des os, il a sauvegardé les coordonnées originales de l’espace de modélisation de chaque vertex à l’emplacement qu’il avait dans la pose de liaison, avant qu’il soit attaché à un squelette. Tout commence avec cette position de vertex originale.
Donc, pour calculer les coordonnées dans l’espace os d’un vertex, nous commençons avec les coordonnées de l’espace de modélisation de ce vertex dans la pose de liaison. Nous connaissons aussi la position et l’orientation de chaque os dans la pose de liaison. Nous transformons simplement les positions de vertex de l’espace de modélisation vers l’espace os en fonction de ces positions et orientations.
Voilà la grande vue d’ensemble du skinning de maillage, en principe. Venons-en maintenant à l’optimisation. L’idée de base est de stocker la position de chaque vertex uniquement dans la pose de liaison, plutôt que de la stocker par rapport à chaque os qui exerce une influence. Ensuite, lors du rendu d’un maillage, plutôt que d’avoir une transformation d’os vers modèle pour chaque os, nous avons une matrice qui transforme les coordonnées de l’espace de liaison original vers l’espace de modélisation dans la pose actuelle. En d’autres termes, cette matrice décrit la différence entre l’orientation de l’os dans la pose de liaison et l’orientation actuelle de l’os dans la pose actuelle. Cela est montré dans le Listing 10.8.
// Limite du nombre max d'os pouvant influencer un vertex
const int kMaxBonesPerVertex = 4;
// Décrit un vertex dans un modèle squelettique
struct SkinnedVertex {
// Nombre d'os qui influencent ce vertex
int boneCount;
// Quels os influencent le vertex ? Ce sont des indices
// dans une liste d'os.
int boneIndex[kMaxBonesPerVertex];
// Poids des os. Leur somme doit valoir 1
float boneWeight[kMaxBonesPerVertex];
// Position et normale du vertex dans la pose de liaison,
// en espace modèle
Vector3 pos;
Vector3 normal;
};
// Décrit un vertex tel qu'on l'utilisera pour le rendu
struct Vertex {
Vector3 pos;
Vector3 normal;
};
// Calcule les positions et normales de vertices skinnés.
void computeSkinnedVertices(
int vertexCount, // nombre de verts à skinner
const SkinnedVertex *inSkinVertList, // liste de verts en entrée
const Matrix4x3 *boneTransformList, // De la pose de liaison vers la pose actuelle
Vertex *outVertList // sortie ici
) {
// Itérer sur tous les vertices
for (int i = 0 ; i < vertexCount ; ++i) {
const SkinnedVertex &s = inSkinVertList[i];
Vertex &d = outVertList[i];
// Boucler sur tous les os qui influencent ce vertex, et calculer
// une *matrice* mélangée pour ce vertex
Matrix4x3 blendedMat;
blendedMat.zero();
for (int j = 0 ; j < s.boneCount ; ++j) {
blendedMat += boneTransformList[s.boneIndex[j]]
* s.boneWeight[j];
}
// Transformer la position et la normale à l'aide de la matrice mélangée
d.pos = s.pos * blendedMat;
d.normal = blendedMat.rotate(s.normal);
// S'assurer que la normale est normalisée
d.normal.normalize();
}
}Cela produit une réduction significative de la bande passante vers le GPU (due à la diminution de sizeof(SkinnedVertex)), ainsi qu’une réduction du calcul par vertex, surtout lorsque des vecteurs de base sont présents. Il nécessite juste un peu plus de manipulation des matrices avant de les transmettre au GPU.
Nous avons présenté l’idée de base derrière le skinning simple. Certainement, dans des situations où les ressources de calcul (et les ressources humaines !) sont disponibles et méritent d’être dépensées pour produire les personnages de la plus haute fidélité possible, comme dans les jeux de combat ou de sport, des techniques plus avancées peuvent être employées. Par exemple, nous pourrions vouloir faire bomber le biceps lorsque le bras se plie vers le haut, ou écraser la chair d’un pied de dinosaure lorsque le poids est transféré et que le pied est pressé plus fort dans le sol.
10.9Placage de relief (Bump Mapping)
La première utilisation du placage de texture en infographie était de définir la couleur d’un objet. Mais le placage de texture peut être utilisé quand nous voulons spécifier n’importe quelle propriété de surface avec plus de granularité qu’au niveau du vertex. La propriété de surface particulière qui est peut-être la plus proche du contrôle de sa « texture », au sens que la plupart des non-initiés comprendraient, est en fait la normale de surface.
Le bump mapping est un terme général qui peut faire référence à au moins deux méthodes différentes de contrôle de la normale de surface par texel. Une carte de hauteur est une carte en niveaux de gris, dans laquelle l’intensité indique l’« élévation » locale de la surface. Les couleurs plus claires indiquent les parties de la surface qui sont « relevées », et les couleurs plus sombres sont les zones où la surface est « enfoncée ». Les cartes de hauteur sont attrayantes car elles sont très faciles à créer, mais elles ne sont pas idéales pour les besoins en temps réel car la normale n’est pas directement disponible ; au lieu de cela, elle doit être calculée à partir du gradient d’intensité. Nous nous concentrons ici sur la technique du normal mapping, qui est très courante de nos jours et ce que la plupart des gens entendent généralement quand ils disent « bump map ».
Dans une carte de normales, les coordonnées de la normale de surface sont directement encodées dans la carte. La manière la plus basique est d’encoder , et respectivement dans les canaux rouge, vert et bleu, bien que certains matériels supportent des formats plus optimisés. Les valeurs sont généralement mises à l’échelle, biaisées et quantifiées de sorte qu’une valeur de coordonnée de soit encodée comme 0, et soit encodée en utilisant la valeur de couleur maximale (généralement 255). Maintenant, en principe, utiliser une carte de normales est simple. Dans notre calcul d’éclairage, plutôt que d’utiliser le résultat de l’interpolation des normales de vertex, nous récupérons une normale de la carte de normales et l’utilisons à la place. Voilà ! Ah, si seulement c’était aussi simple…
Des complications surgissent pour deux raisons principales. Premièrement, les cartes de normales ne sont pas intuitives à éditer. Alors qu’une carte de hauteur (ou une vraie carte de déplacement) peut facilement être peinte dans Photoshop, les cartes de normales ne sont pas si facilement visualisées et éditées. Les opérations de couper-coller sur les cartes de normales sont généralement sûres, mais pour que la carte de normales soit valide, chaque pixel devrait encoder un vecteur normalisé. La technique habituelle pour créer une carte de normales est qu’un artiste modélise réellement une version basse et haute résolution du maillage. Le maillage basse résolution est celui réellement utilisé à l’exécution, et le maillage haute résolution sert uniquement à créer la carte de relief,20 en utilisant un outil automatisé qui trace des rayons contre le maillage de plus haute résolution pour déterminer la normale de surface pour chaque texel de la carte de normales.
Le problème plus délicat est que la mémoire de texture est une ressource précieuse.21 Dans certains cas simples, chaque texel de la carte de normales est utilisé au plus une fois sur la surface du maillage. Dans ce cas, nous pourrions simplement encoder la normale dans l’espace objet, et notre description précédente fonctionnerait très bien. Mais les objets du monde réel présentent beaucoup de symétrie et d’auto-similarité, et les motifs sont souvent répétés. Par exemple, une boîte a souvent des bosses et encoches similaires sur plus d’un côté. Pour cette raison, il est actuellement une utilisation plus efficace de la même quantité de mémoire (et du temps de l’artiste) d’augmenter la résolution de la carte et de réutiliser la même carte de normales (ou peut-être juste des portions de celle-ci) sur plusieurs modèles (ou peut-être juste en plusieurs endroits dans le même modèle). Bien sûr, le même principe s’applique à tout type de carte de texture, pas seulement aux cartes de normales. Mais les cartes de normales sont différentes en ce qu’elles ne peuvent pas être arbitrairement pivotées ou inversées car elles encodent un vecteur. Imaginez utiliser la même carte de normales sur les six côtés d’un cube. Lors de l’ombrage d’un point sur la surface du cube, nous récupérons un texel de la carte et le décodons en un vecteur 3D. Un texel particulier de la carte de normales sur le dessus produira une normale de surface qui pointe dans la même direction que ce même texel sur le bas du cube, alors qu’ils devraient être opposés ! Nous avons besoin d’un autre type d’information pour nous dire comment interpréter la normale que nous obtenons de la texture, et ce bit d’information supplémentaire est stocké dans les vecteurs de base.
10.9.1L’espace tangent
La technique la plus courante de nos jours est que la normale encodée dans la carte utilise des coordonnées dans l’espace tangent. Dans l’espace tangent, pointe à l’extérieur de la surface ; le vecteur de base est en fait juste la normale de surface . Le vecteur de base est connu sous le nom de vecteur tangent, que nous noterons , et il pointe dans la direction de croissant dans l’espace de texture. En d’autres termes, quand nous nous déplaçons dans la direction du vecteur tangent en 3D, cela correspond à se déplacer vers la droite en 2D dans la carte de normales. (Souvent, la carte de relief partage les mêmes coordonnées UV que d’autres cartes, mais si elles diffèrent, ce sont les coordonnées utilisées pour le bump mapping qui comptent.) De même, le vecteur de base , connu sous le nom de binormale22 et noté ici comme , correspond à la direction de croissant, bien que si ce mouvement est « vers le haut » ou « vers le bas » dans l’espace de texture dépende des conventions pour l’origine dans l’espace , qui peuvent différer, comme nous l’avons discuté précédemment. Bien sûr, les coordonnées pour le tangent et la binormale sont données dans l’espace modèle, tout comme la normale de surface. Comme l’impliquent les chapeaux sur les variables, les vecteurs de base sont généralement stockés comme des vecteurs unitaires.
Par exemple, supposons qu’un certain texel d’une carte de normales ait le triplet RGB , qui est décodé vers le vecteur unitaire . Nous interprétons cela comme signifiant que la normale de surface locale pointe à environ un angle de par rapport à une normale de surface « plate » définie par la normale de vertex interpolée. Elle pointe « vers la gauche », où « gauche » est significatif dans l’espace image de la carte de normales et signifie vraiment « dans la direction de décroissant ».
En résumé, le tangent, la binormale et la normale sont les axes d’un espace de coordonnées connu sous le nom d’espace tangent, et les coordonnées de la normale par texel sont interprétées en utilisant cet espace de coordonnées. Pour obtenir la normale dans l’espace modèle à partir d’une normale dans l’espace tangent, nous décodons d’abord la normale de la carte puis la transformons dans l’espace modèle comme tout autre vecteur. Soit la normale de surface dans l’espace tangent et la normale de surface dans l’espace modèle. Nous pouvons déterminer simplement en prenant la combinaison linéaire des vecteurs de base
À présent, nous savons que c’est la même chose que multiplier par une matrice dont les rangées sont les vecteurs de base :
Rappelons que le maillage polygonal est juste une approximation pour une surface potentiellement courbée, donc la normale de surface que nous utilisons pour l’éclairage varie continûment sur chaque face afin d’approximer la vraie normale de surface. De la même façon, les vecteurs de base tangent et binormale varient aussi continûment sur le maillage, car ils doivent être perpendiculaires à la normale de surface et tangents à la surface approximée. Mais même sur une surface plane, les vecteurs de base peuvent changer sur la surface si une texture est écrasée, comprimée ou tordue. Deux exemples instructifs peuvent être trouvés dans la Figure 10.19. Le côté gauche montre un exemple d’« écrasement ». Dans ce cas, le vecteur tangent pointerait vers la droite, parallèle aux arêtes horizontales du polygone, tandis que la binormale serait localement parallèle aux arêtes verticales (courbes) du polygone à chaque vertex. Pour déterminer les vecteurs de base en tout point donné à l’intérieur de la face, nous interpolons les vecteurs de base des vertices, tout comme nous le faisons avec la normale de surface. Comparez cela avec le placage de texture sur le côté droit, où le placage de texture est planaire. Dans cet exemple, la binormale à chaque vertex (et à chaque point intérieur) pointe directement vers le bas.
Notez que dans le placage de texture utilisé sur le côté gauche de la figure, les vecteurs tangent et binormale ne sont pas perpendiculaires. Malgré cette possibilité, il est courant de supposer que les vecteurs de base forment une base orthonormale (ou de les ajuster pour qu’ils le fassent), même si la texture est maltraitée. Nous faisons cette hypothèse pour faciliter deux optimisations. La première optimisation est que nous pouvons effectuer nos calculs d’éclairage dans l’espace tangent plutôt que dans l’espace modèle. Si nous faisons l’éclairage dans l’espace modèle, nous devons interpoler les trois vecteurs de base sur la face, et ensuite dans le pixel shader nous devons transformer notre normale dans l’espace tangent vers l’espace modèle. Quand nous faisons l’éclairage dans l’espace tangent, cependant, nous pouvons à la place transformer les vecteurs nécessaires pour l’éclairage ( et ) vers l’espace tangent une fois dans le vertex shader, puis pendant la rastérisation, l’interpolation est effectuée dans l’espace tangent. Dans de nombreuses circonstances, c’est plus rapide. Si nous avons une base orthonormale, alors l’inverse de la matrice de transformation est simplement sa transposée, et nous pouvons transformer de l’espace modèle vers l’espace tangent juste en utilisant le produit scalaire. (Si cela n’est pas clair, voir la Section 3.3.3 et la Section 6.3.) Bien sûr, nous sommes libres de faire pivoter des vecteurs dans l’espace tangent en utilisant le produit scalaire même si notre base n’est pas orthonormale ; en fait, après avoir interpolé les vecteurs de base et les avoir renormalisés, il est probable qu’ils soient légèrement hors d’orthogonalité. Dans ce cas, notre transformation n’est pas complètement correcte, mais cela ne cause généralement aucun problème. Il est important de se rappeler que toute l’idée d’interpoler les normales de surface et les vecteurs de base est une approximation dès le départ.
La deuxième optimisation que nous pouvons faire en supposant des vecteurs de base perpendiculaires est d’éviter complètement de stocker l’un des deux vecteurs de base (généralement nous abandonnons la binormale) et de le calculer à la volée. Cela peut être plus rapide lorsque le goulot d’étranglement des performances est le déplacement de mémoire plutôt que les calculs par vertex. Il y a juste une complication : les cartes de relief inversées. Il est très courant sur les objets symétriques que les cartes de texture, y compris la carte de relief, soient utilisées deux fois ; d’un côté de la façon « normale », et inversées de l’autre côté. Essentiellement, nous devons savoir si la texture est appliquée dans son orientation normale ou inversée. Cela est fait en stockant un indicateur qui indique si la texture est inversée. Une valeur de indique l’orientation habituelle, et indique l’état inversé. Il est courant de ranger commodément cet indicateur dans la composante du vecteur de base que nous conservons. Maintenant, quand nous devons calculer le vecteur de base abandonné, nous prenons le produit croisé approprié (par exemple ), puis multiplions par notre indicateur pour inverser le vecteur de base si nécessaire. Cet indicateur est calculé par le produit triple , qui est la même chose que le déterminant de la matrice de transformation dans l’Équation (10.18).
10.9.2Calcul des vecteurs de base de l’espace tangent
Enfin, parlons de la façon de calculer les vecteurs de base. Notre développement suit Lengyel [14]. On nous donne un triangle avec des positions de vertex , , et , et à ces vertices nous avons les coordonnées UV , , et . Dans ces circonstances, il est toujours possible de trouver un mappage planaire, ce qui signifie que le gradient du mappage est constant sur tout le triangle.
En anticipant, les maths seront simplifiées si nous décalons l’origine vers en introduisant
Nous cherchons des vecteurs de base qui se trouvent dans le plan du triangle, et nous pouvons donc exprimer les vecteurs d’arête du triangle et comme une combinaison linéaire des vecteurs de base, où les déplacements et connus sur ces arêtes sont les coordonnées :
La normalisation de et produit les vecteurs unitaires que nous cherchons. Nous pouvons écrire ces équations plus compactement en notation matricielle comme
d’où une solution élégante se présente. En multipliant les deux membres par l’inverse de la matrice à gauche, nous obtenons
Puisque nous prévoyons de normaliser nos vecteurs de base, nous pouvons ignorer la fraction constante en tête, et il reste
Cela nous donne des vecteurs de base pour chaque triangle. Il n’est pas garanti qu’ils soient perpendiculaires, mais ils sont utilisables pour notre objectif principal : déterminer les vecteurs de base au niveau du vertex. Ceux-ci peuvent être calculés en utilisant une astuce similaire au calcul des normales de vertex : pour chaque vertex, nous prenons la moyenne des vecteurs de base des triangles adjacents. Nous appliquons également généralement une base orthonormale. Cela se fait le plus simplement par l’orthogonalisation de Gram-Schmidt (Section 6.3.3). De plus, si nous abandonnons l’un des vecteurs de base, c’est ici que nous devons sauvegarder le déterminant de la base. Le Listing 10.9 montre comment nous pourrions calculer les vecteurs de base des vertices.
struct Vertex {
Vector3 pos;
float u,v;
Vector3 normal;
Vector3 tangent;
float det; // déterminant de la transformation tangente. (-1 si inversé)
};
struct Triangle {
int vertexIndex[3];
};
struct TriangleMesh {
int vertexCount;
Vertex *vertexList;
int triangleCount;
Triangle *triangleList;
void computeBasisVectors() {
// Remarque : on suppose que les normales de vertex sont valides
Vector3 *tempTangent = new Vector3[vertexCount];
Vector3 *tempBinormal = new Vector3[vertexCount];
// D'abord, effacer les accumulateurs
for (int i = 0 ; i < vertexCount ; ++i) {
tempTangent[i].zero();
tempBinormal[i].zero();
}
// Faire la moyenne des vecteurs de base pour chaque face
// dans ses vertices voisins
for (int i = 0 ; i < triangleCount ; ++i) {
// Obtenir des raccourcis
const Triangle &tri = triangleList[i];
const Vertex &v0 = vertexList[tri.vertexIndex[0]];
const Vertex &v1 = vertexList[tri.vertexIndex[1]];
const Vertex &v2 = vertexList[tri.vertexIndex[2]];
// Calculer les valeurs intermédiaires
Vector3 q1 = v1.pos - v0.pos;
Vector3 q2 = v2.pos - v0.pos;
float s1 = v1.u - v0.u;
float s2 = v2.u - v0.u;
float t1 = v1.v - v0.v;
float t2 = v2.v - v0.v;
// Calculer les vecteurs de base pour ce triangle
Vector3 tangent = t2*q1 - t1*q2; tangent.normalize();
Vector3 binormal = -s2*q1 + s1*q2; binormal.normalize();
// Les ajouter aux totaux courants pour les verts voisins
for (int j = 0 ; j < 3 ; ++j) {
tempTangent[tri.vertexIndex[j]] += tangent;
tempBinormal[tri.vertexIndex[j]] += binormal;
}
}
// Maintenant remplir les valeurs dans les vertices
for (int i = 0 ; i < vertexCount ; ++i) {
Vertex &v = vertexList[i];
Vector3 t = tempTangent[i];
// S'assurer que le tangent est perpendiculaire à la normale.
// (Gram-Schmidt), puis conserver la version normalisée
t -= v.normal * dot(t, v.normal);
t.normalize();
v.tangent = t;
// Déterminer si nous sommes inversés
if (dot(cross(v.normal, t), tempBinormal[i]) < 0.0f) {
v.det = -1.0f; // nous sommes inversés
} else {
v.det = +1.0f; // non inversé
}
}
// Nettoyer
delete[] tempTangent;
delete[] tempBinormal;
}
};Une complication irritante que le Listing 10.9 n’aborde pas est qu’il peut y avoir une discontinuité dans le mappage, où les vecteurs de base ne devraient pas être moyennés ensemble, et les vecteurs de base doivent être différents d’une arête partagée. La plupart du temps, les faces auront déjà été détachées les unes des autres (les vertices seront dupliqués) le long d’une telle arête, car les coordonnées UV ou les normales ne correspondront pas. Malheureusement, il y a un cas particulièrement courant où ce n’est pas vrai : les textures inversées sur des objets symétriques. Par exemple, il est courant pour les modèles de personnages et d’autres maillages symétriques d’avoir une ligne au centre, de l’autre côté de laquelle la texture a été inversée. Les vertices le long de cette couture nécessitent souvent des UV identiques mais un ou opposé. Ces vertices doivent être détachés afin d’éviter de produire des vecteurs de base invalides le long de cette couture.
La Section 10.11.4 montre du code de shader qui utilise réellement les vecteurs de base pour effectuer le bump mapping. Le code d’exécution est étonnamment simple, une fois que toutes les données ont été transformées au bon format. Cela illustre un thème commun dans les graphismes en temps réel contemporains : au moins 75% du code se trouve dans les outils qui manipulent les données — les optimisant, les compressant et les manipulant d’une autre façon dans exactement le bon format — afin que le code d’exécution (les autres 25%) puisse s’exécuter aussi rapidement que possible.
10.10Le pipeline graphique en temps réel
L’équation de rendu est la façon correcte de produire des images, en supposant que vous disposez d’une puissance de calcul infinie. Mais si vous voulez produire des images dans le monde réel sur un vrai ordinateur, vous devez comprendre les compromis contemporains qui sont faits. Le reste de ce chapitre est plus axé sur ces techniques, en tentant de décrire un pipeline graphique en temps réel simple typique, circa 2010. Après avoir donné un aperçu du pipeline graphique, nous descendons ensuite ce pipeline et discutons de chaque section plus en détail, en nous arrêtant en chemin pour nous concentrer sur certaines idées mathématiques clés. Le lecteur de cette section doit être conscient de plusieurs lacunes sérieuses dans cette discussion :
Il n’existe pas de pipeline graphique moderne « typique ». Le nombre de différentes stratégies de rendu est égal au nombre de programmeurs graphiques. Chacun a ses propres préférences, astuces et optimisations. Le matériel graphique continue d’évoluer rapidement. À titre de preuve, l’utilisation de programmes shader est maintenant très répandue dans le matériel grand public comme les consoles de jeux, et cette technologie était à ses balbutiements au moment de la rédaction de la première édition de ce livre. Néanmoins, bien qu’il y ait une grande variance dans les systèmes graphiques et les programmeurs graphiques, la plupart des systèmes ont beaucoup en commun.23 Nous souhaiterions réitérer que notre objectif dans ce chapitre (en fait, tout ce livre !) est de vous donner un aperçu solide, en particulier où les mathématiques sont impliquées, à partir duquel vous pouvez élargir vos connaissances. Ce n’est pas une enquête sur les dernières techniques de pointe. (Real-Time Rendering [1] est la meilleure telle enquête au moment de la rédaction.)
Nous tentons de décrire la procédure de base pour générer une seule image rendue avec un éclairage très basique. Nous ne considérons pas l’animation, et nous ne mentionnons que brièvement les techniques pour l’illumination globale en passant.
Notre description est du flux conceptuel de données à travers le pipeline graphique. En pratique, les tâches sont souvent effectuées en parallèle ou dans le désordre pour des raisons de performance.
Nous nous intéressons aux systèmes de rendu en temps réel qui, au moment de la rédaction, sont principalement orientés vers le rendu de maillages triangulaires. D’autres moyens de produire une image, comme le ray tracing, ont une structure de haut niveau très différente de celle discutée ici. Le lecteur est averti que dans le futur, les techniques pour le rendu en temps réel et hors-ligne pourraient converger si le ray tracing parallèle devient un moyen plus économique de suivre la marche de la loi de Moore.
Avec les simplifications ci-dessus à l’esprit, voici un aperçu général du flux de données à travers le pipeline graphique.
Mise en place de la scène. Avant de pouvoir commencer le rendu, nous devons définir plusieurs options qui s’appliquent à toute la scène. Par exemple, nous devons configurer la caméra, ou plus précisément, choisir un point de vue dans la scène à partir duquel la rendre, et choisir où l’afficher sur l’écran. Nous avons discuté des maths impliquées dans ce processus dans la Section 10.2. Nous devons également sélectionner les options d’éclairage et de brouillard, et préparer le tampon de profondeur.
Détermination de la visibilité. Une fois que nous avons une caméra en place, nous devons ensuite décider quels objets dans la scène sont visibles. C’est extrêmement important pour le rendu en temps réel, car nous ne voulons pas perdre de temps à rendre ce qui n’est pas réellement visible. Cette élimination de haut niveau est très importante pour les vrais jeux, mais est généralement ignorée pour les applications simples lorsqu’on débute, et n’est pas couverte ici.
Définition des états de rendu au niveau de l’objet. Une fois que nous savons qu’un objet est potentiellement visible, il est temps de dessiner réellement l’objet. Chaque objet peut avoir ses propres options de rendu. Nous devons installer ces options dans le contexte de rendu avant de rendre toute primitive associée à l’objet. Peut-être la propriété la plus basique associée à un objet est un matériau qui décrit les propriétés de surface de l’objet. L’une des propriétés matérielles les plus courantes est la couleur diffuse de l’objet, qui est généralement contrôlée en utilisant une carte de texture, comme nous l’avons discuté dans la Section 10.5.
Génération/livraison de géométrie. Ensuite, la géométrie est réellement soumise à l’API de rendu. Typiquement, les données sont livrées sous forme de triangles ; soit comme triangles individuels, ou un maillage triangulaire indexé, une bande de triangles, ou une autre forme. À ce stade, nous pouvons également effectuer la sélection du niveau de détail (LOD) ou générer de la géométrie de manière procédurale. Nous discutons d’un certain nombre de problèmes liés à la livraison de géométrie à l’API de rendu dans la Section 10.10.2.
Opérations au niveau du vertex. Une fois que l’API de rendu a la géométrie dans un format triangulé, un certain nombre d’opérations diverses sont effectuées au niveau du vertex. L’opération peut-être la plus importante est la transformation des positions de vertex de l’espace de modélisation vers l’espace caméra. D’autres opérations au niveau du vertex peuvent inclure le skinning pour l’animation de modèles squelettiques, l’éclairage de vertex et la génération de coordonnées de texture. Dans les systèmes graphiques grand public au moment de la rédaction, ces opérations sont effectuées par un microprogramme fourni par l’utilisateur appelé vertex shader. Nous donnons plusieurs exemples de vertex et pixel shaders à la fin de ce chapitre, dans la Section 10.11.
Élimination, découpage et projection. Ensuite, nous devons effectuer trois opérations pour placer des triangles en 3D sur l’écran en 2D. L’ordre exact dans lequel ces étapes sont prises peut varier. Premièrement, toute partie d’un triangle en dehors du frustum de vue est supprimée, par un processus connu sous le nom de clipping, qui est discuté dans la Section 10.10.4. Une fois que nous avons un polygone découpé en 3D dans l’espace de découpe, nous projetons ensuite les vertices de ce polygone, les mappant vers les coordonnées d’espace écran 2D de la fenêtre de sortie, comme cela a été expliqué dans la Section 10.3.5. Enfin, les triangles individuels qui font face à l’opposé de la caméra sont supprimés (« éliminés »), en fonction de l’ordre horaire ou antihoraire de leurs vertices, comme nous en discutons dans la Section 10.10.5.
Rastérisation. Une fois que nous avons un polygone découpé dans l’espace écran, il est rastérisé. La rastérisation fait référence au processus de sélection des pixels sur l’écran qui doivent être dessinés pour un triangle particulier ; l’interpolation des coordonnées de texture, des couleurs et des valeurs d’éclairage qui ont été calculées au niveau du vertex sur la face pour chaque pixel ; et le passage de ceux-ci à l’étape suivante pour l’ombrage des pixels. Puisque cette opération est généralement effectuée au niveau du matériel, nous ne mentionnerons que brièvement la rastérisation dans la Section 10.10.6.
Ombrage des pixels. Ensuite, nous calculons une couleur pour le pixel, un processus connu sous le nom d’ombrage. Bien sûr, la phrase anodine « calculer une couleur » est au cœur de l’infographie ! Une fois que nous avons choisi une couleur, nous l’écrivons dans le frame buffer, éventuellement soumis au mélange alpha et au -buffering. Nous discutons de ce processus dans la Section 10.10.6. Dans le matériel grand public d’aujourd’hui, l’ombrage des pixels est effectué par un pixel shader, qui est un petit morceau de code que vous pouvez écrire qui prend les valeurs du vertex shader (qui sont interpolées sur la face et fournies par pixel), puis produit la valeur de couleur à l’étape finale : le mélange.
Mélange et sortie. Enfin, au bas du pipeline de rendu, nous avons produit une couleur, une opacité et une valeur de profondeur. La valeur de profondeur est testée par rapport au tampon de profondeur pour la détermination de la visibilité par pixel afin de s’assurer qu’un objet plus éloigné de la caméra n’en occulte pas un plus proche. Les pixels avec une opacité trop faible sont rejetés, et la couleur de sortie est ensuite combinée avec la couleur précédente dans le frame buffer dans un processus connu sous le nom de mélange alpha.
Le pseudocode du Listing 10.10 résume le pipeline de rendu simplifié décrit ci-dessus.
// D'abord, déterminer comment voir la scène
setupTheCamera();
// Effacer le zbuffer
clearZBuffer();
// Configurer l'éclairage environnemental et le brouillard
setGlobalLightingAndFog();
// Obtenir une liste d'objets potentiellement visibles
potentiallyVisibleObjectList = highLevelVisibilityDetermination(scene);
// Rendre tout ce que nous avons trouvé potentiellement visible
for (all objects in potentiallyVisibleObjectList) {
// Effectuer une détermination de visibilité de niveau inférieur
// en utilisant un test de volume englobant
if (!object.isBoundingVolumeVisible()) continue;
// Récupérer ou générer procéduralement la géométrie
triMesh = object.getGeometry()
// Découper et rendre les faces
for (each triangle in the geometry) {
// Transformer les vertices en espace de découpe, et effectuer
// les calculs au niveau du vertex (exécuter le vertex shader)
clipSpaceTriangle = transformAndLighting(triangle);
// Découper le triangle au volume de vue
clippedTriangle = clipToViewVolume(clipSpaceTriangle);
if (clippedTriangle.isEmpty()) continue;
// Projeter le triangle en espace écran
screenSpaceTriangle = clippedTriangle.projectToScreenSpace();
// Le triangle fait-il face à l'arrière ?
if (screenSpaceTriangle.isBackFacing()) continue;
// Rastériser le triangle
for (each pixel in the triangle) {
// Rogner le pixel ici (si le triangle n'a pas été
// complètement découpé au frustum)
if (pixel is off-screen) continue;
// Interpoler la couleur, la valeur du zbuffer,
// et les coordonnées de placage de texture
// Le pixel shader prend les valeurs interpolées
// et calcule une couleur et une valeur alpha
color = shadePixel();
// Effectuer le zbuffering
if (!zbufferTest()) continue;
// Test alpha pour ignorer les pixels qui sont "trop
// transparents"
if (!alphaTest()) continue;
// Écrire dans le frame buffer et le zbuffer
writePixel(color, interpolatedZ);
// Passer au pixel suivant dans ce triangle
}
// Passer au triangle suivant dans cet objet
}
// Passer à l'objet potentiellement visible suivant
}Il n’y a pas si longtemps, un programmeur graphique serait responsable d’écrire du code pour effectuer toutes les étapes montrées dans le Listing 10.10 en logiciel. De nos jours, nous déléguons de nombreuses tâches à une API graphique comme DirectX ou OpenGL. L’API peut effectuer certaines de ces tâches en logiciel sur le CPU principal, et d’autres tâches (idéalement, autant que possible) sont dispatchées vers du matériel graphique spécialisé. Le matériel graphique moderne permet au programmeur graphique (c’est nous) un contrôle très bas niveau à travers les vertex shaders et les pixel shaders, qui sont essentiellement des microprogrammes que nous écrivons et qui sont exécutés sur le matériel pour chaque vertex et pixel traité. Alors que les préoccupations de performance dans les vieux jours du rendu logiciel à processeur unique étaient traitées avec de l’assembleur optimisé à la main, les préoccupations sont maintenant plus liées à l’utilisation du GPU aussi efficacement que possible, et s’assurer qu’il n’est jamais inactif, attendant que le CPU fasse quoi que ce soit. Bien sûr, maintenant comme avant, la façon la plus simple d’accélérer le rendu est simplement d’éviter de rendre quelque chose du tout (s’il n’est pas visible) ou de rendre une approximation moins coûteuse (s’il est petit sur l’écran).
En résumé, un pipeline graphique moderne implique une coopération étroite de notre code et de l’API de rendu. Quand nous disons « API de rendu », nous entendons le logiciel de l’API et le matériel graphique. Sur les plateformes PC, la couche logicielle de l’API est nécessairement très « épaisse », en raison de la grande variété de matériels sous-jacents qui doivent être supportés. Sur les plateformes de console où le matériel est standardisé, la couche peut être significativement plus légère. Un exemple notable était la PlayStation 2, qui permettait aux programmeurs un accès direct aux registres matériels et un contrôle très bas niveau sur l’accès direct à la mémoire (DMA). La Figure 10.36 illustre la division du travail impliquée dans cette coopération.
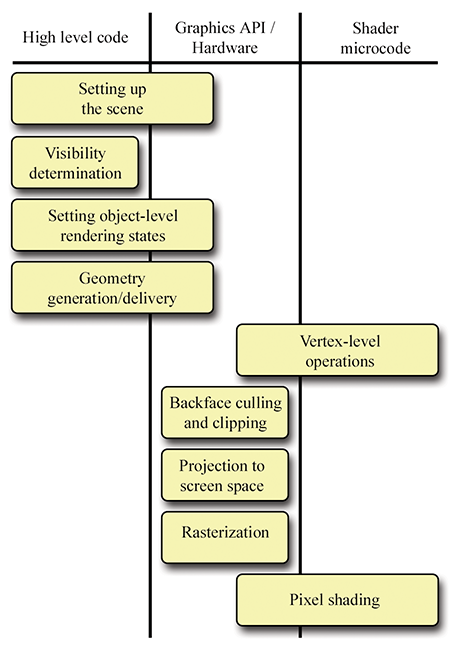
Figure 10.36 Division du travail entre notre code et l’API graphique
Un résumé légèrement différent du pipeline graphique en temps réel est illustré dans la Figure 10.37, cette fois en se concentrant plus sur la partie basse du pipeline et le flux conceptuel des données. Les boîtes bleues représentent les données que nous fournissons, et les ovales bleus sont nos shaders que nous écrivons. Les ovales jaunes sont les opérations effectuées par l’API.
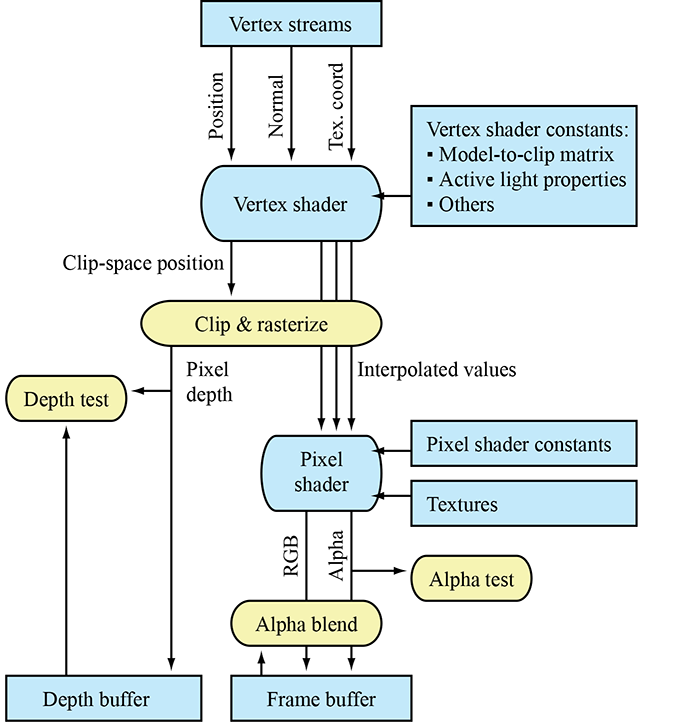
Figure 10.37Flux de données à travers le pipeline graphique.
Le reste de ce chapitre discute d’un certain nombre de sujets divers en infographie. Nous procédons approximativement dans l’ordre où ces sujets sont rencontrés dans le pipeline graphique.
10.10.1Tampons
Le rendu implique de nombreux tampons. Dans ce contexte, un tampon est simplement une région rectangulaire de mémoire qui stocke un certain type de données par pixel. Les tampons les plus importants sont le frame buffer et le tampon de profondeur.
Le frame buffer stocke une couleur par pixel — il contient l’image rendue. La couleur pour un seul pixel peut être stockée dans une variété de formats ; les variations ne sont pas significatives pour la discussion actuelle. Si nous rendons une seule image, le frame buffer peut être dans la RAM normale, pour être sauvegardé sur disque.
Une situation plus intéressante se produit dans l’animation en temps réel. Dans ce cas, le frame buffer est normalement situé dans la RAM vidéo. La carte vidéo lit constamment cette zone de la RAM vidéo, convertissant les données binaires en signal approprié à envoyer au dispositif d’affichage. Mais comment le moniteur peut-il lire cette mémoire alors que nous essayons de la rendre ? Une technique connue sous le nom de double buffering est utilisée pour éviter qu’une image soit affichée avant qu’elle soit complètement rendue. Avec le double buffering, il y a en fait deux frame buffers. Un frame buffer, le tampon avant, contient l’image actuellement affichée sur le moniteur. Le tampon arrière est le tampon hors-écran, qui contient l’image en cours de rendu.
Quand nous avons fini de rendre une image et sommes prêts à l’afficher, nous « retournons » les tampons. Nous pouvons le faire de l’une de deux façons. Si nous utilisons le page flipping, nous demandons au matériel vidéo de commencer à lire depuis le tampon qui était le tampon hors-écran. Nous échangeons ensuite les rôles des deux tampons ; le tampon qui était affiché devient maintenant le tampon hors-écran. Ou nous pouvons copier (blit) le tampon hors-écran par-dessus le tampon d’affichage. Le double buffering est montré dans la Figure 10.38.
Figure 10.38Double buffering
La terminologie plus moderne pour rendre visible l’image qui a été rendue dans le tampon arrière est de présenter l’image.
Le deuxième tampon important utilisé pour le rendu est le tampon de profondeur, également connu sous le nom de -buffer. Plutôt que de stocker une couleur à chaque pixel, le tampon de profondeur stocke une valeur de profondeur par pixel. Il y a de nombreuses variations dans les spécificités de quelle valeur exactement va dans le tampon de profondeur, mais l’idée de base est qu’elle est liée à la distance depuis la caméra. Souvent, la coordonnée dans l’espace de découpe est utilisée comme valeur de profondeur, c’est pourquoi le tampon de profondeur est également connu comme le -buffer.
Le tampon de profondeur est utilisé pour déterminer quels objets occultent quels objets, comme suit. Lorsque nous rastérisons un triangle, nous calculons une valeur de profondeur interpolée par pixel. Avant de rendre un pixel, nous comparons cette valeur de profondeur avec la valeur déjà dans le tampon de profondeur pour ce pixel. Si la nouvelle profondeur est plus éloignée de la caméra que la valeur actuellement dans le tampon de profondeur, alors le pixel est rejeté. Sinon, la couleur du pixel est écrite dans le frame buffer, et le tampon de profondeur est mis à jour avec la nouvelle valeur de profondeur plus proche.
Avant de pouvoir commencer à rendre une image, nous devons effacer le tampon de profondeur à une valeur qui signifie « très loin de la caméra ». (Dans l’espace de découpe, cette valeur est 1.0). Ensuite, les premiers pixels à être rendus sont garantis de passer le test du tampon de profondeur. Il n’est généralement pas nécessaire de double-bufferiser le tampon de profondeur comme nous le faisons pour le frame buffer.
10.10.2Livraison de la géométrie
Après avoir décidé quels objets rendre, nous devons réellement les rendre. C’est en fait un processus en deux étapes. Premièrement, nous devons configurer le contexte de rendu. Cela implique de dire au moteur de rendu quels vertex et pixel shaders utiliser, quelles textures utiliser, et de définir toutes les autres constantes nécessaires aux shaders, comme les matrices de transformation, les positions d’éclairage, les couleurs, les paramètres de brouillard, etc. Les détails de ce processus dépendent beaucoup de votre stratégie de rendu de haut niveau et de la plateforme cible, donc il n’y a pas grand-chose de plus spécifique que nous puissions dire ici, bien que nous donnions plusieurs exemples dans la Section 10.11. Au lieu de cela, nous souhaitons nous concentrer sur la deuxième étape, qui est essentiellement la boîte du dessus dans la Figure 10.37, où les données de vertex sont livrées à l’API pour le rendu. De nos jours, un programmeur a beaucoup de flexibilité dans les données à envoyer, comment compresser et formater chaque élément de données, et comment arranger les bits en mémoire pour une efficacité maximale. Quelles valeurs pourrions-nous avoir besoin de fournir par vertex ? Fondamentalement, la réponse est : « quelles que soient les propriétés que vous souhaitez utiliser pour rendre les triangles ». En fin de compte, il n’y a que deux sorties requises du vertex et pixel shader. Premièrement, le vertex shader doit produire une position pour chaque vertex afin que le matériel puisse effectuer la rastérisation. Cette position est typiquement spécifiée dans l’espace de découpe, ce qui signifie que le matériel effectuera la division de perspective et la conversion vers les coordonnées d’espace écran (voir la Section 10.3.5) pour vous. Le pixel shader n’a vraiment qu’une seule sortie requise : une valeur de couleur (qui comprend généralement un canal alpha). Ces deux sorties sont les seules choses qui sont requises. Bien sûr, pour déterminer correctement les coordonnées d’espace de découpe, nous avons probablement besoin de la matrice qui transforme de l’espace modèle vers l’espace de découpe. Nous pouvons passer des paramètres comme celui-ci qui s’appliquent à tous les vertices ou pixels d’un lot donné de triangles en définissant des constantes de shader. Cela est conceptuellement juste une grande table de valeurs vectorielles qui fait partie du contexte de rendu et que nous utilisons selon nos besoins. (En fait, il y a généralement un ensemble de registres assignés pour une utilisation dans le vertex shader et un ensemble différent de registres accessibles dans le pixel shader.)
Certains types d’informations typiques stockées au niveau du vertex incluent
Position. Décrit l’emplacement du vertex. Cela peut être un vecteur 3D ou une position 2D en espace écran, ou cela pourrait être une position déjà transformée en espace de découpe qui est simplement transmise directement via le vertex shader. Si un vecteur 3D est utilisé, la position doit être transformée en espace de découpe par les transformations de modèle, vue et projection actuelles. Si des coordonnées de fenêtre 2D (variant selon la résolution de l’écran, non normalisées) sont utilisées, elles doivent être reconverties en espace de découpe dans le vertex shader. (Certains matériels permettent à votre shader de produire des coordonnées déjà projetées en espace écran.)
Si le modèle est un modèle skinné (voir la Section 10.8), alors les données positionnelles doivent également inclure les indices et les poids des os qui influencent le vertex. Les matrices animées peuvent être livrées de diverses façons. Une technique standard est de les passer comme constantes de vertex shader. Une technique plus récente qui fonctionne sur certains matériels est de les livrer dans un flux de vertex séparé, qui doit être accédé via des instructions spéciales puisque le motif d’accès est aléatoire plutôt que continu.Coordonnées de placage de texture. Si nous utilisons des triangles avec placage de texture, alors chaque vertex doit se voir assigner un ensemble de coordonnées de mappage. Dans le cas le plus simple, c’est un emplacement 2D dans la carte de texture. Nous notons habituellement les coordonnées . Si nous utilisons le multitexturing, nous pourrions avoir besoin d’un ensemble de coordonnées de mappage par carte de texture. Optionnellement, nous pouvons générer un ou plusieurs ensembles de coordonnées de placage de texture de manière procédurale (par exemple, si nous projetons un gobo sur une surface).
Normale de surface. La plupart des calculs d’éclairage ont besoin de la normale de surface. Même si ces équations d’éclairage sont souvent effectuées par pixel, avec la normale de surface étant déterminée à partir d’une carte de normales, nous stockons souvent quand même une normale au niveau du vertex, afin d’établir la base pour l’espace tangent.
Couleur. Parfois, il est utile d’assigner une entrée de couleur à chaque vertex. Par exemple, si nous rendons des particules, la couleur de la particule peut changer avec le temps. Ou nous pouvons utiliser un canal (comme l’alpha) pour contrôler le mélange entre deux couches de texture. Un artiste peut éditer l’alpha de vertex pour contrôler ce mélange. Nous pourrions également avoir des calculs d’éclairage par vertex effectués hors-ligne.
Vecteurs de base. Comme discuté dans la Section 10.9, pour les cartes de normales dans l’espace tangent (et quelques autres techniques similaires), nous avons besoin de vecteurs de base pour définir l’espace tangent local. Les vecteurs de base et la normale de surface établissent cet espace de coordonnées à chaque vertex. Ces vecteurs sont ensuite interpolés sur le triangle pendant la rastérisation, pour fournir un espace tangent approximatif par pixel.
Avec tout cela à l’esprit, donnons quelques exemples de structs C qui pourraient être utilisés pour livrer des données de vertex dans certaines situations qui pourraient survenir en pratique.
L’un des formats de vertex les plus basiques contient une position 3D, une normale de surface et des coordonnées de mappage. Un maillage triangulaire basique avec une simple carte diffuse est stocké en utilisant ce type de vertex. Nous ne pouvons pas utiliser des cartes de normales dans l’espace tangent avec ce format de vertex, car il n’y a pas de vecteurs de base :
// Vertex non transformé, non éclairé
struct RenderVertex {
Vector3 p; // position
float u,v; // coordonnées de placage de texture
Vector3 n; // normale
};Si nous voulons utiliser une carte de normales dans l’espace tangent, nous devrons inclure des vecteurs de base :
// Vertex non transformé, non éclairé avec vecteurs de base
struct RenderVertexBasis {
Vector3 p; // position
Vector3 n; // normale
Vector3 tangent; // 1er vecteur de base
float det; // Déterminant de la transformation de l'espace tangent
// (indicateur d'inversion)
float u,v; // coordonnées de placage de texture
};Un autre format courant, utilisé pour les affichages tête haute, le rendu de texte et d’autres éléments 2D, est un vertex avec des coordonnées en espace écran et des vertices pré-éclairés (aucune normale n’a besoin d’être fournie car aucun calcul d’éclairage n’aura lieu) :
// 2D en espace écran, pré-éclairé.
struct RenderVertex2D {
float x,y; // position 2D en espace écran
unsigned argb; // couleur pré-éclairée (0xAARRGGBB)
float u,v; // coordonnées de placage de texture
};Le vertex suivant est exprimé en 3D, mais n’a pas besoin d’être éclairé par le moteur d’éclairage de l’API graphique. Ce format est souvent utile pour les effets de particules, tels que les explosions, les flammes et les objets auto-illuminés, et pour rendre des objets de débogage tels que les boîtes englobantes, les waypoints, les marqueurs et similaires :
// Vertex non transformé, éclairé
struct RenderVertexL {
Vector3 p; // position 3D
unsigned argb; // couleur pré-éclairée (0xAARRGGBB)
float u,v; // coordonnées de placage de texture
};L’exemple suivant est un vertex utilisé pour la géométrie avec lightmap et bump map. Il a des vecteurs de base pour le lightmapping, et deux ensembles d’UV, un pour la texture diffuse normale, et un autre pour la lightmap, qui stocke l’éclairage précalculé hors-ligne :
// Vertex avec lightmap et bump map
struct RenderVertexLtMapBump {
Vector3 p; // position
Vector3 n; // normale
Vector3 tangent; // 1er vecteur de base
float det; // Déterminant de la transformation de l'espace tangent
// (indicateur d'inversion)
float u,v; // coordonnées normales pour la texture diffuse et la bump map
float lmu,lmv; // coordonnées de texture dans la lightmap
};Enfin, voici un vertex qui pourrait être utilisé pour le rendu squelettique. Les indices sont stockés dans quatre valeurs de 8 bits, et les poids sont stockés comme quatre floats :
// Vertex avec lightmap, bump map et skinning
struct RenderVertexSkinned {
Vector3 p; // position
Vector3 n; // normale
Vector3 tangent; // 1er vecteur de base
float det; // Déterminant de la transformation de l'espace tangent
// (indicateur d'inversion)
float u,v; // coordonnées normales pour la texture diffuse et la bump map
unsigned boneIndices; // indices d'os pour jusqu'à 4 os
// (valeurs de 8 bits)
Vector4 boneWeights; // poids pour jusqu'à 4 os
};Les exemples précédents étaient tous déclarés comme des structs. Comme vous pouvez le voir, les combinaisons peuvent croître très rapidement. Gérer cela simplement mais efficacement est un défi. Une idée est d’allouer les champs comme une structure de tableaux (SOA) plutôt qu’un tableau de structures (AOS) :
struct VertexListSOA {
Vector3 *p; // positions
Vector3 *n; // normales
Vector4 *tangentDet; // tangent xyz + det dans w
Vector2 *uv0; // coordonnées de mappage du premier canal
Vector2 *uv1; // mappage du second canal
Vector2 *ltMap; // coordonnées de lightmap
unsigned *boneIndices; // indices d'os pour jusqu'à 4 os
// (valeurs de 8 bits)
Vector4 *boneWeights; // poids pour jusqu'à 4 os
unsigned *argb; // couleur de vertex
};Dans ce cas, si une valeur n’était pas présente, le pointeur de tableau serait simplement NULL.
Une autre idée est d’utiliser un bloc brut de mémoire, mais de déclarer une classe de format de vertex avec des fonctions d’accès qui font l’arithmétique d’adresse pour localiser un vertex par index, basé sur le pas variable, et accéder à un membre basé sur son décalage variable au sein de la structure.
10.10.3Opérations au niveau du vertex
Après que les données de maillage ont été soumises à l’API, un large éventail de calculs au niveau du vertex est effectué. Dans un moteur de rendu basé sur des shaders (par opposition à un pipeline à fonction fixe), cela se produit dans notre vertex shader. L’entrée d’un vertex shader est essentiellement l’une des structs que nous avons décrites dans la section précédente. Comme discuté précédemment, un vertex shader peut produire de nombreux types de sortie différents, mais il y a deux responsabilités de base qu’il doit remplir. La première est qu’il doit produire, au minimum, une position dans l’espace de découpe (ou dans certaines circonstances en espace écran). La deuxième responsabilité est de fournir au pixel shader toutes les entrées nécessaires pour que le pixel shader effectue les calculs d’ombrage. Dans de nombreux cas, nous pouvons simplement transmettre les valeurs de vertex reçues des flux d’entrée, mais d’autres fois, nous devons effectuer des calculs, comme transformer les valeurs de vertex brutes de l’espace de modélisation vers un autre espace de coordonnées dans lequel nous effectuons l’éclairage ou générons des coordonnées de texture.
Certaines des opérations les plus courantes effectuées dans un vertex shader sont
Transformer les positions de vertex dans l’espace modèle vers l’espace de découpe.
Effectuer le skinning pour les modèles squelettiques.
Transformer les normales et les vecteurs de base vers l’espace approprié pour l’éclairage.
Calculer les vecteurs nécessaires pour l’éclairage ( et ) et les transformer vers l’espace de coordonnées approprié.
Calculer les valeurs de densité de brouillard à partir de la position du vertex.
Générer des coordonnées de placage de texture de manière procédurale. Les exemples incluent les spots projetés, les lumières volumétriques de style Doom, la réflexion d’un vecteur de vue autour de la normale pour le mapping d’environnement, diverses techniques de réflexion factice, les textures défilantes ou autrement animées, etc.
Transmettre les entrées de vertex brutes sans modification, si elles sont déjà dans le bon format et espace de coordonnées.
Si nous utilisons l’ombrage de Gouraud, nous pourrions réellement effectuer les calculs d’éclairage ici, et interpoler les résultats d’éclairage. Nous montrerons quelques exemples de cela plus loin dans le chapitre.
La transformation de l’espace de modélisation vers l’espace de découpe est l’opération la plus courante, donc revoyons le processus. Nous le faisons avec la multiplication matricielle. Conceptuellement, les vertices subissent une séquence de transformations comme suit :
La transformation de modèle transforme de l’espace de modélisation vers l’espace mondial.
La transformation de vue transforme de l’espace mondial vers l’espace caméra.
La matrice de découpe est utilisée pour transformer de l’espace caméra vers l’espace de découpe.
Conceptuellement, les maths matricielles sont
En pratique, nous n’effectuons pas réellement trois multiplications matricielles séparées. Nous avons une matrice qui transforme de l’espace objet vers l’espace de découpe, et à l’intérieur du vertex shader nous effectuons une multiplication matricielle en utilisant cette matrice.
10.10.4Découpage (Clipping)
Après que les vertices ont été transformés dans l’espace de découpe, deux tests importants sont effectués sur le triangle : le découpage et l’élimination. Les deux opérations sont généralement effectuées par l’API de rendu, donc bien que vous n’ayez généralement pas à effectuer ces opérations vous-même, il est important de savoir comment elles fonctionnent. L’ordre dans lequel nous discutons de ces tests n’est pas nécessairement l’ordre dans lequel ils se produiront sur un matériel particulier. La plupart des matériels éliminent dans l’espace écran, tandis que les anciens moteurs de rendu logiciels le faisaient plus tôt, en 3D, pour réduire le nombre de triangles qui devaient être découpés.
Avant de pouvoir projeter les vertices sur l’espace écran, nous devons nous assurer qu’ils sont complètement à l’intérieur du frustum de vue. Ce processus est connu sous le nom de clipping. Puisque le clipping est normalement effectué par le matériel, nous décrirons le processus avec seulement des détails sommaires.
L’algorithme standard pour couper des polygones est l’algorithme Sutherland-Hodgman. Cet algorithme s’attaque au problème difficile du découpage de polygones en le décomposant en une séquence de problèmes faciles. Le polygone d’entrée est découpé par rapport à un plan à la fois.
Pour couper un polygone par rapport à un plan, nous itérons autour du polygone, en coupant chaque arête par rapport au plan en séquence. Chacun des deux vertices de l’arête peut être à l’intérieur ou à l’extérieur du plan ; ainsi, il y a quatre cas. Chaque cas peut générer zéro, un ou deux vertices de sortie, comme le montre la Figure 10.39.
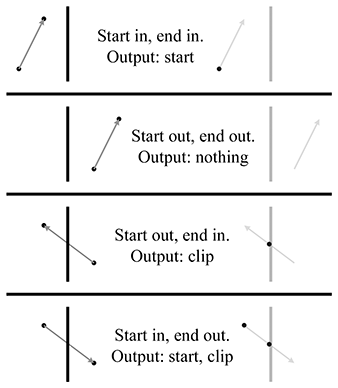
Figure 10.39Découpage d’une seule arête — les quatre cas
La Figure 10.40 montre un exemple de la façon dont nous pouvons appliquer ces règles pour couper un polygone par rapport au plan de découpe droit. Rappelez-vous que le découpeur produit des vertices, et non des arêtes. Dans la Figure 10.40, les arêtes sont dessinées uniquement pour illustration. En particulier, l’étape de découpe finale semble produire deux arêtes alors qu’en réalité un seul vertex a été produit — la dernière arête est implicite pour compléter le polygone.
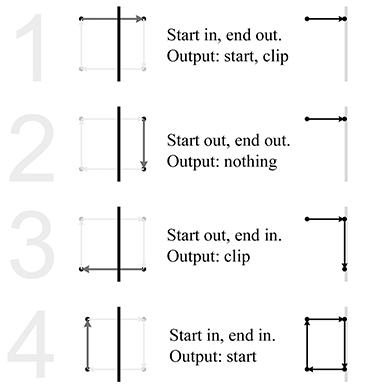
Figure 10.40 Découpage d’un polygone par rapport au plan de découpe droit
À la fin de chaque étape, s’il reste moins de trois vertices, le polygone est rejeté comme étant invisible. (Notez qu’il est impossible de produire un seul ou deux vertices. Le nombre de vertices produits par un seul passage sera soit zéro, soit au moins trois.)
Certains matériels graphiques ne découpent pas les polygones par rapport à tous les six plans en 3D (ou 4D). Au lieu de cela, seul le découpage proche est effectué, puis le scissoring est effectué en 2D pour découper à la fenêtre. Cela peut être un gain de performance car le découpage est lent sur certains matériels. Une variation de cette technique consiste à employer une bande de garde. Les polygones complètement à l’extérieur de l’écran sont rejetés, les polygones complètement à l’intérieur de la bande de garde sont rognis plutôt que découpés en 3D, et les polygones partiellement à l’écran mais à l’extérieur de la bande de garde sont découpés en 3D.
10.10.5Élimination des faces arrière
Le deuxième test utilisé pour rejeter les surfaces cachées est connu sous le nom d’élimination des faces arrière, et le but de ce test est de rejeter les triangles qui ne font pas face à la caméra. Dans les maillages fermés standard, nous ne devrions jamais voir le côté arrière d’un triangle à moins qu’on nous autorise à aller à l’intérieur du maillage. La suppression des triangles faisant face à l’arrière n’est pas strictement nécessaire dans un maillage opaque — nous pourrions les dessiner et générer quand même une image correcte, car ils seront couverts par un triangle plus proche faisant face à l’avant. Cependant, nous ne voulons pas perdre de temps à dessiner ce qui n’est pas visible, donc nous voulons généralement éliminer les faces arrière. En théorie, environ la moitié des triangles feront face à l’arrière. En pratique, moins de la moitié des triangles peuvent être éliminés, surtout dans les décors statiques, qui dans de nombreux cas sont créés sans faces arrière dès le départ. Un exemple évident est un système de terrain. Certainement, nous pourrions être capables d’éliminer certains triangles faisant face à l’arrière, par exemple, sur le côté opposé d’une colline, mais en général la plupart des triangles feront face à l’avant car nous sommes généralement au-dessus du sol. Cependant, pour les objets dynamiques qui se déplacent librement dans le monde, environ la moitié des faces feront face à l’arrière.
Les triangles faisant face à l’arrière peuvent être détectés en 3D (avant projection) ou en 2D (après projection). Sur le matériel graphique moderne, l’élimination des faces arrière est effectuée en 2D en fonction de l’énumération horaire ou antihoraire des vertices dans l’espace écran. Dans un système de coordonnées main gauche comme celui que nous utilisons dans ce livre, la convention est d’ordonner les vertices de façon horaire autour du triangle lorsqu’on le regarde du côté avant. Ainsi, comme montré dans la Figure 10.41, nous supprimerons normalement tout triangle dont les vertices sont ordonnés de façon antihoraire sur l’écran. (Les droitiers emploient généralement les conventions opposées.)
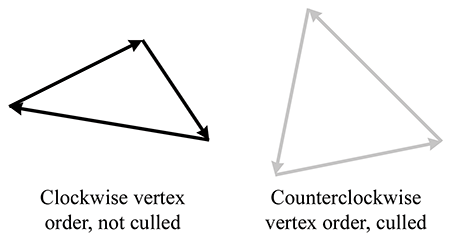
Figure 10.41 Élimination des faces arrière des triangles avec vertices énumérés antihoraire en espace écran
Figure 10.42Élimination des faces arrière en 3D
L’API vous permettra de contrôler l’élimination des faces arrière. Vous pouvez vouloir désactiver l’élimination des faces arrière lors du rendu de certaine géométrie. Ou, si la géométrie a été réfléchie, vous devrez peut-être inverser l’élimination, car la réflexion inverse l’ordre des vertices autour des faces. Le rendu en utilisant des ombres stencil nécessite de rendre les faces avant dans un passage et les faces arrière dans un autre passage.
Les goulots d’étranglement sont différents dans le rendu logiciel par rapport au rendu matériel (notamment, la bande passante requise pour la livraison brute des données au matériel), et dans le logiciel, l’élimination des faces arrière est généralement effectuée en 3D. L’idée de base avec le test de face arrière en 3D est de déterminer si la position de la caméra est du côté avant du plan du triangle. Pour effectuer cette détermination rapidement, nous stockons une normale de triangle précalculée. Cela est montré dans la Figure 10.42, dans laquelle les triangles faisant face à l’arrière qui pourraient être éliminés sont dessinés en gris. Notez que l’élimination des faces arrière ne dépend pas de savoir si un triangle est à l’intérieur ou à l’extérieur du frustum de vue. En fait, elle ne dépend pas du tout de l’orientation de la caméra — seule la position de la caméra par rapport au triangle est pertinente.
Pour détecter les triangles faisant face à l’arrière en 3D, nous avons besoin de la normale du plan contenant le triangle, et d’un vecteur de l’œil vers le triangle (n’importe quel point sur le triangle fera l’affaire — généralement nous choisissons simplement un vertex arbitrairement). Si ces deux vecteurs pointent essentiellement dans la même direction (leur produit scalaire est supérieur à zéro), alors le triangle fait face à l’arrière. Une variation sur ce thème est de précalculer et stocker également la valeur de l’équation du plan (voir la Section 9.5.1). Ensuite, la vérification de face arrière peut être effectuée avec un produit scalaire et une comparaison scalaire. Une remarque rapide sur une astuce d’optimisation tentante qui ne fonctionne pas : vous pourriez essayer d’utiliser uniquement la composante de la normale du triangle dans l’espace caméra (ou de découpe). Bien qu’il puisse sembler que si la valeur est positive, le triangle fait face à l’opposé de la caméra et pourrait être éliminé, un exemple où ce n’est pas vrai est entouré dans la Figure 10.42.
10.10.6Rastérisation, ombrage et sortie
Après le découpage, les vertices sont projetés et mappés dans les coordonnées d’écran de la fenêtre de sortie, selon les Équations (10.8)–(10.9). Bien sûr, ces coordonnées sont des coordonnées en virgule flottante, qui sont « continues » (voir la Section 1.1). Mais nous rendons généralement des pixels, qui sont discrets. Alors comment savons-nous quels pixels sont réellement dessinés ? Concevoir un algorithme pour répondre à cette question est étonnamment compliqué. Si nous répondons mal, des lacunes peuvent apparaître entre les triangles. Rendre un pixel plus d’une fois peut aussi être mauvais si nous utilisons le mélange alpha. En d’autres termes, nous devons nous assurer que lorsque nous rendons une surface représentée par des triangles, chaque pixel est rendu exactement une fois. Heureusement, le matériel graphique s’en charge pour nous et nous n’avons pas à nous soucier des détails.
Pendant la rastérisation, le système de rendu peut effectuer le scissoring, qui rejette les pixels qui sont à l’extérieur de la fenêtre de rendu. C’est impossible si le polygone est découpé au bord de l’écran, mais il peut être avantageux pour des raisons de performance de sauter cette étape. La bande de garde est une technique qui peut être utilisée pour ajuster les compromis de performance entre le découpage et le scissoring (voir la Section 10.10.4).
Même si nous n’avons pas nécessairement besoin de comprendre exactement comment le matériel graphique décide quels pixels rendre pour un triangle donné, nous devons comprendre comment il détermine quoi faire avec un seul pixel. Conceptuellement, cinq étapes de base sont effectuées :
Interpoler. Toutes les quantités calculées au niveau du vertex, comme les coordonnées de texture, les couleurs et les normales, sont interpolées sur la face. Les valeurs interpolées pour chaque quantité doivent être calculées pour le pixel avant qu’il puisse être ombré.
Test de profondeur. Nous rejetons les pixels en utilisant le tampon de profondeur (voir la Section 10.10.1) si le pixel que nous allons ombrager serait obscurcit par un pixel plus proche. Notez que, dans certaines circonstances, le pixel shader est autorisé à modifier la valeur de profondeur, auquel cas ce test doit être différé jusqu’après l’ombrage.
Ombrager. L’ombrage de pixels fait référence au processus de calcul d’une couleur pour un pixel. Sur le matériel basé sur des shaders, c’est là que votre pixel shader est exécuté. Dans un passage de rendu direct basique, où nous rendons réellement des objets dans le frame buffer (par opposition à l’écriture dans une carte d’ombres, ou à l’exécution d’un autre passage d’éclairage), le pixel est généralement d’abord éclairé puis brumisé si le brouillard est utilisé. La sortie d’un pixel shader consiste non seulement en une couleur RGB, mais aussi en une valeur alpha, qui est généralement interprétée comme l’« opacité » du pixel, utilisée pour le mélange. La section suivante montre plusieurs exemples de pixel shaders.
Test alpha. Cela rejette les pixels en fonction de la valeur alpha du pixel. Toutes sortes de tests alpha différents peuvent être utilisés, mais le plus courant est de rejeter les pixels qui sont « trop transparents ». Bien que de tels pixels invisibles puissent ne pas causer de changement dans le frame buffer si nous les écrivions, nous devons les rejeter pour ne pas écrire dans le tampon de profondeur.
Écrire. Si le pixel passe les tests de profondeur et alpha, alors le frame buffer et les tampons de profondeur sont mis à jour.
Le tampon de profondeur est mis à jour simplement en remplaçant l’ancienne valeur de profondeur par la nouvelle.
La mise à jour du frame buffer est plus complexe. Si le mélange n’est pas utilisé, alors la nouvelle couleur du pixel remplace l’ancienne. Sinon, la nouvelle couleur du pixel est mélangée avec l’ancienne, avec les contributions relatives des anciennes et nouvelles couleurs contrôlées par la valeur alpha. D’autres opérations mathématiques, comme l’addition, la soustraction et la multiplication, sont également souvent disponibles, selon le matériel graphique.
10.11Quelques exemples HLSL
Dans cette section, nous allons présenter quelques exemples de vertex et pixel shaders HLSL qui démontrent beaucoup des techniques discutées dans les sections précédentes. Ces extraits de code sont bien commentés, car nous avons l’intention que ce code soit lu. Nous donnons des exemples en HLSL pour la même raison que nous montrons des extraits de code en C : nous nous attendons à ce qu’il soit applicable à un grand nombre de nos lecteurs, et bien que nous sachions que tous les lecteurs n’utiliseront pas ce langage spécifique, nous pensons que le langage est suffisamment haut niveau pour que de nombreux principes de base puissent être transmis et appréciés par presque tout le monde.
HLSL est essentiellement le même langage que le langage de shader développé par NVIDIA connu sous le nom de « Cg ». HLSL est également très similaire, bien que pas identique, à GLSL, le langage de shader utilisé dans OpenGL.
Un aspect de HLSL qui, nous réalisons, introduit un obstacle non désiré pour ceux qui ne s’intéressent pas au rendu en temps réel est la division du travail entre les vertex et pixel shaders.24 Malheureusement, c’est là que certains des détails désordonnés ne peuvent pas être complètement cachés. Ce livre n’est pas un livre sur HLSL, donc nous n’expliquons pas pleinement ces détails, et une certaine exposition à HLSL est utile. Cependant, comme le langage utilise la syntaxe C, il est relativement accessible, et nos exemples devraient être lisibles. Pour ceux qui ne connaissent pas HLSL, les commentaires dans les exemples introduisent les spécificités HLSL au fur et à mesure qu’elles se présentent.
Parce que ces exemples sont tous très basiques, ils ont été écrits ciblant le modèle de shader 2.0.
10.11.1L’ombrage décalque et les bases HLSL
Nous commençons par un exemple très simple pour nous échauffer et démontrer les mécanismes de base de HLSL pour déclarer des constantes et passer des arguments interpolés. Peut-être le type d’ombrage le plus simple est de simplement produire la couleur d’une carte de texture directement, sans aucun éclairage. C’est parfois appelé ombrage décalque. Le vertex shader du Listing 10.11 illustre plusieurs des mécanismes de base de HLSL, comme expliqué par les commentaires du code source.
// Cette structure déclare les entrées que nous recevons du maillage.
// Notez que l'ordre ici n'est pas important. Les entrées sont identifiées
// par leur "sémantique", qui est la chose à droite après le signe
// deux-points. Lors de l'envoi de la liste de vertices au moteur de rendu,
// nous devons spécifier la "sémantique" de chaque élément de vertex.
struct Input {
float4 pos : POSITION; // position dans l'espace de modélisation
float2 uv : TEXCOORD0; // coordonnées de texture
};
// Voici les données que nous produirons depuis notre vertex shader.
// Elles sont mises en correspondance avec les entrées du pixel shader
// basées sur la sémantique
struct Output {
float4 pos : POSITION; // position dans l'espace de DÉCOUPE
float2 uv : TEXCOORD0; // coordonnée de texture
};
// Ici nous déclarons une variable globale, qui est une constante de shader
// contenant la matrice de transformation modèle->découpe.
uniform float4x4 modelToClip;
// Le corps de notre vertex shader
Output main(Input input) {
Output output;
// Transformer la position du vertex vers l'espace de découpe. La fonction
// intrinsèque mul() effectue la multiplication matricielle. Notez que mul()
// traite tout vecteur passé comme premier opérande comme un vecteur ligne.
output.pos = mul(input.pos, modelToClip);
// Transmettre les coordonnées UV fournies sans modification
output.uv = input.uv;
return output;
}Listing 10.11Vertex shader pour le rendu décalque
Un vertex shader comme celui-ci pourrait être utilisé avec le pixel shader du Listing 10.12, qui effectue réellement l’ombrage décalque. Cependant, pour rendre les choses intéressantes et démontrer que les constantes de pixel shader fonctionnent de la même manière que les constantes de vertex shader, nous avons ajouté une couleur constante globale, que nous considérons comme faisant partie du contexte de rendu global. Nous avons trouvé très utile d’avoir une constante comme celle-ci, qui module la couleur et l’opacité de chaque primitive rendue.
// Cette structure déclare les entrées interpolées que nous recevons du
// rastériseur. Elles correspondront généralement exactement aux sorties
// du vertex, sauf que nous laissons souvent de côté la position en
// espace de découpe.
struct Input {
float2 uv : TEXCOORD0; // coordonnées de texture
};
// Ici, juste pour montrer comment fonctionne une constante de pixel
// shader, nous déclarons une couleur constante globale. La sortie de
// notre shader est multipliée par cette valeur RGBA. L'une des raisons
// les plus courantes d'avoir une telle constante est d'ajouter un réglage
// d'opacité dans le contexte de rendu, mais c'est très pratique d'avoir
// une couleur constante RGBA complète.
uniform float4 constantColor;
// Nous allons effectuer une recherche de texture. Ici nous déclarons une
// "variable" pour faire référence à cette texture, et l'annotons avec
// suffisamment d'informations pour que notre code de rendu puisse
// sélectionner la texture appropriée dans le contexte de rendu avant de
// dessiner les primitives.
sampler2D diffuseMap;
// Le corps de notre pixel shader. Il n'a qu'une seule sortie, qui tombe
// sous la sémantique "COLOR"
float4 main(Input input): COLOR {
// Récupérer le texel
float4 texel = tex2D(diffuseMap, input.uv);
// Le moduler par la couleur constante et le produire. Notez que
// l'opérateur* effectue une multiplication composante par composante.
return texel*constantColor;
}Listing 10.12Pixel shader pour le rendu décalque
Il est clair que le code de niveau supérieur doit fournir correctement les constantes de shader et les données primitives. La façon la plus simple de faire correspondre une constante de shader avec le code de niveau supérieur est d’assigner spécifiquement un numéro de registre à une constante en utilisant une syntaxe spéciale de déclaration de variable HLSL, mais il existe des techniques plus subtiles, comme la localisation des constantes par nom. Ces détails pratiques sont certainement importants, mais ils n’appartiennent pas à ce livre.
10.11.2Éclairage Blinn-Phong basique par pixel
Maintenant regardons un exemple simple qui effectue réellement des calculs d’éclairage. Nous commençons par un éclairage basique par pixel, bien que nous n’utilisions pas encore de bump map. Cet exemple illustre simplement la technique d’ombrage de Phong consistant à interpoler la normale sur la face et à évaluer l’équation d’éclairage complète par pixel. Nous comparons l’ombrage de Phong avec l’ombrage de Gouraud dans la Section 10.11.3, et nous montrons un exemple de normal mapping dans la Section 10.11.4.
Tous nos exemples d’éclairage utilisent l’équation d’éclairage standard Blinn-Phong. Dans cet exemple et la plupart des exemples suivants, l’environnement d’éclairage se compose d’une seule lumière omni à atténuation linéaire plus un ambiant constant.
Pour le premier exemple (Listings 10.13 et 10.14), nous effectuons tout le travail dans le pixel shader. Dans ce cas, le vertex shader est assez trivial ; il n’a qu’à transmettre les entrées au pixel shader.
// Entrées du maillage.
struct Input {
float4 pos : POSITION; // position dans l'espace modèle
float3 normal : NORMAL; // normale de vertex dans l'espace modèle
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
};
// Sortie du vertex shader. Notez qu'à l'exception de la position de sortie,
// qui est produite sous la sémantique POSITION, toutes les autres vont
// sous la sémantique TEXCOORDx. Malgré son nom, cette sémantique est
// réellement utilisée pour pratiquement TOUTE valeur vectorielle interpolée
// jusqu'en 4D que nous voulons passer au pixel shader, pas seulement les
// coordonnées de texture.
struct Output {
float4 clipPos : POSITION; // position en espace de découpe
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
float3 normal : TEXCOORD1; // normale de vertex dans l'espace modèle
float3 modelPos : TEXCOORD2; // position dans l'espace modèle
};
// Matrice de transformation modèle->découpe.
uniform float4x4 modelToClip;
// Le corps de notre vertex shader
Output main(Input input) {
Output output;
// Transformer la position du vertex vers l'espace de découpe.
output.clipPos = mul(input.pos, modelToClip);
// Transmettre les entrées de vertex sans modification
output.normal = input.normal;
output.uv = input.uv;
output.modelPos = input.pos;
return output;
}Listing 10.13Vertex shader pour l’éclairage par pixel d’une seule omni plus ambiant
Le Listing 10.14 est le pixel shader correspondant, où toute l’action se déroule. Notez que nous utilisons deux cartes de texture différentes, une pour la couleur diffuse et une autre pour la couleur spéculaire. Nous supposons que les deux cartes utilisent les mêmes coordonnées de placage de texture.
// Entrées interpolées depuis le vertex shader.
struct Input {
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
float3 normal : TEXCOORD1; // normale de vertex dans l'espace modèle
float3 modelPos : TEXCOORD2; // position en espace modèle (pour l'éclairage)
};
// Une constante globale RGB et opacité
uniform float4 constantColor;
// Position de la lumière omni, dans l'espace MODÈLE
uniform float3 omniPos;
// Réciproque du rayon de la lumière omni. (La lumière décroîtra
// linéairement jusqu'à zéro à ce rayon). Notez qu'il est courant de
// ranger cela dans la composante w de la position, pour réduire le
// nombre de constantes, car chaque constante prend généralement un
// emplacement de vecteur 4D complet.
uniform float invOmniRad;
// Couleur de la lumière omni non atténuée
uniform float3 omniColor;
// Position de vue, dans l'espace MODÈLE
uniform float3 viewPos;
// Couleur de lumière ambiante constante
uniform float3 ambientLightColor;
// Brillance du matériau (exposant de Phong)
uniform float specExponent;
// Échantillonneurs de cartes diffuse et spéculaire. Notez que nous
// supposons que les cartes diffuse et spéculaire utilisent les mêmes
// coordonnées UV
sampler2D diffuseMap;
sampler2D specularMap;
// Corps du pixel shader
float4 main(Input input): COLOR {
// Récupérer les texels pour obtenir les couleurs du matériau
float4 matDiff = tex2D(diffuseMap, input.uv);
float4 matSpec = tex2D(specularMap, input.uv);
// Normaliser la normale de vertex interpolée
float3 N = normalize(input.normal);
// Calculer le vecteur vers la lumière
float3 L = omniPos - input.modelPos;
// Le normaliser, et sauvegarder la distance pour une utilisation
// ultérieure pour l'atténuation
float dist = length(L);
L /= dist;
// Calculer le vecteur de vue et le vecteur à mi-chemin
float3 V = normalize(viewPos - input.modelPos);
float3 H = normalize(V + L);
// Calculer la couleur de lumière atténuée.
float3 lightColor = omniColor * max(1 - dist*invOmniRad,0);
// Calculer les facteurs diffus et spéculaire
float diffFactor = max(dot(N, L),0);
float specFactor = pow(max(dot(N,H),0), specExponent);
// Calculer les couleurs effectives de lumière
float3 diffColor = lightColor*diffFactor + ambientLightColor;
float3 specColor = lightColor*specFactor;
// Additionner les couleurs. Notez que HLSL dispose d'un système de
// "swizzling" très flexible qui nous permet d'accéder à une portion
// d'un vecteur comme si c'était un "membre" du vecteur
float4 result = matDiff; // RGB et opacité de la carte diffuse
result.rgb *= diffColor; // moduler par l'éclairage diffus+ambiant
result.rgb += matSpec.rgb*specColor; // ajouter la spéculaire, ignorant l'alpha de la carte
// La moduler par la constante et produire
return result*constantColor;
}Listing 10.14Pixel shader pour l’éclairage par pixel d’une seule omni plus ambiant
Bien sûr, plusieurs des valeurs nécessaires dans ce calcul pourraient être calculées dans le vertex shader, et nous pourrions utiliser les résultats interpolés dans le pixel shader. C’est généralement un gain de performances car nous supposons que la plupart de nos triangles remplissent plus d’un ou deux pixels, de sorte que le nombre de pixels à remplir est significativement plus grand que le nombre de vertices à ombrager. Cependant, une analyse précise peut être compliquée car le nombre de vertices et de pixels n’est pas le seul facteur ; le nombre d’unités d’exécution disponibles pour l’ombrage de vertices et de pixels est également important. De plus, sur certains matériels, un pool d’unités d’exécution génériques est partagé entre l’ombrage de vertices et de pixels. Il peut également y avoir des implications de performance pour l’augmentation du nombre de valeurs interpolées. Néanmoins, diviser le travail pour faire plus de calculs par vertex est une accélération sur la plupart des plateformes et dans la plupart des situations. Les Listings 10.15 et 10.16 montrent une façon dont nous pourrions déplacer le travail vers le vertex shader.
// Entrées du maillage.
struct Input {
float4 pos : POSITION; // position dans l'espace modèle
float3 normal : NORMAL; // normale de vertex dans l'espace modèle
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
};
// Sortie du vertex shader
struct Output {
float4 clipPos : POSITION; // position en espace de découpe
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
float3 normal : TEXCOORD1; // normale de vertex dans l'espace modèle
float3 L : TEXCOORD2; // vecteur vers la lumière
float3 H : TEXCOORD3; // vecteur à mi-chemin
float3 lightColor : TEXCOORD4; // couleur de lumière + facteur d'atténuation
};
// Matrice de transformation modèle->découpe.
uniform float4x4 modelToClip;
// Position de la lumière omni, dans l'espace MODÈLE
uniform float3 omniPos;
// Réciproque du rayon de la lumière omni. (La lumière décroîtra
// linéairement jusqu'à zéro à ce rayon). Notez qu'il est courant de
// ranger cela dans la composante w de la position, pour réduire le
// nombre de constantes, car chaque constante prend généralement un
// emplacement de vecteur 4D complet.
uniform float invOmniRad;
// Couleur de la lumière omni non atténuée
uniform float3 omniColor;
// Position de vue, dans l'espace MODÈLE
uniform float3 viewPos;
// Le corps de notre vertex shader
Output main(Input input) {
Output output;
// Transformer la position du vertex vers l'espace de découpe.
output.clipPos = mul(input.pos, modelToClip);
// Calculer le vecteur vers la lumière
float3 L = omniPos - input.pos;
// Le normaliser, et sauvegarder la distance pour une utilisation
// ultérieure pour l'atténuation
float dist = length(L);
output.L = L / dist;
// Calculer le vecteur de vue et à mi-chemin.
float3 V = normalize(viewPos - input.pos);
output.H = normalize(V + output.L);
// Calculer le facteur d'atténuation. Notez que nous ne ramenons PAS
// à zéro ici, nous le ferons dans le pixel shader. C'est important
// au cas où la décroissance atteint zéro au milieu d'un grand polygone.
float attenFactor = 1 - dist*invOmniRad;
output.lightColor = omniColor * attenFactor;
// Transmettre les autres entrées de vertex sans modification
output.normal = input.normal;
output.uv = input.uv;
return output;
}Listing 10.15Vertex shader alternatif pour l’éclairage par pixel d’une seule omni plus ambiant
Maintenant, le pixel shader a moins de travail à faire. Selon le compilateur DirectX 10 FXC, le pixel shader du Listing 10.16 se compile en environ 25 emplacements d’instructions, contre 33 emplacements d’instructions pour le Listing 10.14.
// Entrées interpolées depuis le vertex shader.
struct Input {
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
float3 normal : TEXCOORD1; // normale de vertex dans l'espace modèle
float3 L : TEXCOORD2; // vecteur vers la lumière
float3 H : TEXCOORD3; // vecteur à mi-chemin
float3 lightColor : TEXCOORD4; // couleur de lumière + facteur d'atténuation
};
// Une constante globale RGB et opacité
uniform float4 constantColor;
// Couleur de lumière ambiante constante
uniform float3 ambientLightColor;
// Brillance du matériau (exposant de Phong)
uniform float specExponent;
// Échantillonneurs de cartes diffuse et spéculaire. Notez que nous
// supposons que les cartes diffuse et spéculaire utilisent les mêmes
// coordonnées UV
sampler2D diffuseMap;
sampler2D specularMap;
// Corps du pixel shader
float4 main(Input input): COLOR {
// Récupérer les texels pour obtenir les couleurs du matériau
float4 matDiff = tex2D(diffuseMap, input.uv);
float4 matSpec = tex2D(specularMap, input.uv);
// Normaliser les vecteurs interpolés
float3 N = normalize(input.normal);
float3 L = normalize(input.L);
float3 H = normalize(input.H);
// Calculer les facteurs diffus et spéculaire
float diffFactor = max(dot(N, L),0);
float specFactor = pow(max(dot(N,H),0), specExponent);
// Ramener la couleur de lumière (Notez que ce max est appliqué
// composante par composante)
float3 lightColor = max(input.lightColor,0);
// Calculer les couleurs effectives de lumière
float3 diffColor = lightColor*diffFactor + ambientLightColor;
float3 specColor = lightColor*specFactor;
// Additionner les couleurs. Notez que HLSL dispose d'un système de
// "swizzling" très flexible
float4 result = matDiff; // RGB et opacité de la carte diffuse
result.rgb *= diffColor; // moduler par l'éclairage diffus+ambiant
result.rgb += matSpec.rgb*specColor; // ajouter la spéculaire, ignorant l'alpha de la carte
// La moduler par la constante et produire
return result*constantColor;
}Listing 10.16Pixel shader alternatif pour l’éclairage par pixel d’une seule omni plus ambiant
Enfin, nous présentons une dernière variation sur cet exemple. Notez que dans le pixel shader précédent, le Listing 10.16, le code ne suppose pas que l’éclairage se déroule dans un espace de coordonnées particulier. Nous avons effectué les calculs d’éclairage dans l’espace modèle, mais il est également courant de le faire dans l’espace caméra. L’avantage est que nous n’avons pas besoin de renvoyer les constantes de shader pour les données d’éclairage pour chaque objet rendu, comme nous le faisons lorsque ces valeurs sont spécifiées dans l’espace de modélisation (qui variera pour chaque objet). Le Listing 10.17 est un vertex shader qui illustre cette technique.
// Entrées du maillage.
struct Input {
float4 pos : POSITION; // position dans l'espace modèle
float3 normal : NORMAL; // normale de vertex dans l'espace modèle
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
};
// Sortie du vertex shader
struct Output {
float4 clipPos : POSITION; // position en espace de découpe
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
float3 normal : TEXCOORD1; // normale de vertex dans l'espace caméra
float3 L : TEXCOORD2; // vecteur vers la lumière dans l'espace caméra
float3 H : TEXCOORD3; // vecteur à mi-chemin dans l'espace caméra
float3 lightColor : TEXCOORD4; // couleur de lumière + facteur d'atténuation
};
// Matrice de transformation modèle->vue. (La matrice "modelview")
uniform float4x4 modelToView;
// Matrice de découpe. (La matrice "projection").
uniform float4x4 viewToClip;
// Position de la lumière omni, dans l'espace VUE, et réciproque de
// la décroissance dans la composante w
uniform float4 omniPosAndInvRad;
// Couleur de la lumière omni non atténuée
uniform float3 omniColor;
// Le corps de notre vertex shader
Output main(Input input) {
Output output;
// Transformer la position du vertex vers l'espace de vue.
float4 vPos = mul(input.pos, modelToView);
// Et vers l'espace de découpe. Notez que la matrice de découpe
// a souvent une structure simple qui peut être exploitée
// et le nombre d'opérations vectorielles peut être réduit.
output.clipPos = mul(vPos, viewToClip);
// Transformer la normale vers l'espace caméra. Nous "promouvons" la normale
// en float4 en mettant w à 0, donc elle ne recevra aucune translation
output.normal = mul(float4(input.normal,0), modelToView);
// Calculer le vecteur vers la lumière
float3 L = omniPosAndInvRad.xyz - vPos;
// Le normaliser, et sauvegarder la distance pour une utilisation
// ultérieure pour l'atténuation
float dist = length(L);
output.L = L / dist;
// Calculer le vecteur de vue et à mi-chemin.
// Notez que la position de vue est l'origine,
// dans l'espace de vue, par définition
float3 V = normalize(-vPos);
output.H = normalize(V + output.L);
// Calculer le facteur d'atténuation. Notez que nous ne ramenons PAS
// à zéro ici, nous le ferons dans le pixel shader. C'est important
// au cas où la décroissance atteint zéro au milieu d'un grand polygone.
float attenFactor = 1 - dist*omniPosAndInvRad.w;
output.lightColor = omniColor * attenFactor;
// Transmettre les UV sans modification
output.uv = input.uv;
return output;
}Listing 10.17 Vertex shader pour l’éclairage par pixel d’une seule omni plus ambiant, calculé dans l’espace caméra
L’espace mondial (« espace droit ») est une option attrayante pour les calculs d’éclairage dans de nombreuses circonstances car les cartes d’environnement cubiques d’ombres ou les sondes lumineuses sont généralement rendues dans cette orientation ; il a également l’avantage que nous n’avons pas besoin de renvoyer les constantes de shader liées à l’éclairage en raison du changement du référentiel de modèle pour chaque objet.
10.11.3Ombrage de Gouraud
Même le matériel moderne modeste a largement la capacité pour l’ombrage de Phong ; en effet, les exemples précédents sont des shaders relativement peu coûteux. Cependant, il est très instructif de considérer comment implémenter l’ombrage de Gouraud. Même si les résultats sont inférieurs à l’ombrage de Phong, et que l’ombrage de Gouraud exclut le bump mapping, l’ombrage de Gouraud peut encore être utile sur PC pour émuler les résultats d’autres matériels.
Le Listing 10.18 est un vertex shader qui effectue les mêmes calculs d’éclairage que ceux démontrés dans la Section 10.11.2, sauf qu’ils sont effectués au niveau du vertex. Comparez ce code de shader à l’Équation (10.15).
// Entrées du maillage.
struct Input {
float4 pos : POSITION; // position dans l'espace modèle
float3 normal : NORMAL; // normale de vertex dans l'espace modèle
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
};
// Sortie du vertex shader
struct Output {
float4 clipPos : POSITION; // position en espace de découpe
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
float3 diffColor : TEXCOORD1; // RGB d'éclairage diffus
float3 specColor : TEXCOORD2; // RGB d'éclairage spéculaire
};
// Matrice de transformation modèle->découpe.
uniform float4x4 modelToClip;
// Position de la lumière omni, dans l'espace MODÈLE, et réciproque de
// la décroissance dans la composante w
uniform float4 omniPosAndInvRad;
// Couleur de la lumière omni non atténuée
uniform float3 omniColor;
// Couleur de lumière ambiante constante
uniform float3 ambientLightColor;
// Position de vue, dans l'espace MODÈLE
uniform float3 viewPos;
// Brillance du matériau (exposant de Phong)
uniform float specExponent;
// Le corps de notre vertex shader
Output main(Input input) {
Output output;
// Transformer la position du vertex vers l'espace de découpe.
output.clipPos = mul(input.pos, modelToClip);
// Calculer le vecteur vers la lumière
float L = omniPosAndInvRad.xyz - input.pos;
// Le normaliser, et sauvegarder la distance pour une utilisation
// ultérieure pour l'atténuation
float dist = length(L);
L /= dist;
// Calculer le vecteur de vue et à mi-chemin
float3 V = normalize(viewPos - input.pos);
float3 H = normalize(V + L);
// Calculer la couleur de lumière atténuée.
float3 lightColor = omniColor * max(1 - dist*omniPosAndInvRad.w,0);
// Calculer les facteurs diffus et spéculaire
float diffFactor = max(dot(input.normal, L),0);
float specFactor = pow(max(dot(input.normal,H),0), specExponent);
// Calculer les couleurs effectives de lumière
output.diffColor = lightColor*diffFactor + ambientLightColor;
output.specColor = lightColor*specFactor;
// Transmettre les coordonnées UV fournies sans modification
output.uv = input.uv;
return output;
}Listing 10.18Vertex shader pour l’ombrage de Gouraud d’une seule omni plus ambiant
Maintenant, le pixel shader (Listing 10.19) prend simplement les résultats d’éclairage et les module par les couleurs diffuse et spéculaire du matériau, à partir des cartes de texture.
// Entrées interpolées depuis le vertex shader.
struct Input {
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
float3 diffColor : TEXCOORD1; // RGB d'éclairage diffus
float3 specColor : TEXCOORD2; // RGB d'éclairage spéculaire
};
// Une constante globale RGB et opacité
uniform float4 constantColor;
// Échantillonneurs de cartes diffuse et spéculaire. Notez que nous
// supposons que les cartes diffuse et spéculaire sont mappées de la même
// façon, et utilisent donc les mêmes coordonnées UV
sampler2D diffuseMap;
sampler2D specularMap;
// Corps du pixel shader
float4 main(Input input): COLOR {
// Récupérer les texels pour obtenir les couleurs du matériau
float4 materialDiff = tex2D(diffuseMap, input.uv);
float4 materialSpec = tex2D(specularMap, input.uv);
// Additionner les couleurs. Notez que HLSL dispose d'un système de
// "swizzling" très flexible qui nous permet d'accéder à une portion
// d'un vecteur comme si c'était un "membre" du vecteur
float4 result = materialDiff; // RGB *et* opacité de la carte diffuse
result.rgb *= input.diffColor; // moduler par l'éclairage diffus+ambiant
result.rgb +=
materialSpec.rgb*input.specColor; // ajouter la spéculaire, ignorer l'alpha de la carte
// Moduler par la constante et produire
return result*constantColor;
}Listing 10.19Pixel shader pour l’ombrage de Gouraud pour tout environnement d’éclairage
Comme le sous-titre du Listing 10.19 l’indique, ce pixel shader ne dépend pas du nombre de lumières, ni même du modèle d’éclairage, car tous les calculs d’éclairage sont effectués dans le vertex shader. Le Listing 10.20 montre un vertex shader qui pourrait être utilisé avec ce même pixel shader, mais il implémente un environnement d’éclairage différent : ambiant plus trois lumières directionnelles. C’est un environnement d’éclairage très utile dans les éditeurs et les outils, car il est facile de créer un ensemble d’éclairage qui fonctionne raisonnablement bien pour pratiquement n’importe quel objet (bien que nous l’utiliserions généralement avec l’ombrage par pixel).
// Entrées du maillage.
struct Input {
float4 pos : POSITION; // position dans l'espace modèle
float3 normal : NORMAL; // normale de vertex dans l'espace modèle
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
};
// Sortie du vertex shader
struct Output {
float4 clipPos : POSITION; // position en espace de découpe
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
float3 diffColor : TEXCOORD1; // RGB d'éclairage diffus
float3 specColor : TEXCOORD2; // RGB d'éclairage spéculaire
};
// Matrice de transformation modèle->découpe.
uniform float4x4 modelToClip;
// Trois directions de lumière (dans l'espace MODÈLE). Elles pointent
// dans la direction opposée à celle où la lumière brille.
uniform float3 lightDir[3];
// Trois couleurs RGB de lumière
uniform float3 lightColor[3];
// Couleur de lumière ambiante constante
uniform float3 ambientLightColor;
// Position de vue, dans l'espace MODÈLE
uniform float3 viewPos;
// Brillance du matériau (exposant de Phong)
uniform float specExponent;
// Le corps de notre vertex shader
Output main(Input input) {
Output output;
// Transformer la position du vertex vers l'espace de découpe.
output.clipPos = mul(input.pos, modelToClip);
// Calculer le vecteur V
float3 V = normalize(viewPos - input.pos);
// Effacer les accumulateurs.
output.diffColor = ambientLightColor;
output.specColor = 0;
// Additionner les lumières. Notez que le compilateur est *généralement*
// assez bon pour dérouler les petites boucles comme celle-ci, mais pour
// assurer le code le plus rapide, il est préférable de ne pas dépendre
// du compilateur, et de dérouler la boucle vous-même
for (int i = 0 ; i < 3 ; ++i) {
// Calculer le terme de Lambert et additionner la contribution diffuse
float nDotL = dot(input.normal, lightDir[i]);
output.diffColor += max(nDotL,0) * lightColor[i];
// Calculer le vecteur à mi-chemin
float3 H = normalize(V + lightDir[i]);
// Additionner la contribution spéculaire
float nDotH = dot(input.normal,H);
float s = pow(max(nDotH,0), specExponent);
output.specColor += s*lightColor[i];
}
// Transmettre les coordonnées UV fournies sans modification
output.uv = input.uv;
return output;
}Listing 10.20Vertex shader pour l’ombrage de Gouraud, utilisant l’ambiant constant plus trois lumières directionnelles
10.11.4Placage de relief
Ensuite, regardons un exemple de normal mapping. Nous effectuerons l’éclairage dans l’espace tangent, et nous resterons avec l’environnement d’éclairage d’une seule lumière omni plus ambiant constant pour rendre les exemples plus faciles à comparer. Dans le vertex shader (Listing 10.21), nous synthétisons la binormale à partir de la normale et du tangent. Ensuite, nous utilisons les trois vecteurs de base pour faire pivoter L et H vers l’espace tangent, après les avoir d’abord calculés comme d’habitude dans l’espace modèle. Notez l’utilisation des trois produits scalaires, ce qui est équivalent à la multiplication par la transposée de la matrice. Nous effectuons également les calculs d’atténuation dans le vertex shader, passant la couleur de lumière atténuée non ramenée, comme nous l’avons fait dans les exemples précédents.
// Entrées du maillage.
struct Input {
float4 pos : POSITION; // position dans l'espace modèle
float3 normal : NORMAL; // normale de vertex dans l'espace modèle
float4 tangentDet : TANGENT; // tangent dans l'espace modèle, det dans w
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
};
// Sortie du vertex shader
struct Output {
float4 clipPos : POSITION; // position en espace de découpe
float2 uv : TEXCOORD0; // coordonnées de texture pour toutes les cartes
float3 L : TEXCOORD1; // vecteur vers la lumière, dans l'espace TANGENT
float3 H : TEXCOORD2; // vecteur à mi-chemin, dans l'espace TANGENT
float3 lightColor : TEXCOORD3; // couleur de lumière et facteur d'atténuation
};
// Matrice de transformation modèle->découpe.
uniform float4x4 modelToClip;
// Position de la lumière omni, dans l'espace MODÈLE, et réciproque de
// la décroissance dans la composante w
uniform float4 omniPosAndInvRad;
// Couleur de la lumière omni non atténuée
uniform float3 omniColor;
// Position de vue, dans l'espace MODÈLE
uniform float3 viewPos;
// Le corps de notre vertex shader
Output main(Input input) {
Output output;
// Transformer la position du vertex vers l'espace de découpe.
output.clipPos = mul(input.pos, modelToClip);
// Calculer le vecteur vers la lumière (dans l'espace modèle)
float3 L_model = omniPosAndInvRad.xyz - input.pos.xyz;
// Le normaliser, et sauvegarder la distance pour une utilisation
// ultérieure pour l'atténuation
float dist = length(L_model);
float3 L_model_norm = L_model / dist;
// Calculer le vecteur de vue et à mi-chemin
float3 V_model = normalize(viewPos - input.pos);
float3 H_model = normalize(V_model + L_model_norm);
// Reconstruire le troisième vecteur de base
float3 binormal =
cross(input.normal, input.tangentDet.xyz) * input.tangentDet.w;
// Faire pivoter les vecteurs liés à l'éclairage vers l'espace tangent
output.L.x = dot(L_model, input.tangentDet.xyz);
output.L.y = dot(L_model, binormal);
output.L.z = dot(L_model, input.normal);
output.H.x = dot(H_model, input.tangentDet.xyz);
output.H.y = dot(H_model, binormal);
output.H.z = dot(H_model, input.normal);
// Calculer la couleur NON RAMENÉE + facteur d'atténuation.
float attenFactor = 1 - dist*omniPosAndInvRad.w;
output.lightColor = omniColor * attenFactor;
// Transmettre les coordonnées de mappage sans modification
output.uv = input.uv;
return output;
}Listing 10.21Vertex shader pour l’éclairage omni d’un objet avec normal mapping, avec l’éclairage effectué dans l’espace tangent
Le pixel shader (Listing 10.22) est assez compact, car la plupart du travail de préparation a été effectuée dans le vertex shader. Nous décodons la normale et normalisons les vecteurs L et H interpolés. Ensuite, nous effectuons l’équation d’éclairage Blinn-Phong, comme dans les autres exemples.
// Entrées interpolées depuis le vertex shader.
struct Input {
float2 uv : TEXCOORD0; // coordonnées de texture pour toutes les cartes
float3 L : TEXCOORD1; // vecteur vers la lumière, dans l'espace TANGENT
float3 H : TEXCOORD2; // vecteur à mi-chemin, dans l'espace TANGENT
float3 lightColor : TEXCOORD3; // couleur de lumière + facteur d'atténuation
};
// Une constante globale RGB et opacité
uniform float4 constantColor;
// Couleur de lumière ambiante constante
uniform float3 ambientLightColor;
// Brillance du matériau (exposant de Phong)
uniform float specExponent;
// Échantillonneurs de cartes diffuse, spéculaire et de normales
sampler2D diffuseMap;
sampler2D specularMap;
sampler2D normalMap;
// Corps du pixel shader
float4 main(Input input): COLOR {
// Récupérer les texels pour obtenir les couleurs du matériau
float4 matDiff = tex2D(diffuseMap, input.uv);
float4 matSpec = tex2D(specularMap, input.uv);
// Décoder la normale dans l'espace tangent
float3 N = tex2D(normalMap, input.uv).rgb * 2 - 1;
// Normaliser les vecteurs d'éclairage interpolés
float3 L = normalize(input.L);
float3 H = normalize(input.H);
// Calculer les facteurs diffus et spéculaire
float diffFactor = max(dot(N, L),0);
float specFactor = pow(max(dot(N,H),0), specExponent);
// Ramener la couleur de lumière et l'atténuation
float3 lightColor = max(input.lightColor,0);
// Calculer les couleurs effectives de lumière
float3 diffColor = lightColor*diffFactor + ambientLightColor;
float3 specColor = lightColor*specFactor;
// Additionner les couleurs.
float4 result = matDiff; // RGB et opacité de la carte diffuse
result.rgb *= diffColor; // moduler par l'éclairage diffus+ambiant
result.rgb += matSpec.rgb*specColor; // ajouter la spéculaire, ignorer l'alpha de la carte
// Moduler par la constante et produire
return result*constantColor;
}Listing 10.22Pixel shader pour l’éclairage omni d’un objet avec normal mapping, avec l’éclairage effectué dans l’espace tangent
10.11.5Maillage skinné
Voici maintenant quelques exemples de rendu squelettique. Tout le skinning se passe dans les vertex shaders, donc nous n’aurons pas besoin de montrer de pixel shaders ici ; les vertex shaders présentés ici peuvent être utilisés avec les pixel shaders donnés précédemment. Ce n’est pas inhabituel : la géométrie skinnée et non skinnée peut généralement partager le même pixel shader. Nous donnons deux exemples. Le premier exemple (Listing 10.23) illustre l’éclairage par pixel de notre configuration omni + ambiant. Nous effectuerons tout l’éclairage dans le pixel shader (Listing 10.14), afin de nous concentrer sur le skinning, qui est ce qui est nouveau.
// Entrées du maillage.
struct Input {
float4 pos : POSITION; // position dans l'espace modèle (pose de liaison)
float3 normal : NORMAL; // normale de vertex dans l'espace modèle (idem)
byte4 bones : BLENDINDICES; // Indices d'os. Les entrées inutilisées sont 0
float4 weight : BLENDWEIGHT; // Poids de mélange. Les entrées inutilisées sont 0
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
};
// Sortie du vertex shader.
struct Output {
float4 clipPos : POSITION; // position en espace de découpe (pour la rastérisation)
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
float3 normal : TEXCOORD1; // normale de vertex dans l'espace modèle
float3 modelPos : TEXCOORD2; // position dans l'espace modèle (pour l'éclairage)
};
// Matrice de transformation modèle->découpe.
uniform float4x4 modelToClip;
// Déclarer un nombre maximum arbitraire d'os.
#define MAX_BONES 40
// Tableau de matrices "pose de liaison -> pose actuelle" pour chaque os.
// Ce sont des matrices 4x3, que nous interprétons comme des matrices 4x4 avec la
// rangée la plus à droite supposée être [0,0,0,1]. Notez que nous supposons
// que column_major est le stockage par défaut --- ce qui signifie que chaque colonne
// est stockée dans un registre 4D. Ainsi chaque matrice occupe 3 registres.
uniform float4x3 boneMatrix[MAX_BONES];
// Le corps de notre vertex shader
Output main(Input input) {
Output output;
// Générer une matrice mélangée. Notez que nous mélangeons toujours 4 os,
// même si la plupart des vertex en utilisent moins. Selon le matériel,
// il peut être plus rapide d'utiliser une logique conditionnelle pour
// contourner ce calcul supplémentaire, ou de simplement effectuer tous les
// calculs (qui peuvent facilement être planifiés par l'assembleur pour
// masquer toute latence d'instruction).
float4x3 blendedMat =
boneMatrix[input.bones.x]*input.weight.x
+ boneMatrix[input.bones.y]*input.weight.y
+ boneMatrix[input.bones.z]*input.weight.z
+ boneMatrix[input.bones.w]*input.weight.w;
// Effectuer le skinning pour transformer la position et la normale
// de leur position en pose de liaison vers la position
// de la pose actuelle. Notez la multiplication de matrices
// [1x3] = [1x4] x [4x3]
output.modelPos = mul(input.pos, blendedMat);
output.normal = mul(float4(input.normal,0), blendedMat);
output.normal = normalize(output.normal);
// Transformer la position du vertex en espace de découpe.
output.clipPos = mul(float4(output.modelPos,1), modelToClip);
// Passer les UV tels quels
output.uv = input.uv;
return output;
}Listing 10.23Vertex shader pour la géométrie avec skinning
Nous avons déclaré les vertex sous forme de tableau de constantes pour le vertex shader, et l’envoi de toutes ces matrices au matériel peut constituer un goulot d’étranglement significatif pour les performances. Sur certaines plateformes, il existe des moyens plus efficaces de procéder, par exemple en indexant dans un flux de « vertex » auxiliaire.
Voyons maintenant comment utiliser le placage de relief sur un maillage avec skinning. Le vertex shader du Listing 10.24 pourrait être utilisé avec le pixel shader du Listing 10.22.
// Entrées du maillage.
struct Input {
float4 pos : POSITION; // position dans l'espace modèle (pose de liaison)
float3 normal : NORMAL; // normale de vertex dans l'espace modèle
float4 tangentDet : TANGENT; // tangente en espace modèle, déterminant dans w
byte4 bones : BLENDINDICES; // Indices d'os. Les entrées inutilisées sont 0
float4 weight : BLENDWEIGHT; // Poids de mélange. Les entrées inutilisées sont 0
float2 uv : TEXCOORD0; // coordonnées de texture pour les cartes diffuse et spéculaire
};
// Sortie du vertex shader
struct Output {
float4 pos : POSITION; // position en espace de découpe
float2 uv : TEXCOORD0; // coordonnées de texture pour toutes les cartes
float3 L : TEXCOORD1; // vecteur vers la lumière, en espace TANGENT
float3 H : TEXCOORD2; // vecteur à mi-chemin, en espace TANGENT
float3 lightColor : TEXCOORD3; // couleur de la lumière + facteur d'atténuation
};
// Matrice de transformation modèle->découpe.
uniform float4x4 modelToClip;
// Tableau de matrices "pose de liaison -> pose actuelle" pour chaque os.
#define MAX_BONES 40
uniform float4x3 boneMatrix[MAX_BONES];
// Position de la lumière omni en espace MODÈLE, et inverse
// du rayon de décroissance dans la composante w
uniform float4 omniPosAndInvRad;
// Couleur de la lumière omni non atténuée
uniform float3 omniColor;
// Position de la vue, en espace MODÈLE
uniform float3 viewPos;
// Le corps de notre vertex shader
Output main(Input input) {
Output output;
// Générer une matrice mélangée.
float4x3 blendedMat =
boneMatrix[input.bones.x]*input.weight.x
+ boneMatrix[input.bones.y]*input.weight.y
+ boneMatrix[input.bones.z]*input.weight.z
+ boneMatrix[input.bones.w]*input.weight.w;
// Effectuer le skinning pour obtenir les valeurs en espace modèle,
// dans la pose actuelle
float3 pos = mul(input.pos, blendedMat);
float3 normal = normalize(mul(float4(input.normal,0), blendedMat));
float3 tangent =
normalize(mul(float4(input.tangentDet.xyz,0), blendedMat));
// Transformer la position du vertex en espace de découpe.
output.pos = mul(float4(pos,1), modelToClip);
// Calculer le vecteur vers la lumière (en espace modèle)
float3 L_model = omniPosAndInvRad.xyz - pos;
// Le normaliser et conserver la distance pour l'atténuation
float dist = length(L_model);
float3 L_model_norm = L_model / dist;
// Calculer le vecteur de vue et le vecteur à mi-chemin
float3 V_model = normalize(viewPos - pos);
float3 H_model = normalize(V_model + L_model_norm);
// Reconstruire le troisième vecteur de base
float3 binormal = cross(normal, tangent) * input.tangentDet.w;
// Faire pivoter les vecteurs liés à l'éclairage vers l'espace tangent
output.L.x = dot(L_model, tangent);
output.L.y = dot(L_model, binormal);
output.L.z = dot(L_model, normal);
output.H.x = dot(H_model, tangent);
output.H.y = dot(H_model, binormal);
output.H.z = dot(H_model, normal);
// Calculer la couleur NON CLAMPÉE + le facteur d'atténuation.
float attenFactor = 1 - dist*omniPosAndInvRad.w;
output.lightColor = omniColor * attenFactor;
// Passer les coordonnées de mapping sans modification
output.uv = input.uv;
return output;
}Listing 10.24Vertex shader pour la géométrie avec skinning et placage de relief
10.12Lectures complémentaires
L’étudiant souhaitant acquérir de bonnes bases en infographie est encouragé à diversifier ses lectures sur tout le spectre, des principes théoriques de la « tour d’ivoire » à une extrémité, jusqu’aux ouvrages du type « voici du code source fonctionnant sur une plateforme particulière et qui sera probablement obsolète dans 5 ans » à l’autre. Nous avons tenté ici de sélectionner, parmi le vaste corpus de la littérature graphique, quelques sources particulièrement recommandées.
Fundamentals of Computer Graphics [23] de Shirley offre un solide panorama introductif des fondamentaux. Écrit par l’un des pères fondateurs du domaine, il est utilisé comme manuel de première année pour les cours d’infographie dans de nombreuses universités, et constitue notre recommandation pour ceux qui débutent leur formation en infographie.
L’opus magnum de Glassner Principles of Digital Image Synthesis [8] se distingue parmi les travaux théoriques par son envergure encyclopédique et sa pertinence durable depuis sa première publication en 1995. Pour un lecteur souhaitant comprendre « comment la synthèse d’images fonctionne vraiment », comme nous l’avons décrit en début de chapitre, ce chef-d’œuvre est une lecture indispensable, même s’il est inexplicablement sous-estimé dans l’industrie du jeu vidéo. Mieux encore, les deux volumes ont récemment été mis à disposition en format électronique gratuitement (légalement). Vous pouvez les trouver sur books.google.com. Un PDF consolidé et corrigé devrait être disponible prochainement.
Physically Based Rendering de Pharr et Humphreys [20] est une excellente façon d’apprendre le cadre théorique rigoureux de l’infographie. Plus court et plus récent que celui de Glassner, cet ouvrage fournit néanmoins une large base théorique des principes de rendu. Bien qu’il s’agisse d’un excellent livre à des fins théoriques, une caractéristique unique de l’ouvrage est le code source d’un lanceur de rayons fonctionnel tissé tout au long du texte, illustrant comment les idées peuvent être mises en œuvre.
Real-Time Rendering [1], d’Akenine-Möller et al., offre un panorama très large des problématiques spécifiques au rendu en temps réel, telles que le matériel de rendu, les programmes de shader et les performances. Ce classique, à sa troisième édition au moment de la rédaction, est une lecture essentielle pour tout étudiant intermédiaire ou avancé s’intéressant à l’infographie en temps réel.
Les documentations des API OpenGL [18] et DirectX [5] sont certainement des sources importantes. Non seulement ce type de matériel de référence est indispensable d’un point de vue pratique, mais une quantité surprenante de connaissances peut être acquise simplement en les parcourant. Presque toute une génération d’utilisateurs OpenGL a grandi avec le « red book » [19].
Les subtilités liées à la radiométrie et aux espaces colorimétriques que nous avons survolées sont expliquées plus en détail par Glassner [8] et aussi par Pharr et Humphreys [20]. Ashdown [2] et Poynton [22] ont rédigé des articles accessibles et disponibles gratuitement.
Exercices
Sur la Nintendo Wii, une résolution de tampon de trame courante est . Cette même résolution est utilisée pour les télévisions 4:3 et 16:9.
(a)Quel est le rapport d’aspect des pixels sur un téléviseur 4:3 ?
(b)Quel est le rapport d’aspect des pixels sur un téléviseur 16:9 ?
En continuant l’exercice précédent, supposons que nous réalisons un jeu coopératif en écran partagé, et que nous attribuons au premier joueur la moitié gauche et au second joueur la moitié droite . Nous souhaitons toujours que le champ de vision horizontal soit de . Supposons que les paramètres système nous indiquent que la console est connectée à un téléviseur 4:3.
(a)Quel est le rapport d’aspect de la fenêtre ?
(b)Quelle doit être la valeur de zoom horizontal ?
(c)Quelle doit être la valeur de zoom vertical ?
(d)Quel est le champ de vision vertical résultant, en degrés ?
(e)Supposons que les plans de découpe avant et arrière soient à 1,0 et 256,0. Quelle est la matrice de découpe, en supposant toutes les conventions OpenGL ?
(f)Et avec les conventions DirectX ?
Répéter les parties (a)–(d) de l’Exercice 2, mais en supposant un téléviseur 16:9.
Pour chaque ensemble de coordonnées UV (a)–(f), faites-le correspondre au quad avec placage de texture dans la Figure 10.43. Le vertex en haut à gauche est numéroté 0, et les vertex sont énumérés dans le sens des aiguilles d’une montre autour du quad.
Figure 10.43Quads avec placage de texture pour l’Exercice 4
Pour chaque entrée (a)–(j) dans le tableau ci-dessous, faites correspondre la couleur diffuse, la couleur spéculaire et l’exposant spéculaire du matériau Blinn-Phong avec la tête flottante inquiétante correspondante dans la Figure 10.44. La scène contient une seule lumière omni blanche. Les couleurs diffuse et spéculaire sont données sous forme de triplets (rouge, vert, bleu).
Diffuse Spéculaire Spéculaire [-6pt] Couleur Couleur Exposant (a) (210,40,50) (0,0,0) 1 (b) (65,55,200) (150,0,0) 16 (c) (65,55,200) (230,230,230) 2 (d) (50,50,100) (210,40,50) 4 (e) (65,55,200) (210,40,50) 2 (f) (65,55,200) (0,0,0) 64 (g) (0,0,0) (210,40,50) 1 (h) (210,40,50) (100,100,100) 64 (i) (210,40,50) (230,230,230) 2 (j) (210,40,50) (65,55,200) 2 
Figure 10.44 Têtes flottantes inquiétantes pour l’Exercice 5
Comment les normales suivantes seraient-elles encodées dans une carte de normales 24 bits avec les conventions habituelles ?
(a) (b) (c) (d) Pour chaque ligne (a)–(d) du tableau ci-dessous, décodez le texel de la carte de normales pour obtenir la normale de surface en espace tangent. Déterminez la binormale à partir de la normale de vertex, de la tangente et du déterminant. Calculez ensuite les coordonnées en espace modèle de la normale de surface par texel.
Texel RGB de la Normale de Tangente de Déterminant [-6pt] carte de normales vertex vertex (indicateur miroir) (a) (128,255,128) [0.707,0.707,0.000] 1 (b) (106,155,250) [1.000,0.000,0.000] -1 (c) (128,218,218) [0.000,0.447,-0.894] 1 (d) (233,58,145) [0.986,0.046,-0.161] -1
Il y a trop d’effets spéciaux dans tous ces films aujourd’hui.
— Steven Spielberg (1946–)
Références
[1] Tomas Akenine-Möller, Eric Haines et Natty Hoffman. Real-Time Rendering, troisième édition. Natick, MA: A K Peters, Ltd., 2008. http://www.realtimerendering.com/.
[2] Ian Ashdown. « Photometry and Radiometry: A Tour Guide for Computer Graphics Enthusiasts. » Adapté de Radiosity: A Programmer’s Perspective, Ian Ashdown, Wiley, 1994. http://www.helios32.com/.
[3] Ronen Barzel. « Lighting Controls for Computer Cinematography. » J. Graph. Tools 2 (1997), 1–20.
[4] James F. Blinn. « Models of Light Reflection for Computer Synthesized Pictures. » SIGGRAPH Comput. Graph. 11:2 (1977), 192–198.
[5] « DirectX Developer Center. » http://msdn.microsoft.com/en-us/directx/default.aspx.
[6] Frederick Fisher et Andrew Woo. « versus Specular Highlights. » In Graphics Gems IV, édité par Paul S. Heckbert. San Diego: Academic Press Professional, 1994.
[7] Andrew S. Glassner. « Maintaining Winged-Edge Models. » In Graphics Gems II, édité par James Arvo. San Diego: Academic Press Professional, 1991.
[8] Andrew S Glassner. Principles of Digital Image Synthesis. San Francisco: Morgan Kaufmann Publishers, 1995. http://glassner.com/andrew/writing/books/podis.htm.
[9] H. Gouraud. « Continuous Shading of Curved Surfaces. » IEEE Transactions on Computers 20 (1971), 623–629.
[10] Ned Greene. « Environment Mapping and Other Applications of World Projections. » IEEE Comput. Graph. Appl. 6 (1986), 21–29.
[11] Roy Hall. Illumination and Color in Computer Generated Imagery. New York: Springer-Verlag New York, 1989.
[12] Paul S. Heckbert. « What Are the Coordinates of a Pixel? » In Graphics Gems, édité par Andrew S. Glassner, pp. 246–248. San Diego: Academic Press Professional, 1990. http://www.graphicsgems.org/.
[13] James T. Kajiya. « The Rendering Equation. » In SIGGRAPH ’86: Proceedings of the 13th Annual Conference on Computer Graphics and Interactive Techniques, pp. 143–150. New York: ACM, 1986.
[14] Eric Lengyel. Mathematics for 3D Game Programming and Computer Graphics, deuxième édition. Boston: Charles River Media, 2004. http://www.terathon.com/books/mathgames2.html.
[15] T. M. MacRobert. Spherical Harmonics, deuxième édition. New York: Dover Publications, 1948.
[16] Jason Mitchell, Gary McTaggart et Chris Green. « Shading in Valve’s Source Engine. » In ACM SIGGRAPH 2006 Courses, SIGGRAPH ’06, pp. 129–142. New York: ACM, 2006. http://www.valvesoftware.com/publications.html.
[17] Addy Ngan, Frédo Durand et Wojciech Matusik. « Experimental Validation of Analytical BRDF Models. » In ACM SIGGRAPH 2004 Sketches, SIGGRAPH ’04, pp. 90–. New York: ACM, 2004.
[18] « OpenGL Software Development Kit. » http://www.opengl.org/sdk/docs/man/.
[19] OpenGL Architecture Review Board, Shreiner, Dave, Woo, Mason, Neider, Jackie et Davis, Tom. OpenGL(R) Programming Guide: The Official Guide to Learning OpenGL(R), Version 2.1. Reading, MA: Addison-Wesley Professional, 2007. http://www.opengl.org/documentation/red_book/.
[20] Matt Pharr et Greg Humphreys. Physically Based Rendering: From Theory to Implementation. San Francisco: Morgan Kaufmann Publishers, 2004. http://www.pbrt.org/.
[21] Bui Tuong Phong. « Illumination for Computer Generated Pictures. » Commun. ACM 18:6 (1975), 311–317.
[22] Charles Poynton. « Frequently Asked Questions about Color. » http://www.poynton.com/ColorFAQ.html.
[23] Peter Shirley. Fundamentals of Computer Graphics. Natick, MA: A K Peters, Ltd., 2002. http://www.cs.utah.edu/ shirley/books/.
[24] Peter-Pike Sloan. « Stupid Spherical Harmonics (SH) Tricks. » Rapport technique, Microsoft Corporation, 2008. http://www.ppsloan.org/publications.
[25] Alvy Ray Smith. « A Pixel Is Not a Little Square, a Pixel Is Not a Little Square, a Pixel Is Not a Little Square! (And a Voxel is Not a Little Cube.) » Rapport technique, Technical Memo 6, Microsoft Research, 1995. http://alvyray.com/memos/6_pixel.pdf.
[26] Paul S. Strauss. « A Realistic Lighting Model for Computer Animators. » IEEE Comput. Graph. Appl. 10:6 (1990), 56–64.
[27] David R. Warn. « Lighting Controls for Synthetic Images. » In Proceedings of the 10th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH ’83, pp. 13–21. New York: ACM, 1983.
En réalité, presque tout le monde approxime la vraie physique de la lumière en utilisant l’ optique géométrique, plus simple.
En parlant d’équipement, il existe également de nombreux phénomènes qui se produisent dans un appareil photo mais pas dans l’œil, ou résultant du stockage d’une image sur film. Ces effets sont eux aussi souvent simulés pour donner l’impression que l’animation a été filmée.
En réalité, ce n’est probablement pas une bonne idée de penser aux pixels comme ayant un « centre », car ils ne sont pas vraiment des blocs rectangulaires de couleur, mais sont plutôt interprétés au mieux comme des échantillons ponctuels infiniment petits dans un signal continu. La question de quel modèle mental est le meilleur est incroyablement importante \cite_need_fixup{smith:pixel-not-a-square, heckbert:coordinates-of-pixel}, et est intimement liée au processus par lequel les pixels sont combinés pour reconstruire une image. Sur les CRT, les pixels n’étaient définitivement pas de petits rectangles, mais sur les appareils d’affichage modernes comme les moniteurs LCD, « bloc rectangulaire de couleur » n’est pas une si mauvaise description du processus de reconstruction. Néanmoins, que les pixels soient des rectangles ou des échantillons ponctuels, nous pourrions ne pas envoyer un seul rayon à travers le centre de chaque pixel, mais plutôt envoyer plusieurs rayons (« échantillons ») selon un motif intelligent, et les moyenner de manière intelligente.
D’autres questions pertinentes qui devraient influencer la couleur que nous écrivons dans le tampon de trame pourraient être posées concernant les conditions générales de visualisation, mais ces problématiques n’ont aucun rapport avec la lumière entrant dans notre œil ; elles affectent plutôt notre perception de cette lumière.
Rappelons que et sont les lettres grecques minuscules oméga et lambda, respectivement.
Ici et ailleurs, nous utilisons le mot « couleur » d’une manière qui est techniquement un peu approximative, mais qui est acceptable sous les hypothèses sur la lumière et la couleur faites dans la plupart des systèmes graphiques.
Les fabricants de moniteurs ont dû être ravis de constater que les gens percevaient une qualité supérieure dans ces moniteurs « grand écran ». Les tailles de moniteurs sont généralement mesurées en diagonale, mais les coûts sont plus directement liés au nombre de pixels, qui est proportionnel à la surface, et non à la longueur de la diagonale. Ainsi, un moniteur 16:9 avec le même nombre de pixels qu’un 4:3 aura une diagonale plus longue, perçue comme un moniteur « plus grand ». Nous ne savons pas si la prolifération de moniteurs avec des formats encore plus larges est davantage alimentée par les forces du marché ou les forces du marketing.
Même si cela cause une détresse extrême aux vidéophiles de voir une image ainsi maltraitée, apparemment certains propriétaires de téléviseurs préfèrent une image étirée aux barres noires, qui leur donnent l’impression de ne pas rentabiliser leur nouveau téléviseur hors de prix.
Le « film » est devant le point focal plutôt que derrière comme dans un vrai appareil photo, mais ce fait n’est pas significatif pour cette discussion.
Ce n’est pas strictement nécessaire dans certains cas, mais en pratique nous utilisons presque toujours des vecteurs unitaires.
Cette technique d’interpolation des normales de vertex est également parfois appelée de façon confusante ombrage de Phong, à ne pas confondre avec le modèle de Phong pour la réflexion spéculaire.
Prononcé « guh-ROH ».
C’est une leçon très importante. Les graphismes réalistes peuvent être importants pour les joueurs hardcore, mais pour un public plus général ils ne sont pas aussi importants que nous le croyions autrefois. La récente montée en popularité des jeux Facebook souligne encore ce point.
Malheureusement, certaines personnes appellent cette carte la gloss map (carte de brillance), ce qui crée une confusion quant à la propriété de matériau exactement spécifiée par texel.
Le terme radiométrique correct est éclairement énergétique, qui mesure la puissance rayonnante reçue par unité de surface.
Prononcé « fre-NEL ».
« Gobo » est l’abréviation de « go between » (intermédiaire), et « cookie » est l’abréviation de « cucoloris ». La subtile différence technique entre ces termes issus du monde du théâtre n’est pas pertinente pour l’imagerie de synthèse.
Vous pourrez également entendre le terme rigging, mais ce terme peut impliquer un éventail plus large de tâches. Par exemple, un rigger crée souvent un appareil supplémentaire qui aide à l’animation mais n’est pas utilisé directement pour le rendu.
Eh bien, c’est le processus idéal. En réalité, des modifications du maillage sont souvent nécessaires après que le maillage a été rigué. Le maillage peut nécessiter des ajustements pour mieux se plier, bien qu’un modélisateur de personnages expérimenté puisse anticiper les besoins du rigging. Bien sûr, des modifications sont souvent nécessaires à des fins esthétiques sans aucun rapport avec le rigging — surtout si des dirigeants ou des groupes de discussion sont impliqués.
Et pour les rendus haute résolution destinés à l’art de la boîte. Certaines personnes utilisent également des modèles haute résolution pour faire des captures d’écran mensongères de séquences « en jeu », un peu comme le hamburger que vous obtenez dans un fast-food ne ressemble pas à celui sur la photo du menu.
Nous n’avons pas encore tous accès au MegaTexturing d’id Tech 5.
Le terme « bitangente » est probablement plus correct ; mais il est moins couramment utilisé.
Et la plupart des programmeurs ont aussi beaucoup en commun, même si nous détestons peut-être l’admettre.
Par exemple, le langage de shading RenderMan ne possède pas cette propriété.
Retour en haut
Mécanique 1 : Cinématique Linéaire et Calcul >>